This is a test of how well a dedicated harvester per NAS works running in a VM. I’m not talking about a remote havester loaded on each NAS. All of them on the same computer along with the Full Node. Spoiler alert, so far it works great. First a quick look at my hardware and some history.
Hardware
2 dedicated plotting systems
2 Synology DS1817 NAS
1 Netgear ReadyNAS 424
1 desktop running full node and hyper-v
History
When I originally started plotting I had two NAS online and each plotter was plotting to it’s own NAS. But I had the full node farming both NAS’s. It was fine in the beginning but as I approached 150 or so plots, the challenge times were already getting out of hand. I then split my network into two, one for plotting and one for farming. This helped a lot. Removing the plot writing traffic from getting in the way. But even then, the times continued to climb. So at the time, I loaded docker on the readynas and split the harvesting between the full node and the docker remote harvester. All went great. So that was the plan for the future. Load a remote harvester on each NAS. Well, problem. Without doing some fancy version downgrades of the Synology DSM software, my DS1817’s can’t run docker or any VM (I’m still going to test the downgrade option just in case this set of tests don’t work).
Test 1 (Virtual Machines)
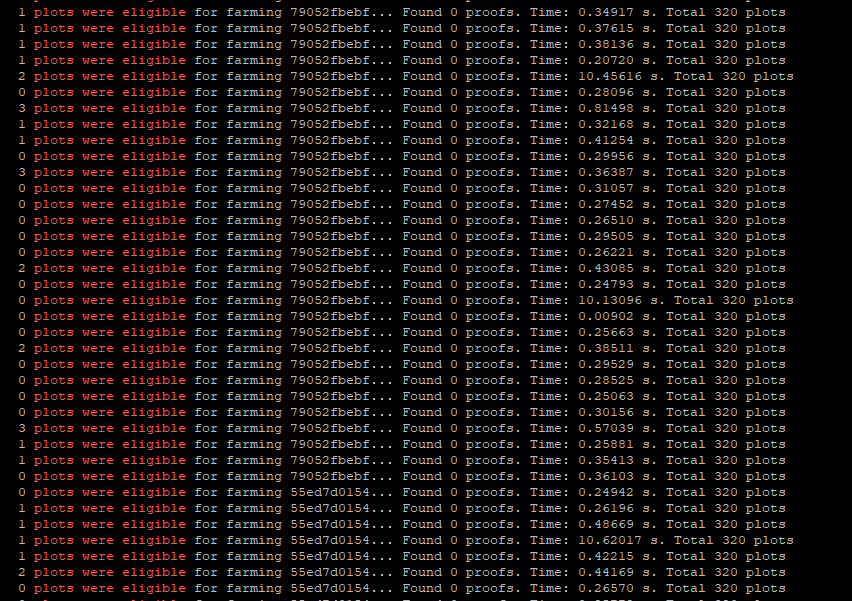
So that lead me to this. I wanted to know if the original problem was the number of plots being harvested over a network connection or the fact it was trying to harvest over the network to more than one NAS at a time. So, on the full node, I setup Hyper-v and loaded a Ubuntu server. Then setup Chia remote harvester and Chiadog. I then set it up to harvest the ReadyNAS which now has 291 plots on it. And it works great. The full node on that same machine is harvesting Synology1 which has 185 plots. So that is way more than the original setup was harvesting on two NAS’s and it is running perfectly.
Test 1 Result
My first suspicion confirmed. A single harvester/farmer has a really hard time harvesting two separate NAS devices. But two harvesters (even on the same machine) can do it no problem.
Since then, I have setup two more VM’s exactly like the first. Moving harvesting off the Full Node altogether. Now I have a Ubuntu server running a remote harvester and chiadog for each of my NAS’s. Running well. The full node just serves farming information to those harvesters and keeps the node/wallet in sync. (again to be clear, all of this is on one computer) Now for the final test.
Test 2 (VM’s Multiple Folders each harvester)
Each of the remote harvesters are currently only farming one folder per NAS. Running well. But, I am currently copying plots from one NAS to another so I can reformat it. So once those are copied, I will be farming another two folders on one harvester. Will the original problem reappear? Because ultimately, each of the Synology’s will have 8 folders (one per drive). So this test will decide if I need to do the software dance and load remote harvesters on each NAS.