The big challenge I have is using the RSYNC feature. I found out you need to configure ‘the rsync daemon’ on the destination which basically sets up a receive point, then you can put those settings in plotman. I’ve yet to set it up though. Any successes?
The other problem I have is if I have a destination that fills up, plotman keeps starting plots to go there and I have to manually interfere and move the .plot.2.temp files there and rename.
Otherwise it’s served me well to my little farm. No more drives in my price appetite so as soon as my costco 8tb smr drives fill i’m going to zip tie them all to a shelf and farm it forever. Haven’t decided if i’m replotting for pools but my 5950x goes fast enough it might be worth it.
Look at the plotman wiki page. Very good write up. Archiving · ericaltendorf/plotman Wiki · GitHub
1 Like
Dont suppose anyone can help me with my config. Only seems to be doing max 4 plots at one time
Ive been plotting with #plotman and doing 3.2 tib a day. Can anyone assist me with my config file on getting the optimal settings? For some reason my system only seems to be running 3 at only 1 given time even though its set to do max8 jobs at one time. This is my settings if anyone could assist me. I have a 2tb nvme, 64 gb of ram and 12 core, 24 thread.
Minor 2
Major 1
Phase limits 1
Max jb 8
Max global jobs 8
Stagger 30
n_threads 4
Job buffer 4500
Any help would be much appreciated as can’t seem to get my ploting higer even though my system seems to only be running at half of what it Could as my ssd never reachs more than 50% full and ram never really goes over 25%
You have your minor and major flip.
Minor 1
Major 2
Phase limits 4 (Play with this number 3, 4, 5)
Max job 7 (6 or 7. 8 is too much)
Stagger 45 (30-50)
Thread 4
Buffer (4000-5000)
Hi all,
This is my settings if anyone could assist me
CPU 1650 v3
RAM 32GB
NVME 2X4TB Sabrent
HD 16X8
directories:
dst:
- //media/suseer/plothdd
log: /home/suseer/.chia/mainnet/log
tmp:
- /media/suseer/nvme
- /media/suseer/nvme1
plotting:
e: false
job_buffer: 2000
k: 32
n_buckets: 128
n_threads: 2
scheduling:
tmpdir_max_jobs: 18
global_max_jobs: 36
global_stagger_m: 35
polling_time_s: 20
tmpdir_stagger_phase_limit: 2
tmpdir_stagger_phase_major: 2
tmpdir_stagger_phase_minor: 1
Any help would be much appreciated
Friends, pls help. I have update my PLOTMAN config.yaml and the result seems not right (sad)….
Below is my interactive screen for nearly 20 hours time……
[Here is my server]
1 CPU: E5-2470V2 (10 cores, 20 theads)
RAM: 48G
Temp SSD: /plot: 3.84T Intel S4510 ssd /plot2: 1T MP600 PRO NVMe M.2 SSD
Dst HDD: 18T HC550 sas (X2) (Refers /farma and /farmb)
[Here is my plotman config]
tmp:
- /plot
- /plot2
tmp_overrides:
“/plot”:
tmpdir_max_jobs: 10
“/plot2”:
tmpdir_max_jobs: 3
dst:
- /farma
- /farmb
scheduling:
tmpdir_stagger_phase_major: 2
tmpdir_stagger_phase_minor: 1
# Optional: default is 1
tmpdir_stagger_phase_limit: 7
# Don’t run more than this many jobs at a time on a single temp dir.
tmpdir_max_jobs: 10
# Don’t run more than this many jobs at a time in total.
global_max_jobs: 13
# Don’t run any jobs (across all temp dirs) more often than this, in minutes.
global_stagger_m: 35
# How often the daemon wakes to consider starting a new plot job, in seconds.
polling_time_s: 20
plotting:
k: 32
e: False # Use -e plotting option
n_threads: 2 # Threads per job
n_buckets: 128 # Number of buckets to split data into
job_buffer: 4500 # Per job memory
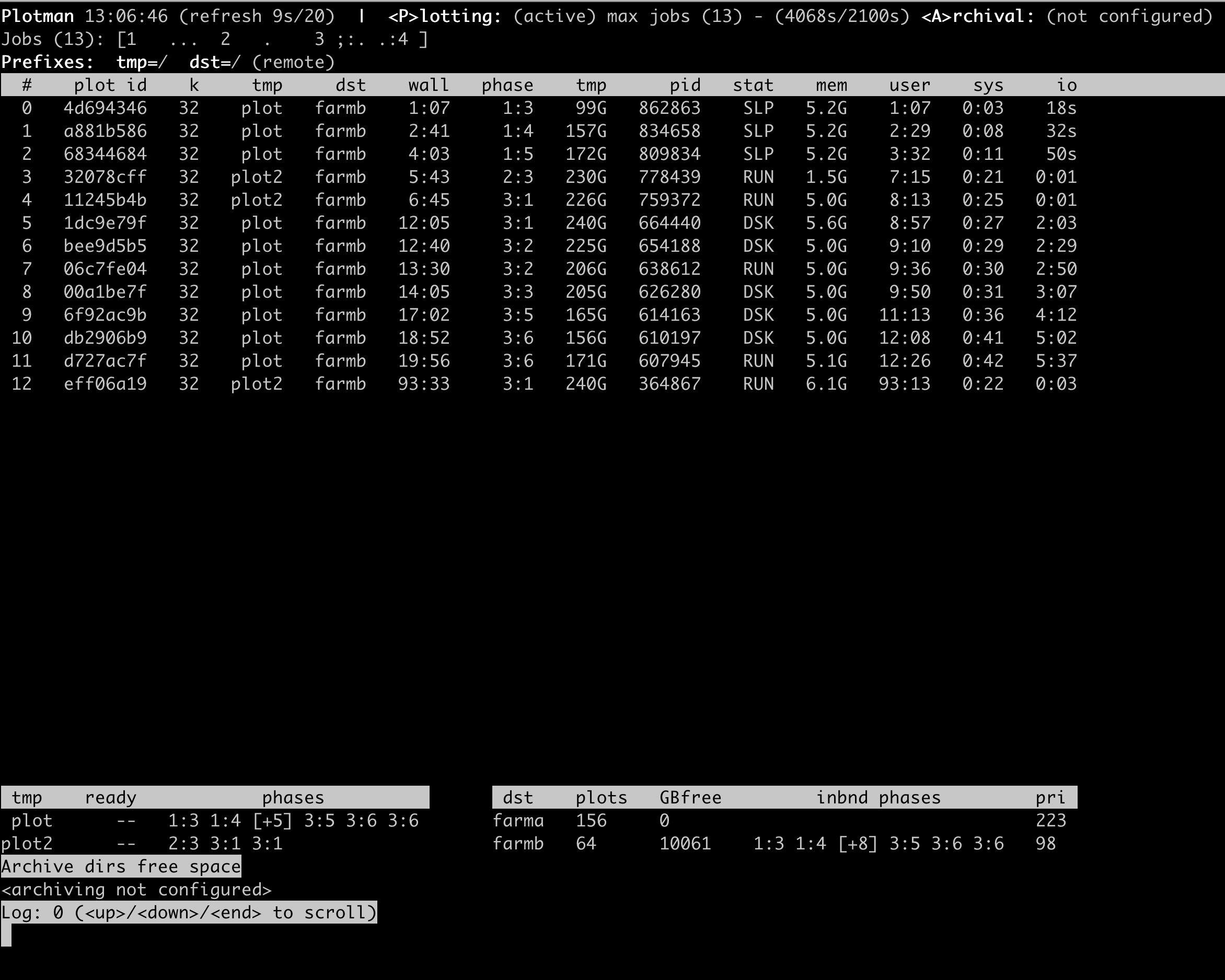
I would ctrl+c and run plotman kill eff06a19. That would kill your 93 hour job and clean up your temp directory of that plot.
1 Like
I would up the staggering time to 45, that seem to be killing your process. Override only the 1TB temp drive at 3. The 3.86 should give you 12 max. tmpdir_max_jobs: 12. The staggering phase limit is for each tmp drive. Setting at 7 mean you will have 7 + 3 which is 10 concurrent at phase 1. That will be at max of your thread since you set your thread at 2.
1 Like
You have a 12 Threads CPU. Max job is too high. your should be global_max_jobs: 6 as you have 2 threads per job. Try 6 then move up to see if any performance degrade. Job_buffer should be minimum 3340. Usually people set at 4000. You have no memory issue so set 4000. Staggering time might be too low for your machine, set that at 45. To be honest, you have way too much tmp drive and way too under power with your ram and cpu. 1 4tb tmp probably overkill for your CPU and Ram