How can you pin each process to one CPU?
1 Like
If you are on Windows you can use Process Lasso
Or if you plot from the commandline you can just use
start /affinity n chia.exe
where n is the core
1 Like
Thankyou!
I use swar plot manager and saw affinity options in there. But how can you make sure that a specific process uses memory from a specific numa node?
Hello, hope everyone is well.
I am fairly new to this, setup and running my Windows 10 GUI plotter and farmer for 1 week only. I have been reading quiet a bit but still confused about a few optimisation options available in Windows 10 GUI interface.
1 - Number of Threads - I see that people say you don’t need more then 4 or 6 threads otherwise its wasted. SO when I choose this value do I choose across the entire parallel plot number or against 1. Example if I am running 7 parallel plots (I have a ryzen 9 16/32) for the 7 plots would I choose a value of 14 OR just put 4 and the application will allocate 4 for each plot?
2 - My potential threshold is my of parallel plots is capped by 32GB of RAM (as I have good CPU and I have 2x2TB NVME.2 SSD drives for temp storage).
Reading around my cap should be 7 parallel plots. BUT I was wondering if I stagger my parallel plots by 90min it is very likely that plot 6 and 7 will commence after plot 1 and 2 have already finished. So wont that release resources for me to use and are just sitting wasted. So potentially with a long enough timeout I could plot 9 or 10 in parallel.
Hope that all makes sense,
I keep seeing people refer to this optimized chia pos, what is that exactly?
This topic:
1 Like
Hey guys, there’s this site that has user contributed hardware plotting benchmarks, if you can find your set up or something similar you might be able to have a good point of reference. https://chiametrix.com/
1 Like
@gladanimal can you give me some feed back brother
My system
3990x… 64 cores128 threads
256 gb ram
(7) ssd total. (3) sabrent rockt 4.0. (4) samsumg 980
Asus trx40 pro s
So as you can see I have plenty of ram.
I am currently running 8 threads per plot. Is the striping and buckets the same thing? If I run the buckets down to 64, even if it speeds up the plotting by 5%, that will give me 5% more plots a day. Right now my limiter is the number of threads I have. I am considering dropping down to 6 threads to gwt more done.
I am running SWAR for plot management.
Any thought would help brother.
Keep in mind: the numbers you are interested for is a TB/day, not single plot time. I think you can test even 4 threads. This will degrade you speed (may be for 15-20%%) but let you to run x2 seedings.
It seems you able to run about 50-60 plots in parallel 
1 Like
anyone have any tweaks for me … i feel as if i am limited by my 4tb ssd performance and my I9 core count
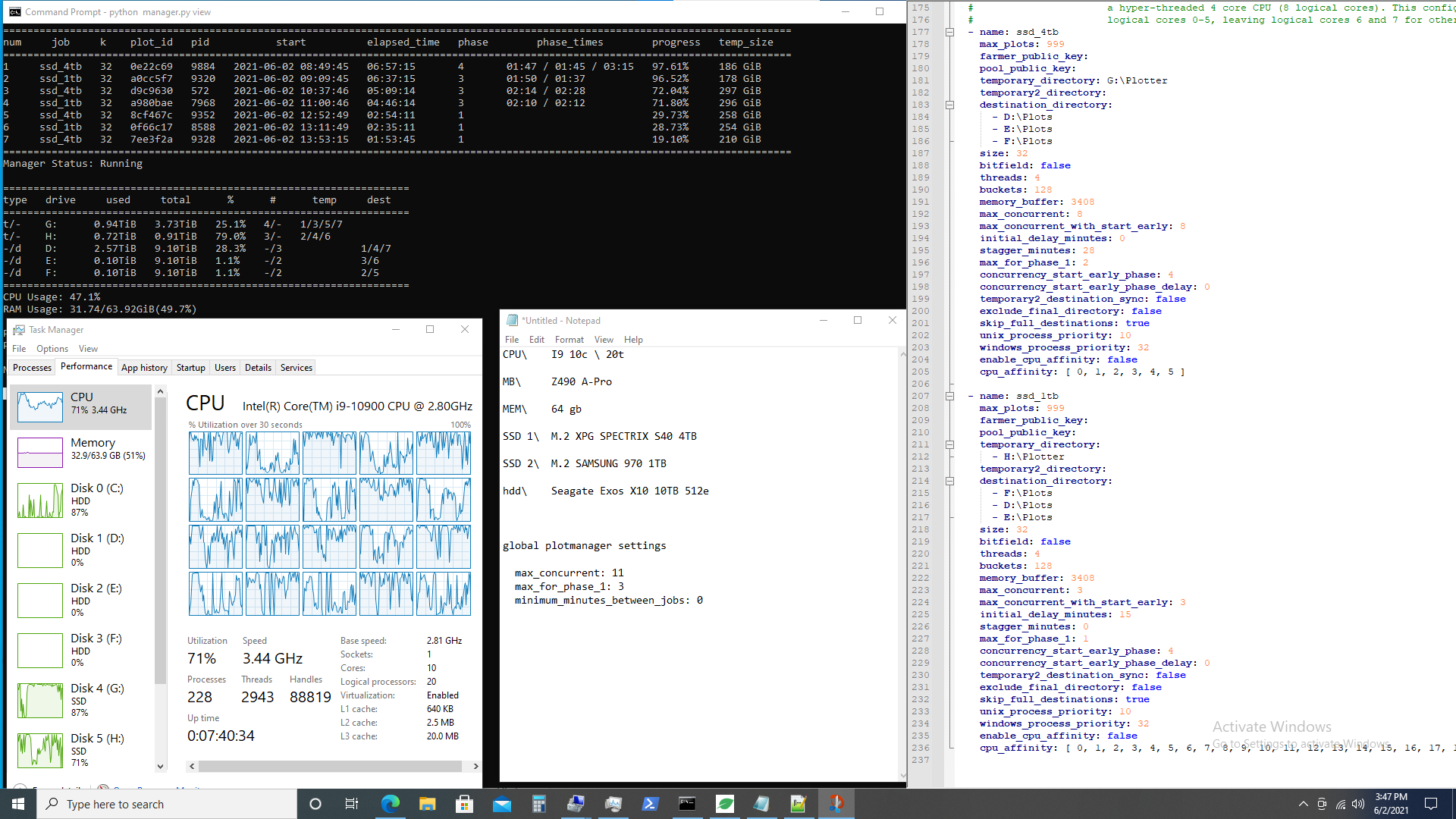
i have 3 hdd running *** edit1
i also have a 1 tb hdd for operating system on win 10 ** edit2
i spent 2 days running single plots on 2t, 4t, and 8t, and i can say general consensus is that 4t is the magic number … i would say you will be limited by transfer bottleneck to your storage drives as the ssd clears out complete plots
1 Like
Let me know how well 64 buckets turned out. I did a mix of 128 on one nvme and 64 on another(WD sn750s) and the 128 was way faster.(drives 64k Allocated format).
It might be the mixture at fault… But haven’t seen a benefit… Actually curious if 256 bucket works.
I get about the same numbers 64 vs 128 buckets, but only when giving 64 a lot more ram, so for me it isn’t worth it.
Regarding Windows.
You can always change the affinity of a running process via way of GUI in the Task Manager’s Detail Tab by selecting Set affinity in the process right-click menu.
To do this scriptable: launch the process with powershell and you’re quite flexible.
Just note, that the process ProcessorAffinity parameter is a bitmask, not the core number.
Made a few scripts that rotate through bitmasks myself. Bit found it eventually overkill and settled for https://github.com/swar/Swar-Chia-Plot-Managerto find optima in parameters regarding thread count and optimal concurrency first.
Assuming you have 2 addressable threads per real core:
- Create initial bitmask:
$bitmask = "0" * ($cores * 2 - $threads) + "1" * $threads
Repeat the following steps as needed:
- Convert to number:
$affinity=[Convert]::ToInt64($bitmask,2) - Set affinity for process:
$plotter=start-process $chiapath -argumentlist $chiaargs;
$plotter.ProcessorAffinity=$affinity; - Rotate bitmask for each new process:
$maskshift=$threads
$bitmask = $bitmask.Substring($maskshift) + $bitmask.Substring(0,$maskshift)
Keeping the $core parameter under the real core count will never assign the remaining cores to plotter threads. So this might be good option, if you want to run the harvester or other tasks more reliably.
why do you have max concurrent 3 and start early 3? Why not just say max concurrent 6? With 4 threads per plot, the only thing that’s limiting you indeed is the cpu cores…
As Intel runs higher frequencies than AMD though, from my experience, that makes up for it. How many plots per day are you pushing out?
You should be able to do between 14-17 with your config.
I would agree memory speed is very important.
I have 2 plotters:
One has 320GB of DDR3 (LR+ECC) running at 1600MHz, 4-Channel, and two e5-2687-v2 CPU.
Plotting a single plot on a 300GB DDR3 RAM disk completes in 6 hours and 5 minutes.
My other plotter has 128GB of DDR4 (ECC) running at 2400MHz 4-Channel, and an e5-1650-v4.
Plotting a single plot on a 100GB-cached-970-Pro(1TB) took 4 hours and 55 minutes.
Both plots were using 6700MB of dedicated RAM and 6 CPU cores, and used the same USB external SSD for final directory.
I realize there are a lot of differences between my two scenarios, but it seems like faster memory outperformed more memory in my case.
1 Like
Some notes:
- An obvious first step should be to add antivirus exception to temp and destination folders. Or simply add it for chia.exe. Antivirus usually takes noticeable amount of resources, no need to have it pay attention to every IO operation in plotting.
- Affinity is mentioned. For approximately 100% of users affinity should be left unassigned. The operating system will move execution of CPU intensive operations around to different cores in order to distribute heating within the CPU. Setting affinitiy (limiting certain cores) may prevent it from doing so efficiently, and will end in unnecessary thermal throttling and hence lower speed than what is reported. Look into affinity (and NUMA) for your OS only if you have multiple physical CPU’s (not just cores and threads).
- I have no idea what the plotting IO pattern is. Depends a lot on access pattern, someone else might be able to say yay or nay on this one: Disabling “Last Access” timestamp in Windows is usually a trick to avoid unwanted IO. (
fsutil behavior set disablelastaccess 1) - Windows does not support TRIM in RAID 0 stripe. I would guess trimming often is beneficial for speed. Trimming never is probably less beneficial.
I found that using any XMP or speeds higher than stock ram speed resulted in instability. And no improvements in speed.
XMP is a mature technology, so if it doesn’t work on your box (instability) that may mean that you have some shoddy mb or RAM.
On the other hand, if you overclock your RAM (speeds higher than stock ram speed), that most likely will result in instability.
Also, if XMP is not improving your speeds, that would imply that your plots are mostly drive bound