Forgot to mention that. You need to change the one that is under full_node. Although, you did change the correct one. That one with 5 is for wallet, and is rather irrelevant (my take is that it could be just 1 - your full node).
Actually, this may be something that you should look into. I am not sure how you use your RAM, but looks like you may be wasting it (i.e., not using what you have).
I would download PrimoCache and set it up to only cache your blockchain db folder (%userprofile%.chia\mainnet\db). Ideally, I would give it 32-35GB or RAM (a bit more than db). If you are using any RAM drive, I would lower that value to 20-30 GB (whatever you can afford to spare).
Once you are fully synced, I would drop that RAM value to about 10GB, just to see whether your system will be happy with that. If not, add another 10GB, …
Based on what you stated, I believe that you are running your plotter on two NVMes, and not backing it up with any RAM caching (let Win handle it). If that is the case, at least for time being (when trying to sync up), I would go with that 32-35 GB. By letting Win handle your caching duties, it boils down to Win grabbing mostly worthless files produced by your plotter, and being stuffed with those.
Once you will catch up, I would create another caching block, and point it to one of your NVMes (I used MM, so that would be tmp2, but with chia plotter tem1 may have heavier usage - don’t know). That should speed a bit your plotter, and at the same time save some wear on that NVMe.
Actually, this also goes for @Lsherring , as you are also running v1.2.9. Get that PrimoCache, and think about setting it on the top of your blockchain folder (wallet db has not that much traffic, so no point to waste any resources on that one).
At the time that I posted that, of my 64 GB of RAM, I was using approximately ½ of it…
… I was reporting my current status, to exclude low RAM as the culprit for having my syncing problem.
At times, during multiple, parallel plot building, my RAM usage sometimes flirts with 50 GB.
So a 32 GB RAM drive would mean I would have to do less parallel plotting, which is fine, if my overall plot production improves.
However, I have several questions regarding PrimoCache, as well as questions regarding your suggestions pertaining to configuring it. Honestly, I am afraid to add new software into the mix – especially when I have a number of questions.
Considering I have a 16 core, 32 thread CPU, and all NVMe based, I should not be having a syncing issue that needs assistance from other software.
I re-booted computer #1 (the one with the slow syncing issue).
I have zero plots running. I have only the GUI running.
The issue remains, and I am now nearly 2,000 units behind, and still losing ground.
I am syncing, but too slow to keep pace with new new updates.
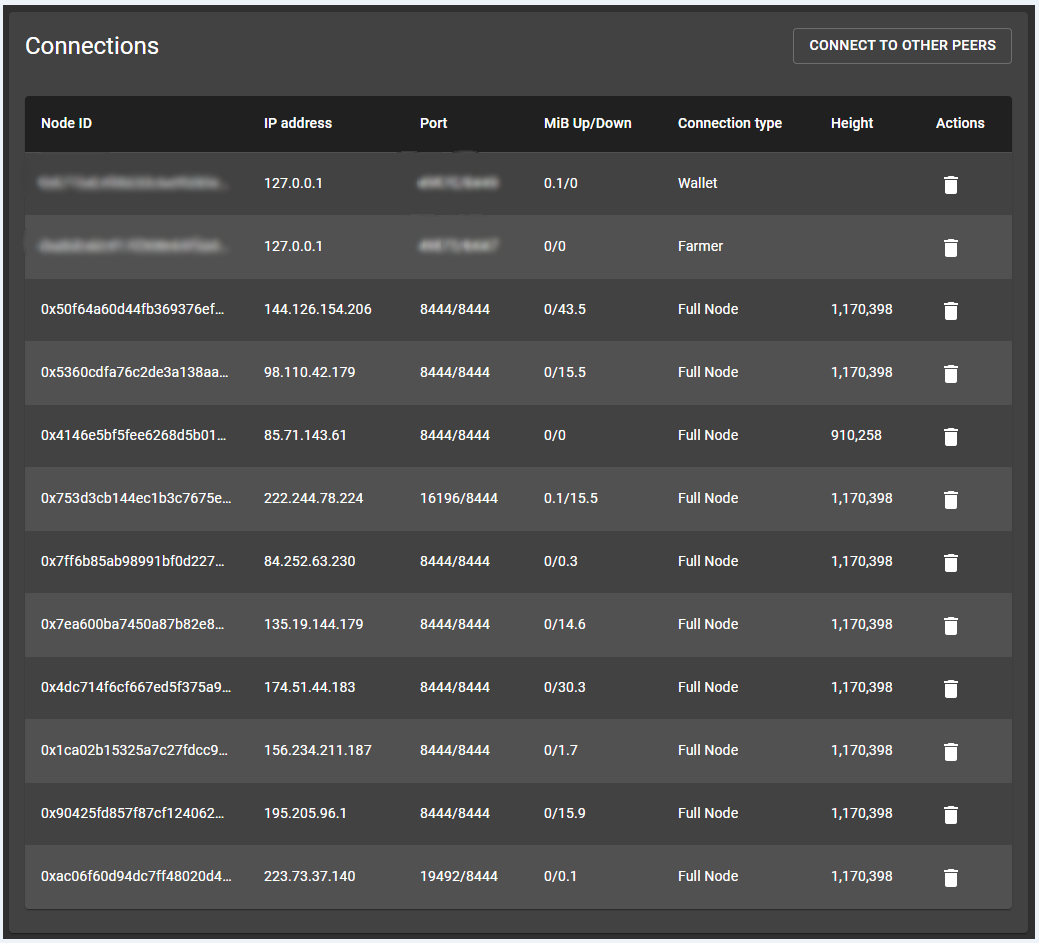
The config.yaml “target_peer_count” value is set to 10, and now, after the re-boot, I have only 10 connections:
That doesn’t sound good. Your peer connections look good. You are getting data from over half of those connected nodes. So, not that you are being stuck, but rather something else is at play.
Let’s try one more squeeze.
modify that peer count down to 3, so you should have just your farmer, your wallet and three peers.
open Task Manager and expand Chia entry. It should be right there at the top. Once you expand, it should have 10-20 processes
exit Chia
wait till all of those processes will disappear, as well as the Chia that was holding them
if they will not disappear after a couple of minutes, right click one chia process at the end of that list and select “end task”, wait 5 seconds, and repeat it until all are gone (including the main Chia). (I think that the farmer is the key, but still would go from the bottom)
once they are all gone, start chia
check whether your total number of those rows is 5. It may take a couple of minutes or so
write down the difference in your sync
wait for about 15 minutes, check the difference, and post it here. post a screenshot (exclude your farmer / wallet - I think that there is nothing there to hide (but may be I am wrong), but if that makes you feel better, why not, as it doesn’t change anything, we are not looking at those two)
Also, there is another post on the forum that talks about potential network problems right now. Chris from Flex chimed in, and mentioned that the network has some problems. My node dropped the number of peers down to 8, but it is still running kind of OK (it is synced, and no stales). Maybe you just got caught between a rock and a hard place (like Larry before), and whatever is going on with the network is amplifying your problem.
What kind of makes me think that maybe the problem is your blockchain db is that Larry’s box is about as powerful as yours. He was trying to sync for about a week, and it was not going anywhere. Yes, he moved his db to an NVMe to help that syncing process, but I kind of suspect that maybe killing his db fixed that problem (of course that NVMe helped). So, maybe v1.2.9 is just more prone to db corruption.
Usually, when you are careful (shut a given program properly), and don’t have power outages, your db should close cleanly. However, when your background process that sits on that db is not shutting down, reboot is basically crashing that process, thus there is a chance of db corruption. Unfortunately, chia doesn’t have clean shutdowns. Also, if you restart chia, while not all processes got killed, you will end up potentially with an orphaned farmer that sits on that db, and that is no good as well.
Another thing is that looking at what was fixed after dust storm, to me those changes indicate that db was badly mishandled in previous versions, as such db corruptions could be happening while chia was happily running (on all those previous versions).
Maybe with changes in protocol to add CAT1, those corruptions while running chia are just more pronounced.
Sorry, I don’t have a good explanation for why those problems are there, except crap code around db.
@Jacek I followed your instructions. No problems. Chia shut down properly, and started up properly.
But the syncing problem remains.
After re-starting Chia, my syncing numbers were:
1,168,828 / 1,170,797 (a difference of 1,969)
Fifteen minutes later, my syncing numbers were:
1,168,855 / 1,170,845 ( a difference of 1,990)
Also, my peers went to 3, based on changing the config.yaml “target_peer_count” value to 3.
But then it started increasing, and then went back to 3, and then started increasing, again.
Just a guess, but I do not think that it likes to be set lower than 5. Previously, when it was set to 5, it stayed at 5.
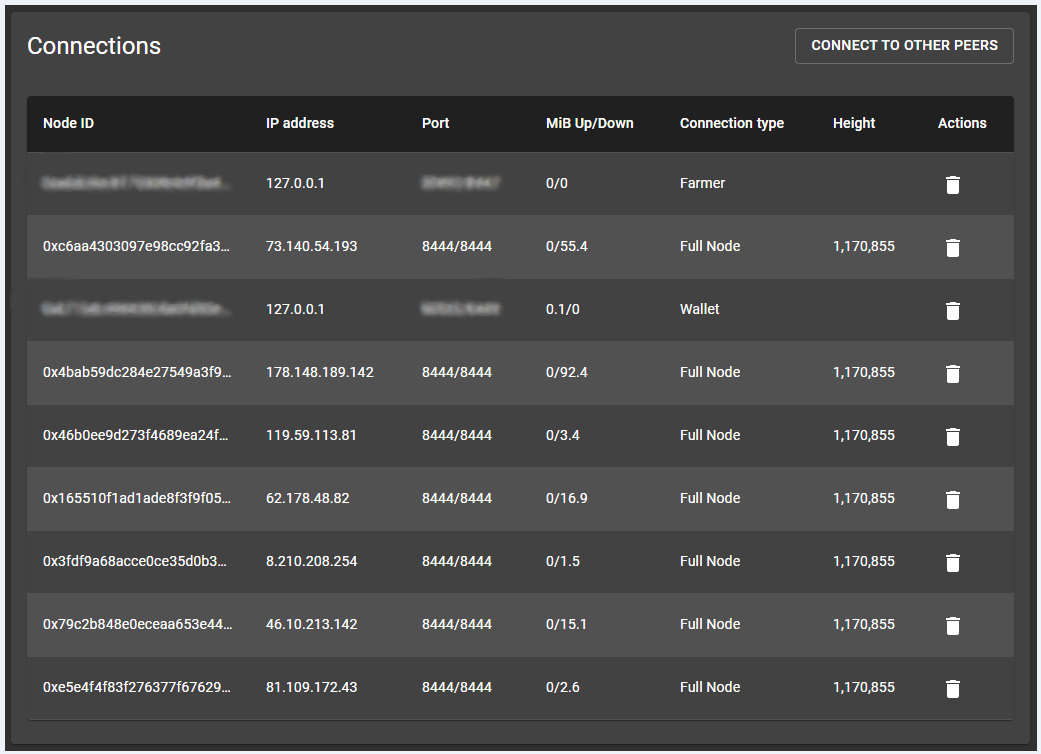
Here is the screen-capture of my peers, with “target_peer_count” set to 3:
What is next?
If you have exhausted your suggestions, then should I consider back-revving to a known, good, Chia version? Has back revving ever been done?
Or should I wait to see if it is a confirmed Chia related network issue?
All your peers look good also this time, and are sending you data. Looking at Larry’s sync time, his average speed was 2Mbps (pathetic, if you consider NVMe write speed - by order of three/four magnitudes). My hope was that at least one/two of those peers would be able to send you data much faster than that. It is not likely, that all your peers are choking (have too low upstream bandwidth). Your setup and download speed are more than adequate to handle that data rate. That implies that potentially this is not just a slow db access but rather some cardinal synchronization error that is causing node to refuse to pick up the speed.
Take a look at this post:
Few things that are worth to notice from that article. They urge to upgrade to v1.2.11. The previous statement was that only v1.2.8/9 were crap. This one implies that they do believe that all previous versions are crap.
They didn’t identify the reason for those problems, just stated that v1.2.11 has some ‘optimizations.’ I read that official statement where it was mentioned what was changed, and nothing there was about optimization, rather standard software practices instead of happy code. I know, we can argue about the meaning of those terms. However, the bottom line is that if one is not able to identify what the problem is, one cannot really fix it, and this is exactly what we see with all those versions.
They didn’t identify which versions are being affected. Again, per that previous official statement, the number of v1.2.8/9 in the field supposedly is very low (a couple of thousands or so). That would imply that not just those versions are barfing. As they didn’t mention which versions are most affected, it may be that v1.2.11 are also hurting. Again, this is not a new dust storm, just a normal day to day network traffic (that slowly grows each day), and nodes already go bad.
They didn’t mention low-power devices this time. Of course, setups like yours and Larry’s put such statements to sleep.
So, do I believe that v1.2.11 is better - yes. Do I believe that v1.2.11 is good - no.
Not sure, whether that would be the fastest way, but you should upgrade to v1.2.11. After that, I would seriously think about switching to Flex Farmer. My next upgrade will be Flex Farmer (I do belong to Flex pool already).
As Chris from Flex stated, that in the event of some serious problems, it may be that just Flex will survive, and I do believe that. However, that also implies that the whole chia will just fold as the code is not production ready, and majority of folks run chia code, not flex.
I would rather not have to deal with the password “feature” of Chia’s latest version (or whatever version it got implemented). But if that is my only option for possibly syncing, then my decision is handed to me.
I have read “Flex Farmer” mentioned in threads, but I have zero understanding of what Flex Farmer is.
– Is it a replacement for only the GUI?
– Is it a replacement for the GUI and for chia commands, too (such as: chia plots create blah blah blah)?
– Does it maintain synchronization of transactions and synchronization of the wallet?
– Can it be used to handle only functions you choose, or is it a full, 100% replacement of using the Chia code?
Same thing for “Flex Pool”. I have no idea what that is.
Chia is the first Crypto currency that I have ever tried.
When I decided to jump in, I had nearly no idea how it worked. I also had to purchase and build my computer, which was a nightmare (due to unavailability of parts, and hardware compatibility issues, forcing a motherboard swap – argh!).
What should have taken a day or two to set up, took weeks of troubleshooting, driving, and aggravation. Most of the delays were due to useless support from Gigabyte, whose B550 motherboards were a nightmare.
I finally found MSI motherboards (and was lucky to find them, due to a dearth of boards, earlier this year (not sure if that is still the case)). The MSI boards work fine. Nearly no issues.
I am mentioning this, because once I worked out the hardware issues, and got myself a stable, powerful Chia plotter, I focused on keeping it simple, clean, and not risking doing anything that I did not fully understand (because if something were to go wrong, I would be screwed). I had weeks of hell, getting everything to work, and I needed no more drama from my Chia environment.
That is why I know nothing about all of these 3rd party applications and services that I see people posting comments about. I had no time to deal with anything other than getting things working, and once working, I did not have the strength to dive into other, 3rd party Chia stuff.
Ideally, I would prefer to stick with the official Chia platform. But I do not know if that is the best decision, because I know nothing about the alternatives.
And now that the official Chia platform is falling apart (from my synchronization perspective), it looks like I must learn an alternative platform and must transition to it.
I just hope that other such platforms are properly supported, will not dry up or vanish if a key developer leaves (assuming it is more than a one-man show that supports these 3rd party options).
And with endless scams, if a user makes a mistake, they can kiss all of their hard-earned crypto-currency goodbye. And although I am vigilant, if I do not understand a new platform, I could make a stupid mistake and screw myself.
Please give me a general idea of what Flex Farmer is (or a link for a novice), and what Flex Pool is.
I do solo plotting. So is Flex “Pool” not for me? I am asking, because when you run “chia plots create”, you put in a pool key, even when not part of a Chia pool, which is yet another “I don’t get it” subject.
So maybe Flex Pool is not about joining a pool, just as the “-p” plot creation option is for a pool value, when I am not in a pool?
Last question:
Is it safe to back-rev your Chia version?
If it is a safe choice, then I would prefer to give that a try, before moving to a new platform, such as Flex Farmer.
Thanks, again, and sorry, again, for the long post. But I could see all of my hard work turning to crap if I do not handle this correctly. Your help is very appreciated.
Hey, I am also new to crypto, so we are in the same shoes.
There is nothing, absolutely nothing wrong with what you are doing. Your system is on the overbuilt side (as farmer, not plotter). You don’t run any crap software on your box that could be blamed for your problems. The only thing that your setup proves is that chia has serious issues on overspeced hardware.
As you are doing solo farming, Flex is not for you. Currently, Flex Farmer is basically a harvester replacement (for those that belong to Flex pool - no OG plot support), nothing more. However, they are also working on a full node. Will their full node support solo farming? I don’t know. So, for time being, this is not your problem.
As far as going back, as mentioned I still run v1.2.6 on a bit lower spec box (i5 Gigabyte NUC), and it is kind of stable. v1.2.7 is as good as v1.2.6, maybe better. So, you could downgrade to it. However, problems that you (and Larry) have are implying that this is not just db being slow, but some db synchronization problems. Only v1.2.11 addressed some of those, but I doubt whether they did enough, as to me that code needs a rewrite, not an “optimization.” v1.2.11 was rushed to help with dust storm. Any software that is rushed is potentially not well tested. The fact that chia didn’t provide any data about what versions are affected right now, doesn’t put much confidence that v1.2.11 is not suffering.
The best option would be to wait for v1.2.12. However, you are SOL right now, so that is not an option for you.
If your only objection is the password, you should get over it, and go with v1.2.11. When you install it, it will not ask you to use password (I did a couple of test installs few days ago, and had to use CLI to add password, although that was on a clean machine). So, with a default installation, it will be really transparent to you. Just keep copies of your mnemonics, and a copy of your config.yaml. The “beauty” of that password thing is that if you forget it, you can just delete .chia_keys folder, and you are back to square one - no password, but your mnemonics are still pure gold.
One difference for me right now is that if you use an older version, and it will not sync, we will continue beating on that version, trying to find some imaginary problems. On the other hand, if you install v1.2.11, and it will not sync, that will imply that you need to kill your db, as it is most likely corrupted. You will lose nothing, if you kill your dbs, it just adds a couple of days of syncing to get up to speed.
So, stop chia, bring back the number of peers to 20, reboot, run v1.2.11, and you should be good. Once you are fully synced, you can bring up the # of peers to some higher value (default is 80), but you will need to restart chia to get that increase.
By the way, what is your current sync status? How much behind you are right now?
A few hours ago was the last time that I checked, and I was behind by 2,139 units.
I checked, again, right now, and I am synced!
What the eff?
I am very pleased. But this is like Chia is trolling me. It is almost comical.
By the way, the reason why I am still considering rolling back to a previous version is because Chia decided that I have duplicate plots, when I do not have duplicate plots. I suspect that that is a bug in version 1.2.9 (but the bug was introduced in a version before that).
So if I go back to my previous version, I am hoping that Chia will stop reporting false positives on duplicate plots. I am being short-changed over 1,000 plots.
But I never heard of anyone back-revving their Chia version. I do not know if that would cause corruption?
Thanks for spending so much time helping me. @Aspy68 and @Lsherring were helpful, too.
Really glad that you got fully synced!! What a ride.
One can say that the whole thing that you did so far was pointless, as it got sorted out by itself. On the other hand, you have proven that the official statement that v1.2.8/9 will be bricked if such thing will happen was just a dumb comment without any understanding of those problems.
Well, as outlined in that article, and stated by Chris, network had problems (small increase in traffic ?). Looks like the network traffic calmed down (less operational nodes?), thus you are fully synced agaun. Also, it means that with the current traffic, a node needs to go dark for some time (an hour/two), in order to have syncing problems. Assuming that the network / traffic will grow, that time may shrink to the point where just normal syncing could be too much. So, the obvious question is how long will it take to break the network (just with a normal growth).
As far as your setup, bring back that peer number to 20, and keep it at that level. It doesn’t help your node at all to have more than 5-10 peers, but could potentially cripple your node if you set it too high. With your setup (v1.2.9) it may be that 20 is close to be optimal. Of course, watch your node whether it holds, if not, bring it back down to 10. Again, even with 10, you should be fine (my node for the past 12 hours decided to use just 8 peers, and it is running fine).
I don’t know anything about duplicate plots. I would open another thread, and hope that someone will chime in.
What I would do is to post there a screenshot of your Last Attempted Proof (shows your harvesters, and reported plot count), and eventually expand that Advanced option at the bottom, and post your harvester’s section. You should also post a copy of your folders from confi.yaml (the whole section under plots_directories). Of course, a rough manual count would be needed.
Another thing that you could do is to comment all your folders in config.yaml, and bring just one folder back every few minutes watching your debug.log how your harvester / farmer respond to it. Maybe that will show which folder gives those headaches. When you modify that section, your harvester will pick up those changes in 2 minutes (default value), so no need to restart chia.
I tried that a few months ago. It was a tedious process, because it took something like 40 drives to be connected (entered in config.yaml), before it started falsely reporting duplicate plots.
I could connect 25 or 30 drives, rather than starting with 1.
By the way, what is the proper format to comment out a line in config.yaml?
For example, in a Linux script, the “#” symbol is used.
I know that I could test it. But I am afraid to breath on my config.yaml file, now that things are working.
I once put a space in the wrong place, and Chia had a fit. I had a copy of the file (I always make a copy before I edit), so it was easy to put back. And comparing the two files is how I discovered my mistake.
Anyway, the config.yaml file comes across to me as needing exact spacing and exact formatting to function properly. So if I do the “adding drives to trigger false duplicates” test, I would like to start by commenting out existing lines of plot locations, while not corrupting the file.
Hehe There is no magic in either 1 or 30. The fastest route would be to do binary division (easiest to follow). The simplest one is to do one drive at a time.
All folders visible:
plot_directories:
- e:\chia\pool
- f:\chia\pool
e: drive blocked (although, you need to keep indentation right):
plot_directories:
# - e:\chia\pool
- f:\chia\pool
Potentially, the most important thing is indentation, spaces should be OK, as long as those don’t change indentation.
I would first comment all your folders, to see whether the count will drop to zero. Once you see zero (in Latest Proof …), uncomment half of your folders, and check your log. If the log is good, uncomment half of what is left. Follow that half route till you see problems. Once you hit problems, start commenting half of what is uncommented, and do half on/off till maybe you get two drives identified. I guess, that would be the fastest route for you.