First of all why?
Second of all there is new one:
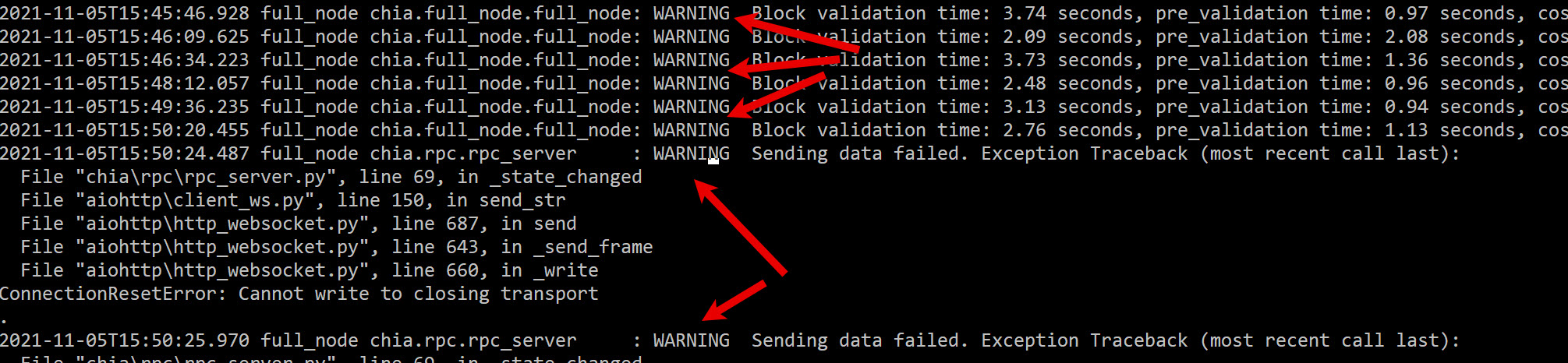
WARNING Sending data failed. Exception Traceback (most recent call last):
![]()
First of all why?
Second of all there is new one:
WARNING Sending data failed. Exception Traceback (most recent call last):
![]()
What those warnings probably show is that you have a generally slow response time.
The, “WARNING Block validation” was upgraded from INFO the upgrade before last. It has always been there but users did not see it before as it was not a WARNING.
It says that you did validate the block but it took longer than expected. You really have something to worry about if it is taking close to 5 seconds or longer on a regular basis.
Your times are higher than I would prefer but not disastrous.
Not bad Andy, you back to be grown up again, i appreciate this. 
So, what could it be that causes it? What part of setup is under suspecious? 
Do you have farmr or another installed to monitor your response times?
If you go not have farmr I would grab it right away. It will usually show problems, not give direct answers to the problem, but it is good at showing you where to look.
Generally, slow responses are due to too many disks (power issues), slow USB or NAS connected drives, and/or plotting (writing) while farming.
My avg response time is well under .17 seconds with my longest responses under 2 seconds. I use USB 3.0 SS 5GB/s from end to end to achieve the excellent response times.
As the WARNING block validation appears if the block validation takes over one second I probably have the warnings in my logs as well but they indicate no problem, and most are probably under 2 seconds.
Anywaze, here’s farmr:
I find farmr much more useful in the browser interface. Don’t bother with the discord option unless it makes you happy. ![]()
I can’t, paranoia and all ![]() but i’m comfortable enough to check all my logs just observing logs in text editor periodically.
but i’m comfortable enough to check all my logs just observing logs in text editor periodically.
Is it power issue for sure, because when it appeared there was rumoring about that it has something to do with slow cpu, which i found speculative
slow USB
really, that could explain … i’ll try to remove several of my 2.0 usb interfaced devices, and if so i’ll try pcie-to-usb3.0 extension card i bought recently.
![]()
You would have to be running an ancient PC for the CPU to be your bottleneck. The CPU and the physical memory are the fastest parts of your system.
The power issue only occurs if you try to connect too many HDDs to a PSU. Some of the drives will start to brown out.
Hmm, well then that is not the issue.
This is pretty old but i can’t name it obsolete - i7-860/16Gb ddr3 1600. PSU is solid enough - 650 bronze … hmm… so we’re at we were …
You farming over a SMB v3 connection? Slow CPU is legit a cause for suboptimal times, and it seems a more recent phenomenon since 1.2.8 or 9. Cant recall which 100%
I would not point to the 16GB memory as your issue, but you could certainly speed many things up by having at least 32GB of the fastest memory you can install on the motherboard.
I think upgrading your USB 2.0 to 3.0 (throughout, end to end) will improve your response times considerably.
USB 2.0 is .5GB/s. Standard/basic USB 3.0 is 1GB/s. USB 3.0 SS (it has other names) is 5GB/s.
Many farm with and defend their USB 2.0 as doing the job. I think this is true, but only to a point and your response times will not be as good as I would prefer.
IMOP regular USB 3.0 1GB/s is more than adequate for all but the largest USB farms, but will still not give you the best avg response times.
Using USB 3.0 SS 5GB/s is overkill, but I like it.
but wait, what it has to do with harvesting/farming. this is full_node chia.full_node.full_node: WARNING
You should reconsider and at least try farmr. It is such an excellent tool, as Aspy68 says, it tells a lot, not answers, but symptom very well. It’s not dangerous. It takes your logs (sets then to INFO), condenses all that technobabble into useable, readable, actionable information.
An analogy might be… “I’d rather use a paper map, I’m suspicious, as Google is spying on everything I do.”
Truly, no offense, you’re shooting yourself in the foot by not using it lol.
Response time is a measure of how long it took your PC to provide the answer to a question asked of a file on one of your HDDs.
Most of this time is taken up not by the question itself, but by how long it takes the question to travel your HDD and back.
The question is answered more quickly if the wires it travels through are faster.
I hear you bro and respect your point, but since i don’t see neither warnings nor errors (besides i described) why would i need any tool?
When you have a problem you use the best tools at hand to fix it.
You are not sure if you have a problem or what it is.
farmr is one way to find out.
just off all my usb drives, the warning keeps pop up …
nahh guys, thanks for trying but this is something else, don’t be upset.
I’ll try farmr, but i have a feeling it won’t help me either
Simply, in the pursuit of perfection, you want your response times to look a good as possible. Something like this, for example (farmr summary output):
Longest response: 1.42651 seconds
Shortest response: 0.1091 seconds
Median: 0.263s Avg: 0.309s σ: 0.145s
0.0-0.25s: 3940 filters (42.4%)
0.25-0.5s: 4357 filters (46.9%)
0.5-1.0s: 975 filters (10.5%)
1.0-5.0s: 27 filters (0.290%)
Again, this is full_node warning, forget about HDD drives.
afterall it might be cpu issue. i might assume my cpu isn’t good enough to operate over calculating updates for blockchain main sqllite file in realtime, something like that.
Not sure what you are getting at. I’m running a full node as well. Almost any CPU is so fast, that it is unlikely, but of course everything is suspect & so possible. Everything else in the chain is orders of magnitude slower.
You are right. Been digging the wrong hole.
When I looked at your posted pic again I saw the cause that I missed the first time.
fullnode chia.rpc.rpc.server :WARNING Sending data failed.
This is the real source of the warnings. This warning occurs whenever you drop a peer. Dropping peers and getting new ones is a regular part of the process and is nothing to be concerned about.
Because you dropped a peer, all requests for validation in the queue for that peer are stopped and have to be re-started.
The fact that you still completed all the validations in well under 5 seconds actually indicates a healthy system.
Do you have your log set to INFO?