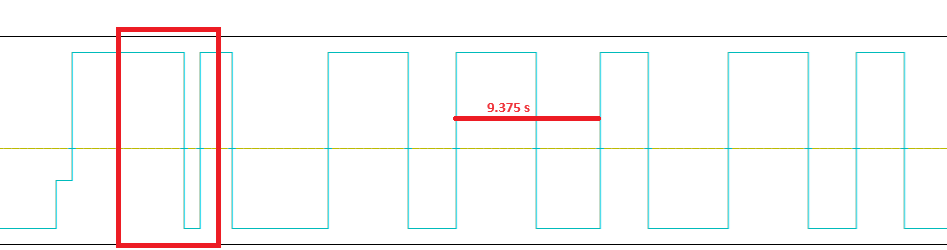
By the way, you are running your farm with 250 diff. You have some brown (over 9sec) lookup times. Also, not too many (6 over the last 24 hours) missing partial slots (those bars on Stats chart for 1 day represent 15 mins slots). Maybe you could try to push your diff to 500 or so, that will most likely lower those high-lookup outliers. Although, you may want to monitor those missing proof bars and Effective Capacity. I am running my farm with ~3.5x the calculated value for the past 24h. I will let my side run like that for another day, and tomorrow will try to push it to 30x or so (to see how many proofs will be there per hour).
Both our farms are close to GPU capacity (based on lookup times). So, trying to push those diffs up right now before completely switching to c3x will give some feedback about EC / payments as far as finally pushing diff to 20k. Basically, switching from c19 to c30 gives about 30% more proofs, so not that big change.
What you could also possibly do is to try to get your avg lookup times based on your harvester log lines and compare that with what you have in your pool stats. In my case, I have about 2 secs difference, and I am not sure how to account for that (my guess is that most of it comes from the pool side, as once the harvester produces that line, it pushes it directly to the farmer, and this one make a REST call to the pool, so not much room to gain that extra 2 sec delay).