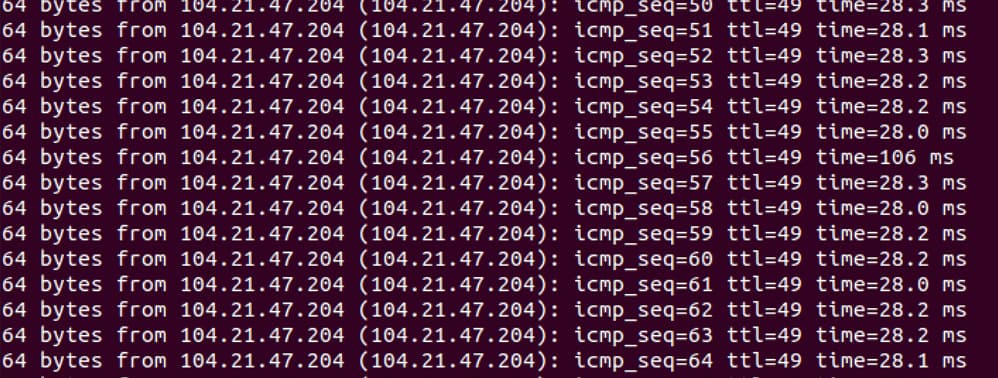
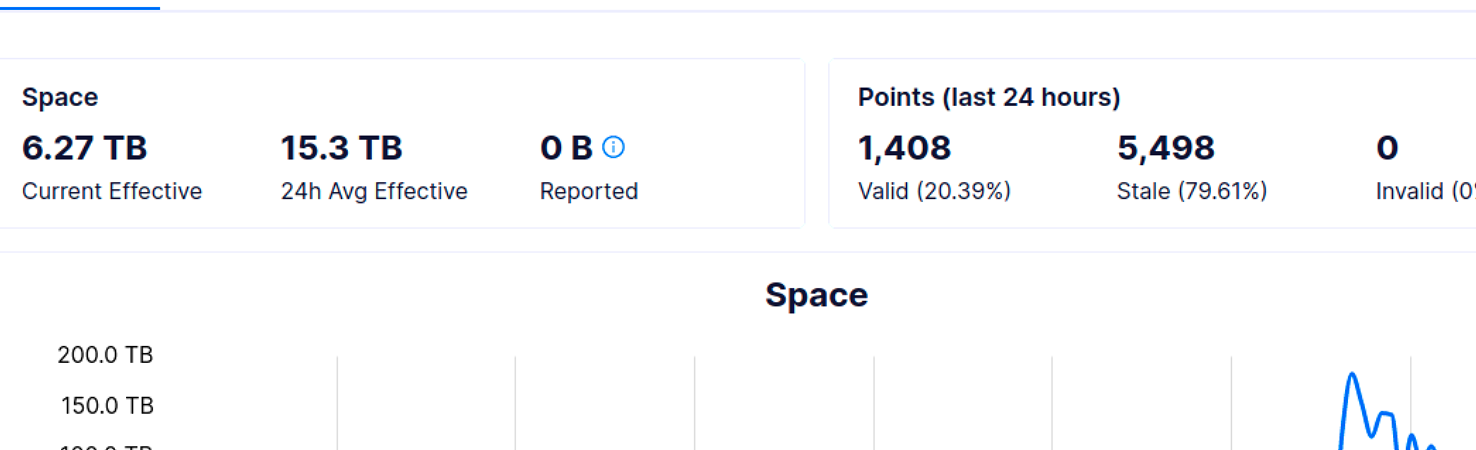
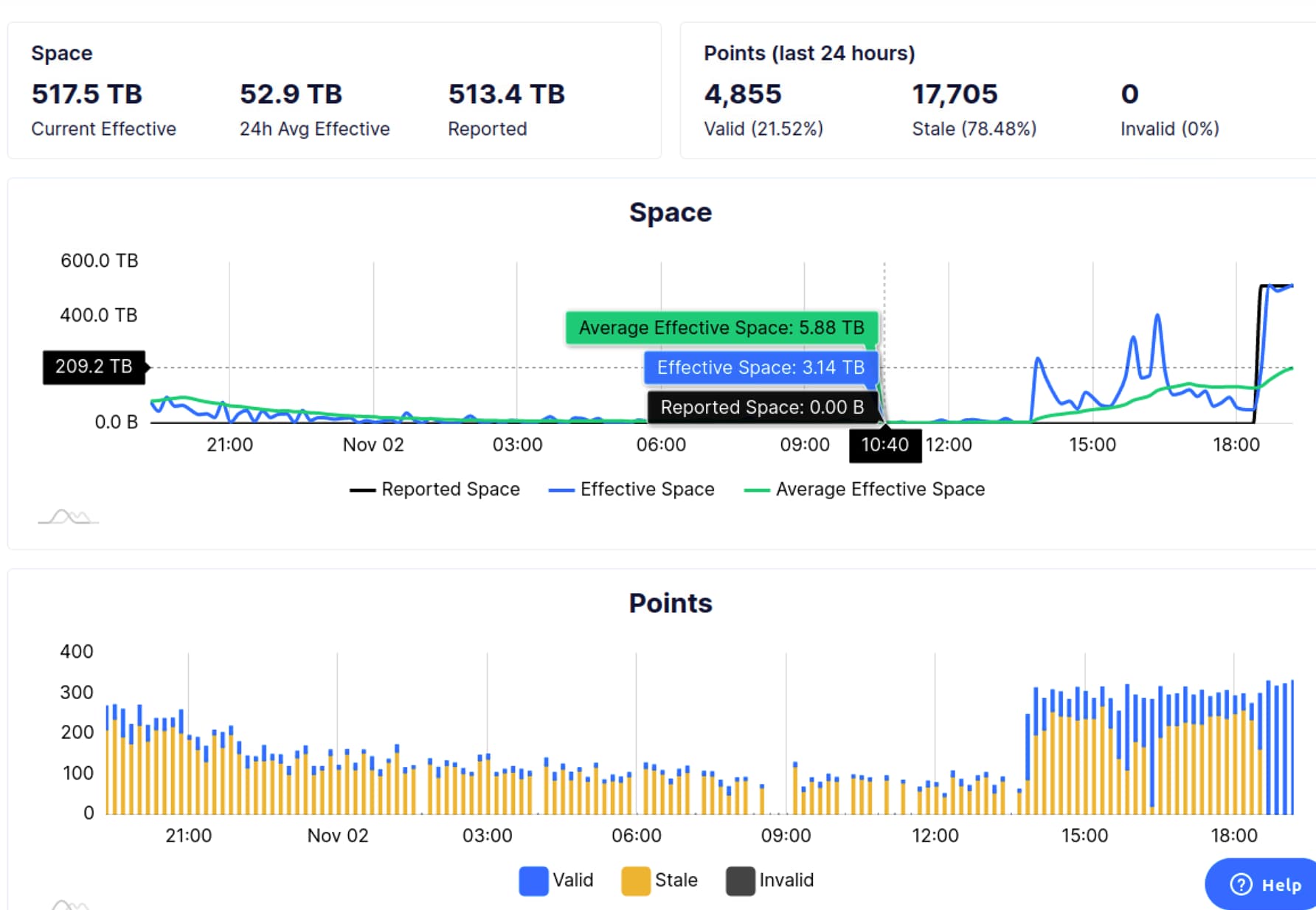
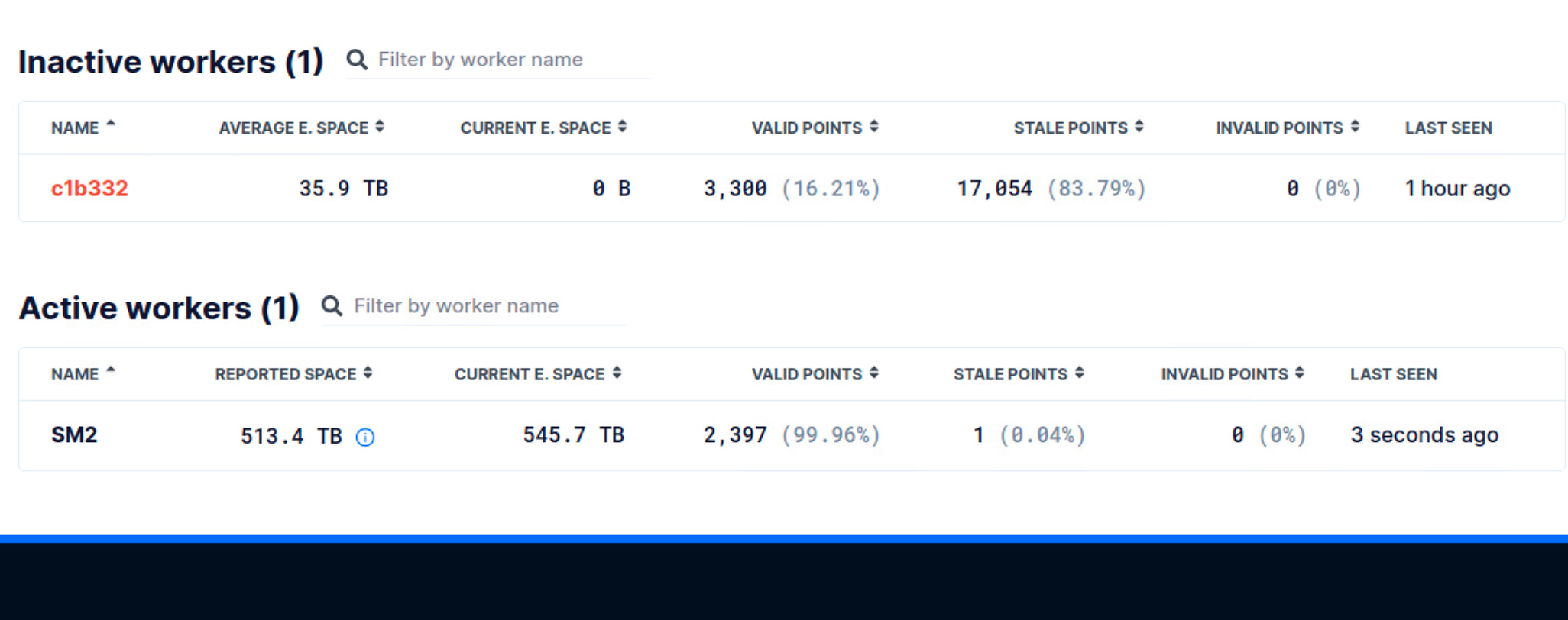
Would be good to see that chart as well. Not seeing that, it kind of points to two issues. First is some heavy, potentially network issue, as dropping your space means that you are not responding to those challenges, where the second one is that you are getting your results late, when everything else seems to be OK.
By the way, I would keep that ping alive 24/7, so maybe that could show some network hiccups.
To me, your setup sounds fine (so far), although we know that it is not, and we cannot pinpoint it. Switching to flex is good option, but doesn’t really answer what is amiss. So, I would still rather bang on it for some time.
Don’t you think that you may have some internal router problems, where that sucker thinks that your box is an issue?
Before giving up, I would still disconnect those volumes, and run chia for some time, to get results for each individual volume.
Also, maybe this is a good time to start parsing your logs? Although, I am not that good at that. I mean, the obvious thing is to cat your logs, and grep for ERRORS, maybe up that to WARNINGS, and see what that will give us.
I will need a break - need to get some food.
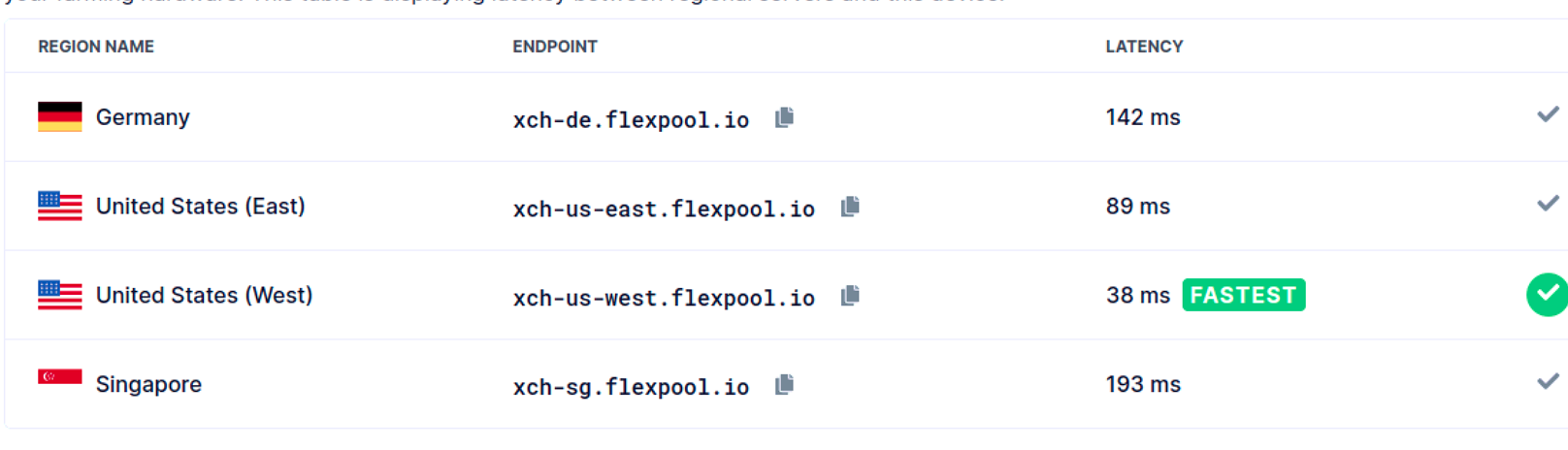
Also, maybe tomorrow, you can ask your net admin to run some monitoring tools (pings) to get some daily charts. Something like Nagios. Just running manual pings is good, but doesn’t really show the trends, if one misses it.