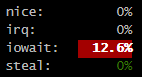
If you aren’t seeing any WARNING log messages with the following, it is a good sign that things aren’t being too slow:
Looking up qualities on {filename} took: {time_taken}. This should be below 5 seconds to minimize risk of losing rewards."
This log message is an indication that reading plots to submit as a proof is too slow. That iowait does seem a bit high, so it is worth keeping an eye on.
On Linux, you might try the following to see if you can pinpoint the slow drive:
Shut down all Chia processes (chia stop all -d)
One disk at a time, while monitoring iowait, initiate a large write dd:
See if any one drive has a slower write speed and/or higher iowait than the others.
If you haven’t already, check the smart data for each drive to look for any obvious failures. To do that, install smartmontools and then run (where /dev/sdX is a disk device on your system):
u havnt given necessary details to help with ideas about ur io wait…
this forums more chia based responses lol…
i don’t think this issue is specific to chia, perhaps configuration?
are u using raid at all or jbod,
is your host OS on a separate drive away from any other operations?
how are all the hard drives attached?
do your hard drives have any sort of cache backing them?
any memomry resources backing your disks? with ram or hardware cache?
theirs a few things i do to keeping it as minimal as possible.
alwayse using separate fast drive for the host os for its main io processes.
while its taskn io happens somewhere els (wielding ZFS for built in ram cache functionality ).
use hard drives hardware cach or at least setup a propor cach for a jbod of plots using mhddfs or raided pool cach.
sumary
pretty much all io wait can be negated with properly placed caches and a balance betwen host io’s processes and tasks.
weather it is a slow drive or wont doesn’t matter.
a single harvesters will consume 16gb of ram… and use it non stop if u give it to them. creating almost no io wait anywhere. harvester wont even need to spin up a disk unless it has to with that much ram.
keep everything starting with ram and building more cached layers so io is synchronous from software to hardware.
ti better achieve processor utilization of its resources
All good information. I did leave out some information, But when asking about an issue that you do not know the cause of, it is difficult to know what information will lead to the answer.
This is a Chia/Forks system running multiple farmers. System has 160gb or ram.
It is a Dell R730 server, Has 16 built in bays which I have populated with a few drives connected directly to the existing raid controller (Dont have the model # handy).
I have an additional external HBA that goes to an external disk array of 8 drives. (I suspect one of these drives to possibly be the culprit.)
The ubuntu OS sits on it own 128gb SSD, This drive is only used for the OS.
The drives connected to the Dell raid controller do have cache, The HBA controller does not.
I am curios about the cache ideas mentioned but I am unfamiliar of other options other that hardware based cache.
does your HBA happen to support IT mode… if so you can flash that and sometimes get better preformance with a software raid.
but im assuming that wont work because you already have a raid setup with plots on it…
you would have to move all plots off than wipe the drives, setup IT mode, than move plots back on to individual disks in I.T. mode.
for plot storage zfs isn’t the best route tho…
but if it is a drive having a hard time… this would also make it extreamly easy to deal with and to know Wich drives causing the error…
there’s really no need to run a raid on plot storage drives.for speed or redundancy… the data it holds can be re created… so its not mission critical stuff.
instead of spinning up every disk just to find a plot (total speed being hurt by a single failing disk)
so its just one disk to spin up to find and read from is plenty fast when connected if drive is healthy
for me. with out writing a book about it…
I use a hypervisor for absolute control of all io…
my host hypervisor runs on a small ssd…
my harvesters run on a separate ssd…
my chia full node on a diffrerent ssd… whole other computer
harvesters increase the entire speed of the farm when utilized, if u have the ram.
auto magicaly creating a large cach for all your disks… I recommend storing all plots on xfs mounted drives, individually mounted, and held together by mhddfs, plenty fast… and perfect if a drive fails it wont bring down tho whole farm to be re raided…
so that way harvester box has only one virtual mount point to deal with as if it was raided… and creates its cache over all those disks…
understanding
io wait can happen when I processor isn’t getting enough space to stretch its legs when getting hit with a workload. think of a dishwasher with 8 hands…hes super fast and efficient… but can still only go as fast as its being given dirty dishes… you want full processor utilization with neer no io delay. some will always be present tho. but you give the dish washer more lanes to utilize so he can run at its best/fastest potential…
setting up hardware or software caches at all points will further reduce delay… think of it as the ability for waiters to be able to stack dishes for the dishwasher… when things are cached the processor has to wait very little time to retrieve all its data, and with only running chia should only need to look for data on disk when u make it far enough to complete the block. when responding to questions. should only need to consult the ram for if it has the correct winning plot. if it does… than spin up the disk.
a simple cach in linux can be placed on a specific folder or mount point. creating a “RAM disk” as the lvl 1 cach… id start with that in your situation… than move to the other stuff I mentioned if it doesn’t go away
This controller is just an HBA, No raid. So IT mode is not a thing.
I am interested in potentially creating an RamDisk cache and started looking into it. Maybe if I get sometime.
I think ultimately I will just simply use the SATA controller on the system and move the two SAS drives to another system. The system does run very smoothly even with that IOwait popping up here and there.