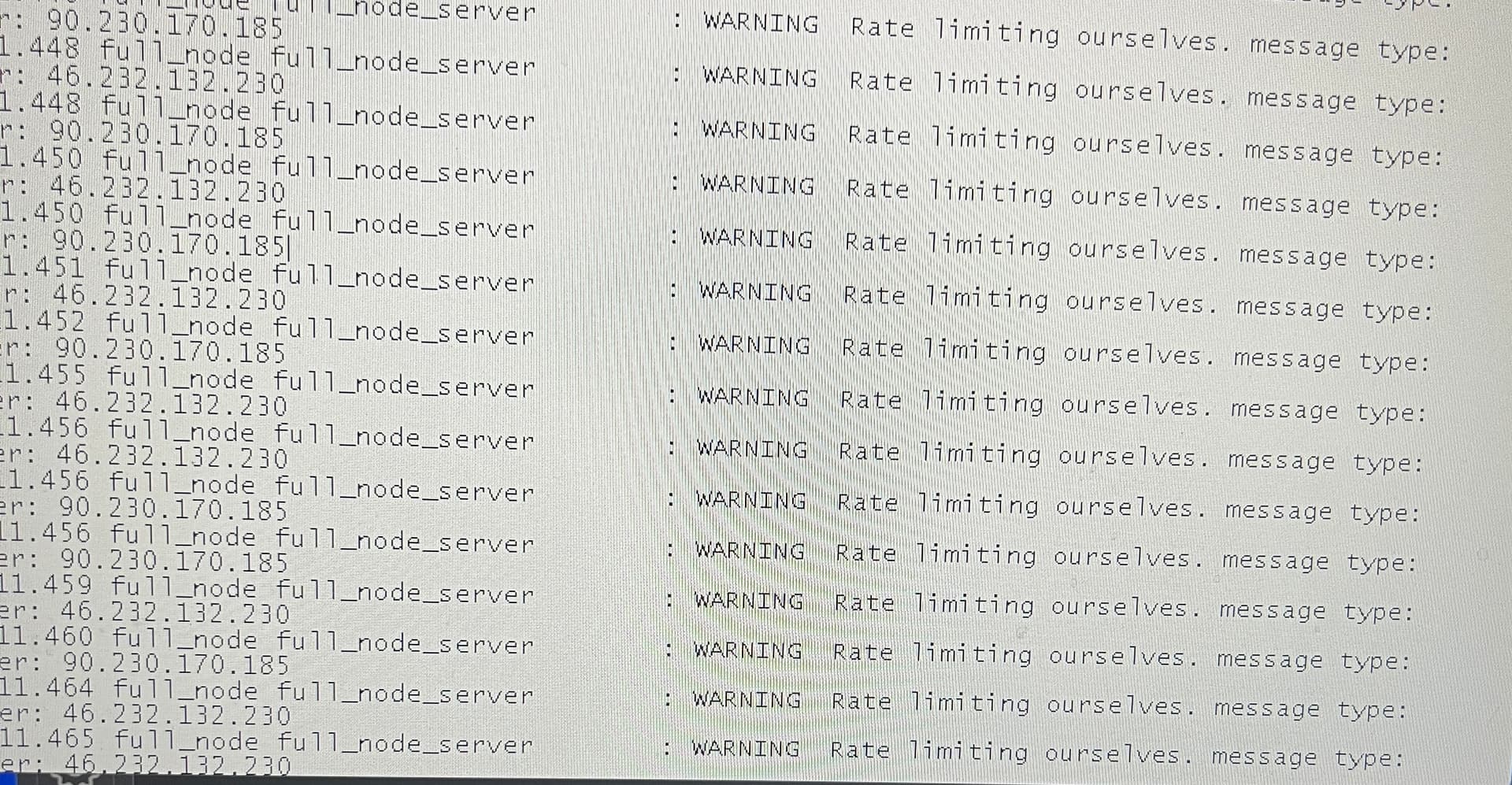
I have no idea for this. Chia windows 11, 1.6.0 gives this warning : Rate limiting ourselves while the gui copies the plot to the disk drive and the chia server sync stops, full node color turns to red. After copying the plot file it begins to sync?
So I went back to 1.4.0 to test whether this is a bug or not.
Were you ever on 1.5.1?
I was on 1.6.0
Post must be at least 20 characters
You said you got this error with 1.6.0, but were you ever on 1.5.1 with the same machine?
Yes I was on 1.5.1 before with the same machine. What is your point?
Just asking, to get a base. I have 1.6.0 running on several boxes so far so good.
This problem occurs if you use the classic k32 plotting from windows gui of 1.6.0. If you do not plot, its OK chia runs smoothly.
I use madmax plotmanager
Well, the first thing is that those are only WARNINGs, so really no harm there. The code runs as it was intended to run, or at least as it was coded to run.
I wrote on Chia’s github after the very first dust storm, that the lack of rate control was one of the two things that was causing all those problems. So, one year later, and looks like rate control is there, so this is a good thing to have. However, the rate control is only as good as it is designed and coded. Two things that need to be considered is aggressiveness of it and the resources limits.
I assume that those “1.45X” numbers there are milliseconds when the rate control was kicking in. As those lines are spit out basically around every other millisecond, the rate control is just too aggressive.
The resources limit in this case is related to peer count. Apparently, there is no lower limit and all peers are dropped - thus chia goes out of sync. Basically, to stay in sync, only one node is needed, so it should be a bottom limit (e.g., 2-4 nodes). Also, the nodes should be dropped based on how much data the node received from them (starting from the lowest). This way, whatever the lower limit is, it would most likely have good performing nodes.
To further help with that rate control, when the lower limit is met, the next step should not be further dropping nodes, but rather putting all but one into “suspended” state. This way only one node would be used, but there would be few more nodes around, in case that node goes down.
The relevant code is here (around line 398 as of today) - chia-blockchain/ws_connection.py at main · Chia-Network/chia-blockchain · GitHub
It is not really encouraging that the line 407 is a “TODO” line. It implies that Chia knows that the code doesn’t work well, but so far didn’t bother to address the problem.
So, it may be good to create a ticket on Chia github page about it.
Lastly, in your case three things potentially may be tripping that rate limiting - CPU usage, sqlite performance or network (Ethernet). As you stated, this happens only when the file is being copied. So, either you hammer sqlite drive (maybe not likely), or the copy process goes over the Ethernet, and kills the bandwidth. If the problem is with Bandwidth, then dumping those files to an USB drive, and moving it around should fix this problem. (The code above would suggest that the network was killed, but I didn’t follow the code to confirm it.)
2 Likes
Thank you for your comment. It seems that you have a deep knowledge about chia.
To solve this problem, I made a simple test. I went back to chia 1.4.0 and started 6 more plots. Windows is on SSD drive. Ram is 32 GB. İntel i7 2.9 GHz 10 th gen. which is a rather fast PC. Plots are prepared on 2 TB samsung evo 970 plus.
The result is: Nothing happened. Farming and harvesting did not stop while the plots were copied to 8 TB WD red disk.
So I am sure this is a bug of 1.6.0. ??
Yes.
I don’t really have a deep knowledge about chia, really. Although, thanks for that. ![]()
Your test kind of suggest that the rate control is a new functionality. There are two reasons that it works when rate control is not there. The first is that it is really too aggressive, and is almost instantaneously dropping all peers, not really giving them a chance to do anything. The second reason is that obviously the guy that implemented it doesn’t really understand network timings, and made those timeouts really short. This is basically preventing those “remining” peers from getting a chance to slog through the choked line.
Maybe you have read the interview with the guy that implemented the very first dust storm. The gist of what he said is that Chia basically doesn’t do much if any testing and didn’t bother to address dust storm functionality. Basically, this is also what we see with v1.6.0 - some rough code without much thought behind that, and zero testing. So, potentially, you are the very first person that tripped over that.
It would be good, if you could create a ticket on Chia’s github, to let them know that the code is there, but nothing works.
By the way, your box is capable of producing k32 plots in about 40 mins or so, given that you bump up your RAM to 128 GB. So, depending how many plots you still intend to do, maybe you could bump your RAM. Also, even if you just get another 32 GB, and use something like Primo Cache, that will give you a decent boost, and offload ~50% of your t2 writes. All that is when using MM. I think that there is really no point of using Chia’s plotter, as it is rather worthless.
1 Like
@ksevin If I understand this correctly, the trigger is a combination of Chia 1.6.0 while using the GUI’s legacy plotter. You wrote “k32”, but it would probably happen for other “k” sizes.
It might be hard to find anyone to duplicate the issue, because I suspect that the number of people on version 1.6.0 + also using the legacy plotter will be few. And factor in that they would be using this forum and having read your issue or have an account to report their own, similar, issue, lowers the chances of others chiming in. Plus factor in that they would catch the syncing issue, only if they are monitoring their GUI at the time.
If you are more comfortable using the GUI for plotting, then consider choosing madmax via the GUI.
It will be faster, and will probably sidestep the bug.
Report the bug on github, if you are so inclined. But using madmax will at least end your syncing issue.
If, by chance, a madmax GUI session does the same thing, then that would be revealing and should also be included in a github bug report.
1 Like
I was aware about the exact time of stopping of farming with the help of farmr.exe
There’s an open issue here about this. No feedback or resolution as of yet though. [Bug] Tons of "WARNING Rate limiting ourselves. message type: respond_peers" messages in log · Issue #13132 · Chia-Network/chia-blockchain · GitHub
Before 1.5 this used to be a “debug” level warning so it wouldn’t normally appear, but probably was always an issue.
Can you try banning those IPs? I’m not sure if these are abusive peers, or just how the P2P software is behaving. Maybe some of your system resources get overloaded when moving plots, causing sync and peer issues?
1 Like
P2P is a non-preferential protocol, so rather unlikely that there would be so many deficient peers connected, unless that is some sort of attack. The second thing is that my understanding is that those messages are only happening when there is the final plot transfer, what implies that this is the trigger.
Good find of that github issue. Not too many examples are there, but whatever is there, the drop rate there is rather in seconds, where here is in mostly in single digit milliseconds (massive trigger, abrupt peer purge).
So, as you said, it is either resource overload, or some bad interaction between the Chia plotter and the full node, when the plotter is run using GUI.
Maybe some Task Manager screenshots would provide a bit more info.
A more complete screenshot of the error messages would help too. The message_type is not visible in the photo and this is important. The GitHub issue is talking about respond_peers, and this was also brought up here in WARNING Rate limiting ourselves. message type: respond_peers,
@ksevin What is the message_type for these errors?
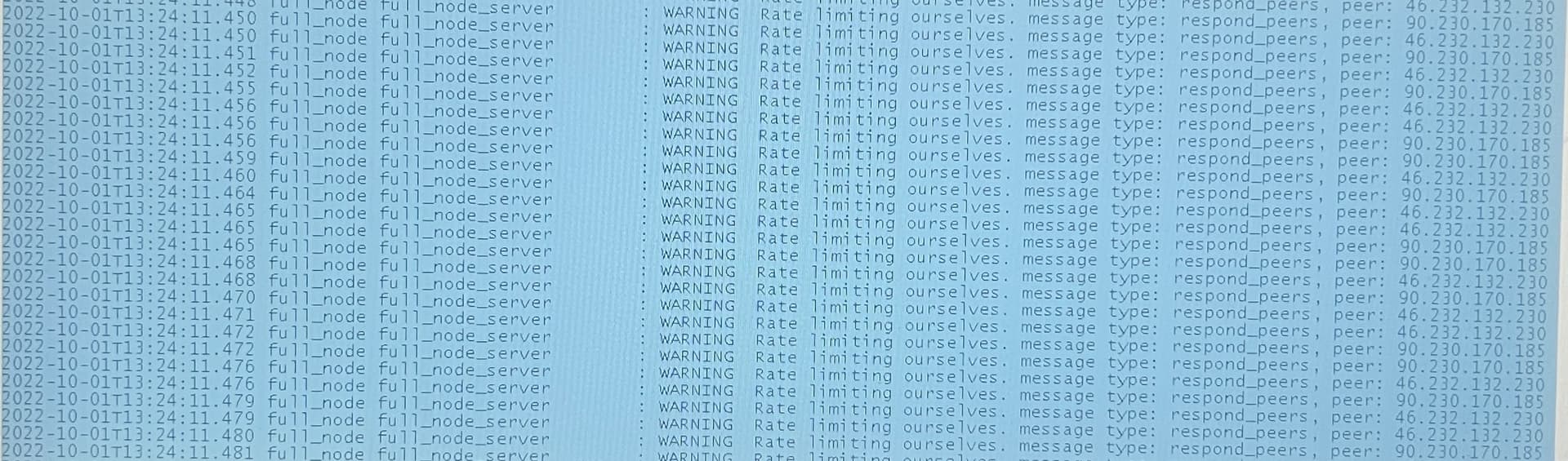
Thanks! The respond_peers message is the same one mentioned in the GitHub issue. It could be related to your problem, but it sounds like the frequency and timing may be different in your case.
Are you only seeing these messages when plots of copying, or do they occur at any time?
I have been getting those same messages since 09/22/2022, and I have not done any plotting since then (or earlier than then).
Windows 10 Home
Chia 1.6.0. (might have been 1.5.0 on 09/22/2022 – not sure). But I am on 1.6.0 now, and still getting those messages, and I am not plotting.