In my understanding, once a challenge hits the network (4,608 times per day), farmers have something like 30 seconds to compute proofs from those plot files which pass the filter. A given plot file will pass the filter once every 2-3 hours on average (albeit unpredictably), and computing a proof only involves reading several small parts of the file (interspersed throughout).
I think it’s fun to imagine future data storage technologies for this workload. HDDs are obviously overkill, with their perpetual read/write capabilities. They only make sense for now because they’re general-purpose devices we’ve got around already, and in this early going, we all need to reserve the option to delete and redo our plots for various reasons.
Ideas:
Flash is on a trajectory to flip HDD $/TB in the back half of this decade. No-brainer.
Mask ROM. Currently it’s totally infeasible (economically) to manufacture one-off semiconductor wafers. There’s been little incentive to make it so at scale, though, so that could change.
Optical jukebox. 30 seconds is plenty of time to fetch and read from a disc, but there’s a delicate tradeoff between how many plots you keep on a disc vs. what fraction of discs your robots have to fetch for each challenge. Not obvious whether this scales
Optical memory crystals if the density of optical storage increases sufficiently, then it becomes a solid-state device without the robots-grabbing-discs part.
DNA data storage, the helix is 2nm in diameter and completely stable in liquid solution => unbelievable density. The tech for targeted random access + sequencing in the 30s timeframe isn’t totally visible right now, but that’s just a matter of catching up to our own cells which do that constantly.
These all have considerable R&D behind them right now, and so appear totally feasible to me looking 1-2 decades out (not saying any one is probable). What have I missed even further out? What’s going on on the quantum physics side, for example?
It takes about 90 seconds to do an end-to-end seek of an LTO tape. It’s conceivable that faster tape drives could be developed to get it into the 30 second range needed for Chia harvesting. However, most R&D on tapes is focused on increasing storage density, not access speed, so I wouldn’t expect this to happen soon.
I’m more curious about the near term… when will the first 20tb drive be introduced? does anyone have a graph of when various drive sizes were introduced? Like first 1tb, first 2tb, first 4tb, and so on?
There is technically a 20tb drive already?!?
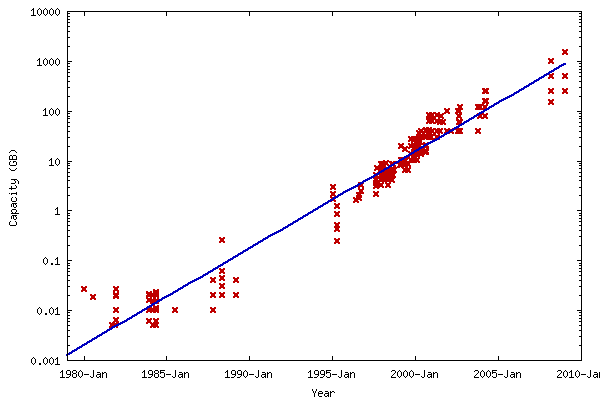
Wikipedia has a graph
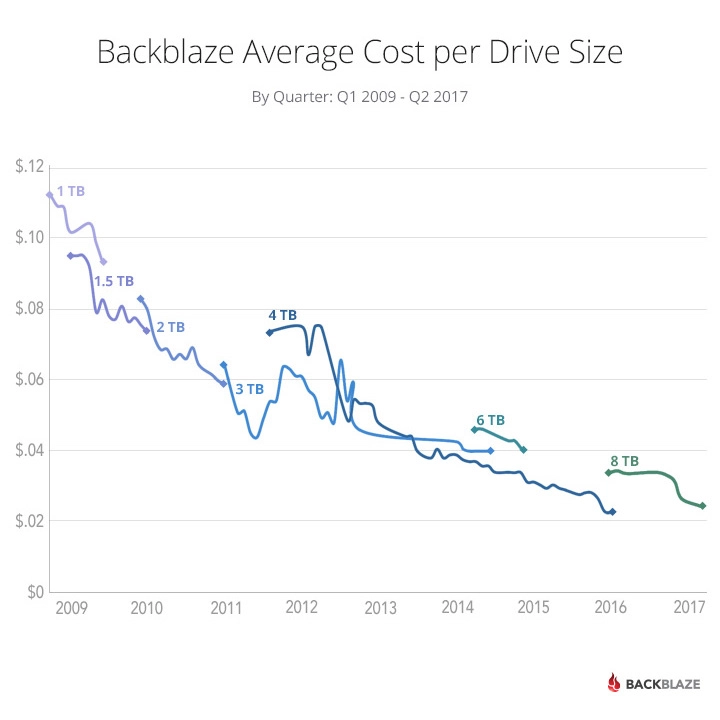
Backblaze has cost per drive size (but it stops at 8tb!!)
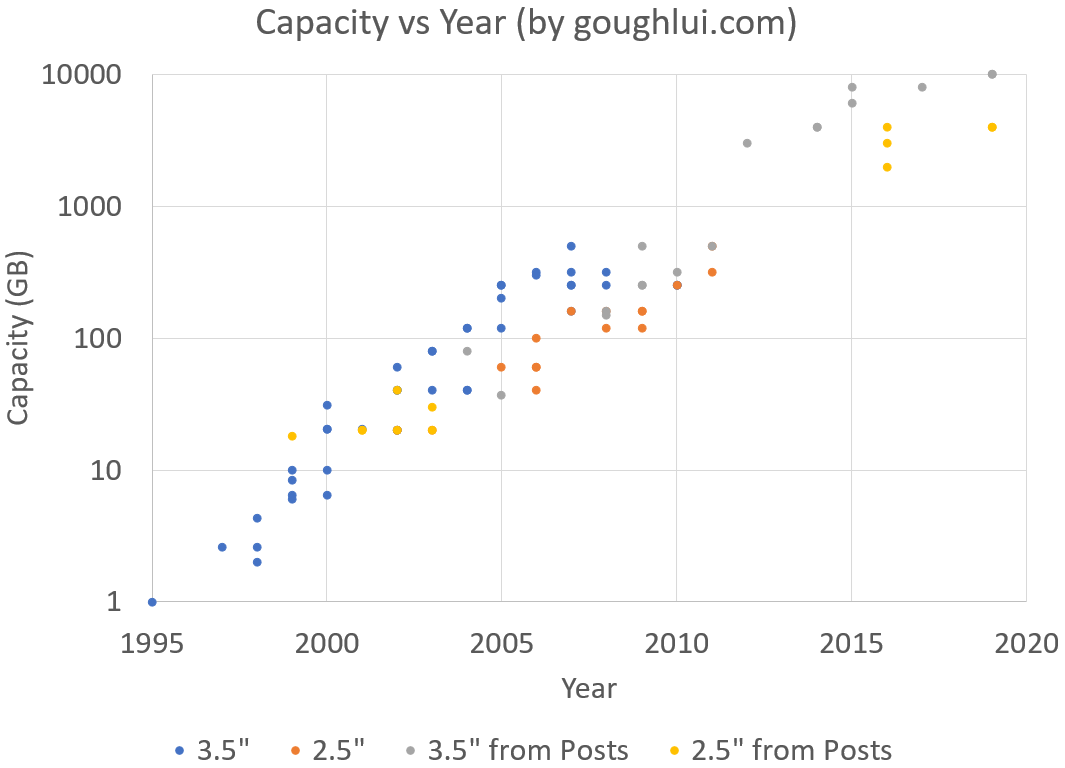
While I do know my selection of drives hardly represents the “leading” capacity for any given time and thus makes for a poor fuzzy representation of capacity over time, when plotted on a semi-log graph, it seems that capacity is increasing nearly exponentially, with a ten-fold increase in storage every five years. Does this mean we will see a 50TB hard drive by 2025? I somehow don’t think so … but there’s a slim possibility!
Rumor has it 30 second timeout was specifically chosen to exclude LTO farms, which doesn’t make sense (apart from that it’s a sensible setting for many other reasons) since they aren’t growing in capacity that much and there’s only one serious vendor left, the ridiculously expensive IBM.
Yeah jeez, I barely thought about spinny rust hard drives for the last decade since SSDs became mature. Tape drives? Good lord. I assume there’s a market but it’s gotta be highly specialized.
We are on the verge of major change comparable to previous advances decade ago with giant magnetoresitance and perpendicular magnetic recording that enabled multi-terabyte drives. 1TB was introduced in 2008 by HGST. In fact we are on this verge ever since! WD demonstrated HAMR heat assisted recording in 2013. Seagate hoped to quickly skip to HAMR already back then, but introduced SMR shingled recording as a stopgap to their slipping schedule. But it’s finally here, 20TB is out since January 2021. While Western Digital HGST moved on to MAMR microwave assisted magnetic recording. How they want to milk is rather conservative for what the technology offers, but 50TB is on the roadmap for 2026 when a major update to Heat-Dot technology will happen offering 100TB by 2030. So a quintuple within a decade that’s been announced since a decade!
If you’re storing more than ~150 TB and don’t mind access times measured in minutes, tape is still the cheapest option. It’s also the only commercially available storage medium with a decent chance of being readable after 30 years on a shelf, though the best practice is to transfer data to fresh tapes every 10 years.
Used LTO-5 (1.5 TB uncompressed capacity) drives and changers show up on eBay around $150 fairly often. The people that buy these things new replace them every five years, even though they’re built to last much longer than that.
It’s also serious coming home to this chunk of history. Basically what mainframes were about and do all day. So much that IBM just introduced another special SORTL instruction and DFSORT coprocessor facility just for sorting (and many other special processors for crypto things, mainframe is basically what Chia plotting would be if it moved on to ASICs like Bitcoin). The manual is larger than Knuth’s Sorting and Searching and extremely uptied BDSM for dinosaurs, fascinating in this way. What Chia does with sorting and bucketing is how memory limited computers operated writing out chunks on the tape and so on. Difference is people were optimizing to avoid seeking and random access obviously, but also doing thing in cultured way. Tape is very fragile and offers maybe like 100 cycles so our SSD wearout fears are nothing compared. And people engineered around that for decades years to great results!
I suspect even implementation of Chia in Fortran would be gainful. Scientific computing people who made the Python ecosystem like Ondrej Certik, creator of SymPy, and several I know of NumPy have came back to Fortran for some reasons I don’t fully understand (though there were major improvements in modern Fortran versions).
I wonder how green Chia could really be compared to Visa that runs on z/TPF. What we are building with our disks after all is just transaction and settlement network after all, we can’t price in bank branch offices and so on in our comparisons and calculations like Bitcoin people insist on.