Not sure if I’m posting here for answers or just to document my troubleshooting process and ultimately what I find. But here we go.
I have had a nice and stable farm running for months totaling 6030 plots. Those plots are spread over 3 NAS devices and one JBOD. Each NAS has its own harvester and the JBOD is directly connected to the Full Node. Everything ran fine. Then I bought a 14TB USB drive to do some migration for another project and when I was done with it I figured I would add it to the farm. So I connected it to the full node and added the folder to plots. Soon after, I started getting spurts of notifications from chiadog saying “Seeking plots took too long”. I began to look for the issue and in my troubleshooting I found that one of the drives in my JBOD was spitting out errors. Not a lot, but enough for me to notice in the event viewer. So I ordered a replacement. While waiting for the replacement I got another 18TB USB drive to pull the plots from the drive that would be replaced. Then pointed the node to that drive so those plots could continue to be farmed. Now the system is not even looking at the drive with issues. The “Seeking plots” issue continued. I have since replaced the drive and put the plots back and the ploblem is still there. I get “Seeking plots took too long” messages in spurts. Like over a 8 hour period I will get 100 of them and then it runs smooth for hours.
I am suspecting that adding the USB drives to the same harvester as the JBOD is the issue. The harvester needing to jump from one device to the other which happen to be on different interface types is causing a delay. So to test this, I have just removed the USB drives from the plot folder list. I’m going to let it run this way for a couple days. If it runs clean, I know it is the USB drives (the combination of drive/interface types)
FYI, there is no plotting traffic involved in this setup. Just farming/harvesting.
If anyone has any experience in a similar situation, I’m all ears.
One of my drivers was faulty and I got latency error from all drivers. I found the faulty this one. I recovered the plots on an ubuntu machine (windows did not detect the disk). Eventually that disk died and sent under warranty.
For now, 43 external 20 internal total 515 TB drives are connected. No problem.
(windows 10 installed gen3 nvme. b450m. 2200G. 16 GB 3200 mhz ram.)
You have a faulty disk and you need to find it.
“smart” values can give clues. Or you can do a quick surface scan. “hdtune pro” is good at this.
I have received one notification since posting this. But when I look at the logs, it seems that there are many similar notifications but only one tripped the chiadog notification (because it went over the threshold).
When I look closer at the notifications. It seems that when the W: drive is include in a lookup, it is slow. So not all slow lookups are the W: drive but all lookups that also access the W: drive are slow. But the W: drive (which is a stripe set consisting of 3 drives) is not showing any errors in the event log. I will go and see if HDTune will tell me anything that will help.
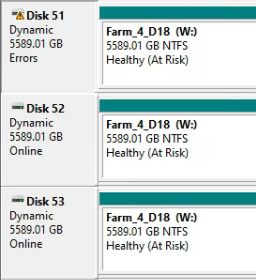
Well, it appears I was right about the W: drive but wrong about it not showing errors. I was about to run HDTune but it just brings up a list of drives with no identifying information of the drives. So I needed to know what drive (out of the 60 drives on the system) to run the test on. So I brought up Disk Manager to get the drive number. That is when I saw this.
On that I can easily see that one of the drives in the W: drive stripe set is showing “Errors”. So, it looks like I found my problem.
While in there, I looked at all the rest of the drives and there are no others showing the Errors status. Still going to run the HDTune to see what it says.
Unfortunately, it does not show information for the drives in the JBOD. This is what the info tab shows for the JBOD drives.
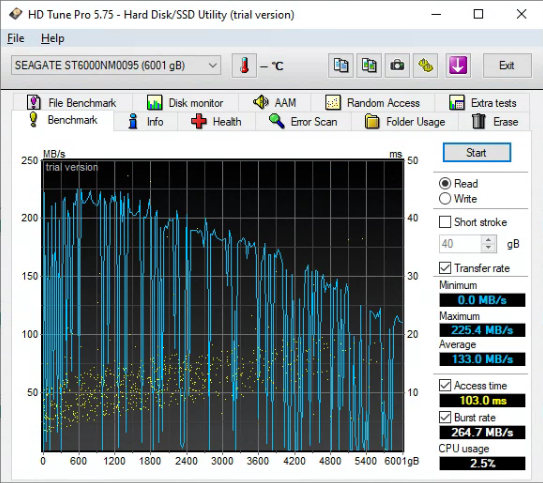
The good thing is that it does list all the drives in order in the dropdown. So I just counted down to find the one I needed. This was the benchmark for the suspected drive.
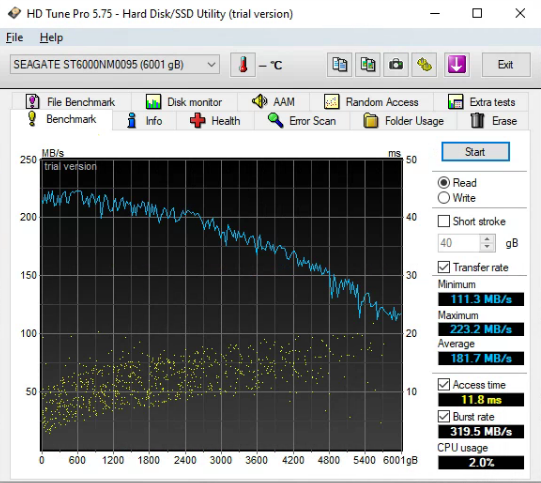
And this is the benchmark for the drive that replaced it.
The drive was so bad that I was not able to copy the plots from it. They appeared to be there when you browsed, but they would not copy. So I lost 165 plots. Oh well. That is why I have them split up in small groups of drives. It will take a couple days to replace but that’s fine. There have been no slow lookups since the W: drive was removed. Looks like the problem is solved.
Just to clarify, the issue of latency in searching for plots was isolated to that one specific drive, correct? It did not affect your overall Chia system or the ‘good’ drives from being able to farm. Right? So if you hadn’t noticed this lookup time error for months, the worse case is that you had one drive that was doing nothing for your farming win potential. But every other drive still had the opportunity to win a Chia block. Right?
Incorrect. The problem with the one drive being bad affected more than just lookups to that drive. The reason is that lets say you have “9 plots were eligible for farming …”. If one of those 9 plots were on the bad drive it would cause a delay. That delay would not only cause problems for that plot but also the other 8 because the delayed lookup would also delay the others in that cycle.
This is why it took me a bit to even identify the problem. Because I was seeing delays for many drives in the logs. I finally noticed that in every timestamp range of issues, it included that one drive among the others. Then I started looking at it.
Ahh. Interesting. Good to know and thanks for sharing. I didn’t see it this way before. So essentially each harvester can only respond in a timeframe that is defined by the slowest drive of all drives it is harvesting. So it is critical to either fix that one drive or simply remove it. Thanks again.
I think what is being said is that the total lookup time taken to look up the plot on the slowest drive will be added to the total time taken to lookup plots on the other drives.
I think that’s pretty obvious, but then the response is provided as a group of lookups for each eligible plot, rather than individually per eligible plot?
I hadn’t really thought about it until you pointed it out. If you grep ‘eligible’ in your debug log file, you’ll see the response time. It appears that this time represents the total time for identifying eligible plots from all plots that that particular harvester (computer) is managing.
‘x plots were eligible for farming’ … ‘Time: y seconds. Total z plots’
That’s the bit I don’t think is being written quite right and it sent me down the wrong path before. If one of them is slow, the total response will be slow, for that particular lookup, if that lookup includes a plot from the slow drive. Right?
This vs if one of them is slow they all are - sounds like all my plots and their lookups will always be slow.
It has been said multiple times. You are confusing yourself. If a set of eligible plots contains a plot on the bad drive, all the lookups in that set will be delayed/slow.
Not sure what you mean by multiple times - I guess people have said it before and I haven’t seen that? I’m not confusing myself at all - was trying to get the context of it. And you just confirmed what I said. All lookups in ‘the set’. So yes that’s it - we agree.
looks like same issue as mine but mine being more severe and stops farming completely.
a single drive in raid array under disk management will show it, but otherwise CHIA doesnt say much. hes lucky it could tell him latency while mine just says host not responding making it look like an internet or port issue. dumb software.
Yes, in the debug log. But you don’t get that information if everything is running smoothly. The way I found the plot location is when they do run slow it tells you “W:/folder/plotname.plt took ** seconds. This should be below 5 seconds ***”.
And right before that message, you will see “5 plots were eligible for farming **”. And it will list out the 5 plots and how long they took. In my case, every time I had an entry (or group of entries) there was always at least one plot in the group on the W: drive. Which turned out to be the drive with the problem. Eliminated the bad drive, problem went away.
Thank you. Yeah, in the last log I didn’t have those lookups over 5 secs, so didn’t see that output. Although, I had some around 2-3 seconds and was thinking that maybe those could be coming from the same USB drive, and was hoping that there is a way to identify those as well.
It would be nice to have a param in config.yaml that would specify when those warnings should hit the log, so we could potentially better tune our farms.