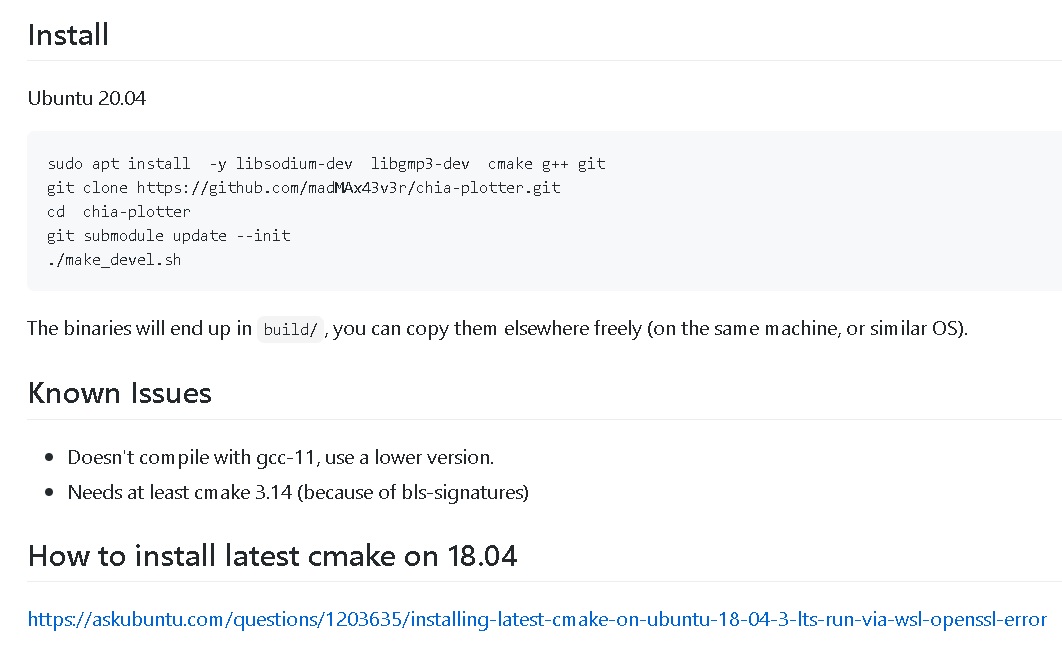
BIG UPDATE: unless you are using RAM as disk, a normal user with NVMe with traditonal RAM method, 1 plot finishes under 4 hours.
Test done on an i7-8700K at 4.3 GHz (100% core and thread utilisation), phase 1 finished in 55 minutes, on 2 Evo Plus drives as temp1 and temp2. (These specs are probably “above” the average chia user specs, majority do not have Samsung Evo Pluses, Intel Core i-Ks.)
It’s currently only on Linux (if otherwise hint a working Windows version in the comments).
Anyone working on a Windows version?
The first programmer who compiles a descent version for Windows, please give him some donations.
You are copying the same thing, giving us the exactly the same final files, just the names changed. Do a bit differently, maybe turn it into Windows version.
Windows version here. GitHub - stotiks/chia-plotter. Running on my 5900x using 2 temps drives. Getting 2194.27 sec a plot.
Number of Threads: 24
Number of Sort Buckets: 2^7 (128)
Pool Public Key:
Farmer Public Key:
Working Directory: A:\Chia-Temp\
Working Directory 2: B:\Chia-Temp\
Plot Name: plot-k32-2021-06-09-12-40-0974ab074f18b55cc94bd96d6b19938d264b3edd01b7b2c4db604509c0cc31e4
[P1] Table 1 took 16.2787 sec
[P1] Table 2 took 117.854 sec, found 4295000015 matches
[P1] Lost 31995 matches due to 32-bit overflow.
[P1] Table 3 took 164.752 sec, found 4294992698 matches
[P1] Lost 25343 matches due to 32-bit overflow.
[P1] Table 4 took 203.601 sec, found 4294986591 matches
[P1] Lost 19125 matches due to 32-bit overflow.
[P1] Table 5 took 198.454 sec, found 4294961999 matches
[P1] Table 6 took 191.329 sec, found 4294886094 matches
[P1] Table 7 took 141.666 sec, found 4294831843 matches
Phase 1 took 1034.04 sec
[P2] max_table_size = 4295000015
[P2] Table 7 scan took 6.86807 sec
[P2] Table 7 rewrite took 43.1811 sec, dropped 0 entries (0 %)
[P2] Table 6 scan took 25.0325 sec
[P2] Table 6 rewrite took 44.889 sec, dropped 581283865 entries (13.5343 %)
[P2] Table 5 scan took 27.572 sec
[P2] Table 5 rewrite took 42.4083 sec, dropped 761974159 entries (17.7411 %)
[P2] Table 4 scan took 26.394 sec
[P2] Table 4 rewrite took 41.9253 sec, dropped 828866398 entries (19.2985 %)
[P2] Table 3 scan took 26.6823 sec
[P2] Table 3 rewrite took 40.4959 sec, dropped 855116124 entries (19.9096 %)
[P2] Table 2 scan took 25.5263 sec
[P2] Table 2 rewrite took 40.2445 sec, dropped 865608556 entries (20.1539 %)
Phase 2 took 402.084 sec
Wrote plot header with 268 bytes
[P3-1] Table 2 took 55.2761 sec, wrote 3429391459 right entries
[P3-2] Table 2 took 43.6618 sec, wrote 3429391459 left entries, 3429391459 final
[P3-1] Table 3 took 56.6331 sec, wrote 3439876574 right entries
[P3-2] Table 3 took 44.4808 sec, wrote 3439876574 left entries, 3439876574 final
[P3-1] Table 4 took 56.711 sec, wrote 3466120193 right entries
[P3-2] Table 4 took 45.0573 sec, wrote 3466120193 left entries, 3466120193 final
[P3-1] Table 5 took 58.5939 sec, wrote 3532987840 right entries
[P3-2] Table 5 took 45.9072 sec, wrote 3532987840 left entries, 3532987840 final
[P3-1] Table 6 took 61.448 sec, wrote 3713602229 right entries
[P3-2] Table 6 took 48.0745 sec, wrote 3713602229 left entries, 3713602229 final
[P3-1] Table 7 took 74.5679 sec, wrote 4294831843 right entries
[P3-2] Table 7 took 56.0288 sec, wrote 4294831843 left entries, 4294831843 final
Phase 3 took 649.54 sec, wrote 21876810138 entries to final plot
[P4] Starting to write C1 and C3 tables
[P4] Finished writing C1 and C3 tables
[P4] Writing C2 table
[P4] Finished writing C2 table
Phase 4 took 108.53 sec, final plot size is 108833538383 bytes
Total plot creation time was 2194.27 sec
But stotiks also contributed his work to the main repo of madMAx43v3r.
This is a normal workflow to fork, improve things and merge it back to mainline.
It’s really cool, but I don’t think I will use it.
System is dialed in now. I would have to get 40 minutes or less with this running a single plot. If a 5900x can do it in 2200 sec, I doubt a 3900x can do it in 2400 sec.
This way would be much easier though for a new system. Saves a lot of time and effort to dial in a system and find the right parallel settings