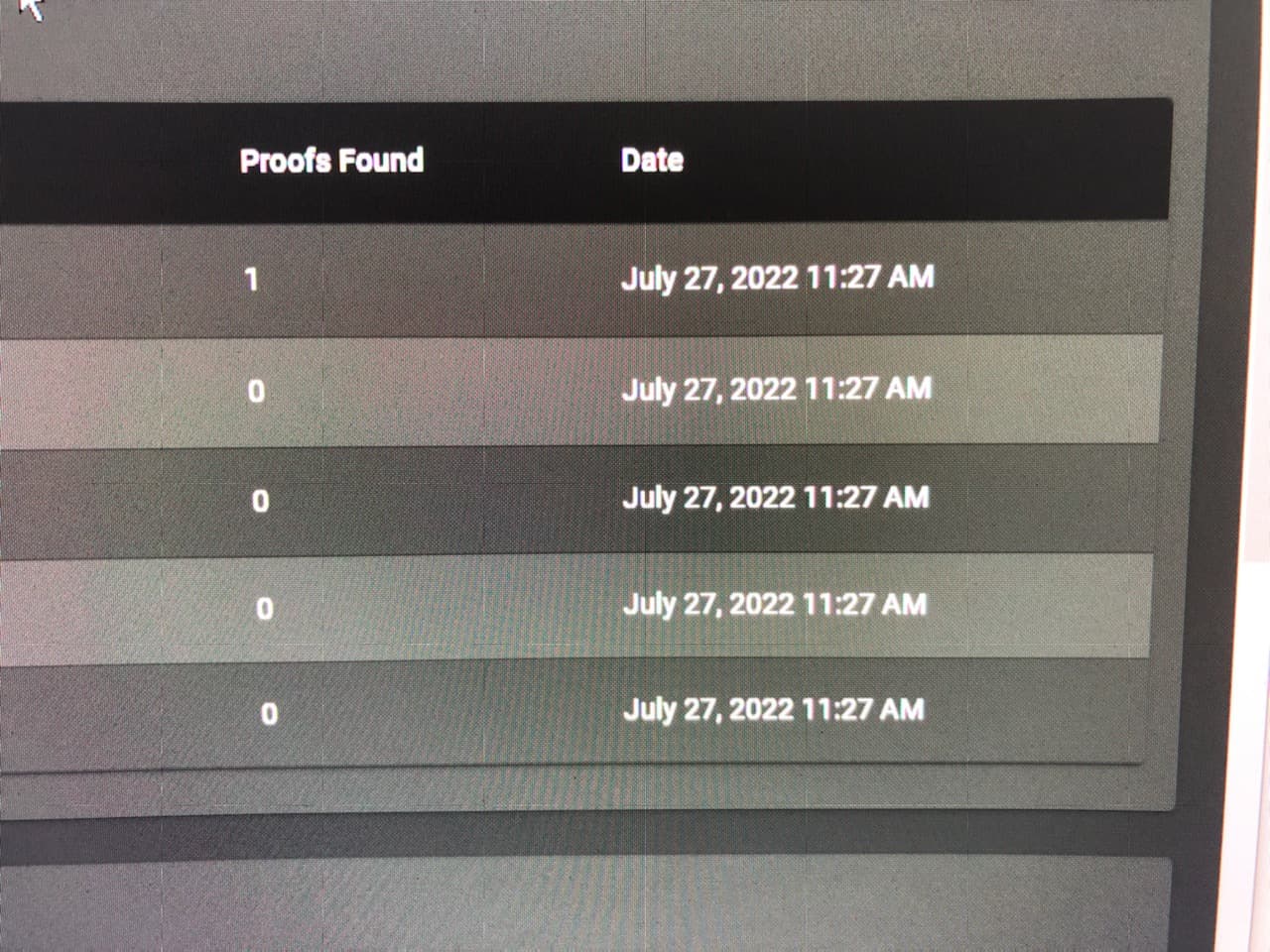
At 11:27, today, my full node lost its internet connection.
I caught it two hours later.
It started to sync, and was caught up in 60 seconds or so.
But I saw two things that I never saw before, and am listing them here for feedback.
On my GUI’s “Farm” page, it showed a proof, right at the time when I lost my internet connection.
This was the first time that I have ever seen a value other than “0” in the “Proofs Found” column.
Would I have won a block if my connection did not fail at that time?
Or did that plot just give me a shot at competing with other folks that had a found proof?
When I started to sync, my XCH balance dropped by 12.
I checked my wallet, to see if a transfer was made. None listed.
My wallet showed my full balance. Yet my “Farm” page was short by 12 XCH.
Even upon the GUI showing that I was fully synced, I was short 12 XCH on my “Farm” page.
Approximately 60 seconds later, my full balance showed up on my “Farm” page.
What was the “Farm” tab reading that made it differ from the “Wallet” tab?
I have lost my internet connection before, and I never saw my XCH balance change.
Not sure about your “found proof” case, as I am pooling, so have those all the time.
However, I also noticed a similar behavior when updating patches / rebooting while on v1.3.3. I didn’t pay attention to it, as the garbage was replying a bunch of previously recorded earnings from my pool, causing ChiaDog to go nuts spamming my email.
My take is that that version keeps the position of when it was last restarted (or something like that), and when it is restarted again, go back with syncing to that previous event. So, the syncing is not really based on when the last bc / wallet was synced, but rather on some date / db position(s) stored somewhere (conversely, all updates since that date not marked as fully processed in db). Most likely, the intention was to recover from potential db corruptions, but the side effects were kind of not expected.
You could potentially dig in into your logs trying to get more info on that proof found (if your logs reach that far).
It looks that v1.3.5 fixed that problem for me (it was a smooth upgrade, so recommended to do).
If something was being replayed or re-synced from that time of my disconnect, then my XCH balance should not have changed.
In my dreams I wish that my XCH balance would rise by 12 XCH in 2 hours.
It was months ago that my XCH balance was 12 less than it is today.
Or did you mean that Chia chose to check the integrity of the database, found something at the time I had 12 less XCH, fixed it, and eventually caught up and showed me my proper balance?
My 1.3.3 version is running smoothly (short of today’s incident, which is not Chia’s fault, but Chia did act strangely). So I will stick with 1.3.3 until someone gives me a convincing reason to install a later version.
And when I install a later version, I will not want it to be only a step or two forward. I will want to upgrade to the latest, well behaving version.
No, it is not from your latest disconnect, but rather from the last stored date that happened when you restarted it a month ago. I am also not sure, if it was storing that date on every reboot, as I have seen it several times happening (thanks ChiaDog’s spamming). Every time that happened, the wallet was reverting by a month or so for me. So, not sure what is the time span for that 12 XCH for you, but again this is a fresh event, so you could get the block number when it started resyncing, and potentially try to correlate it with some previous restart. Maybe that is a point when you upgraded to v1.3.x, and it was going from there. Maybe a clean shutdown would create a new "restore’ point for it.
So, either it stored that ‘start-resync’ date when it was upgraded to one of those v.1.3.x, and will always try to resync it from there, or there is another bug that prevents it from updating that date on shutdowns.
My feeling is that it was cured for me when I updated to v1.3.5, as I got several of those resyncs on v1.3.3, but have not seen those anymore since moved away from that version.
There are kind of two problems there. The one is that when resyncing, there should be no proof validations happening, as it will just trigger a lot of HD access that is irrelevant to the syncing process.
The second is that the wallet is picking up on those old events being replayed (for you it is just those few blocks that you won, for those that are pooling, it re-registers all the earnings for that “lost” period). Potentially, the problem with the wallet is that it tries to sync completely from peers when the local node is not fully synced, and then when the node catches up it is trying to re-resync again to be in line with the local node.
UPDATE
So, saying all that, most likely (or rather certain about it) the proof found that you have on that screenshot is one of those 12 missing XCH you have right now, not really a new event. You could use something like xchscan.com to look at your wallet and compare block heights you have there with what Chia is replaying right now.
When you re-booted it, did you check blockchain / wallet folders, whether there are *wal/*shm files? If those are present, they indicate that db was not shut down properly (was just abandoned in whatever state it was at the moment).
I used the GUI’s exit.
I only checked, via taskmgr.exe, that all Chia processes closed.
It looked clean to me. But if I should be checking for *wal and *shm then I will do so going forward.
Actually, I can verify whether or not *wal and *shm files were present after exiting the full node.
After I shut down Chia, I copied the entire mainnet directory (and below). I always do so, to have a clean set of files that I can rely on.
It is not so much that we should, but it is good to know, in case there will be some weird behavior after startup.
I have just applied patches, and before doing it, shut down UI. The shutdown was fast, and those files were there. Although, I had to manually kill those processes in using Task Manager. (I am on v1.3.5, though.)