My intention is to start a conversation about proper management and scaling of Chia farming. If some of the below has been covered in the documentation, I apologize in advance for missing it and am thankful if you can point me to it!
I’ve been running a Chia full node since 2021 and recently, with the advent of compressed plots and the coming halving, I’m looking at overall performance of my harvesting and node. I would appreciate any comments and suggestions about my configuration and approach.
Performance examination in this case means answering some questions like:
Am I missing rewards due to slow response times?
Could I reduce hosting costs by down/right sizing my hardware?
Can I improve the steady state costs of my existing hardware?
How should I grow the system?
My hardware configuration was born through the need to generate plots as quickly as possible in 2021 during a mad rush for hardware. I currently have 26 disks with 381TB of real space consumed by plots. I have a healthy, low latency symmetric 1Gbps Internet connection. I have three servers, really prosumer desktops in the following roles:
Full Node: AMD 1950X, 16 cores, 128GB ECC RAM, Nvidia 3060 GPU
→ hosting 26 disks, 20 via USB, 4 via HW RAID
Spare: AMD 2990WX, 32 cores, 128GB ECC RAM, No GPU
On (1):
I had noticed a large increase in SP latency when I tested compressed plots. I was able to get the SP latencies below 1s by using installing a fairly powerful 4070GPU to handle the 381/495TB of k32/c07 plots. However - the SP latency is currently averaging 0.65s with occasional spikes to 1-2 seconds, which seems like things are on the edge of sufficient.
Currently, the full node is running one CPU at 100% 24/7. That suggests to me that the Full Node software is running a single thread at maximum CPU intensity to handle the incoming service requests. This is alarming to me because it may indicate that the Full Node is at capacity while handling requests and may not have the ability to handle any more without some kind of failure. This could explain the spikes in response times, as the single threaded process has no spare capacity. Is there any current means to multi-thread the service handler? Perhaps a configuration option?
On (2):
I did try to run the full node and separately hosting 22 USB drives on a Raspberry Pi 4 on Raspbian Linux. Based on the current loads on an AMD 1950X, this seems to have been a “fool’s errand”, and it was woefully unable to service the load. I’ve recently played with an RPI 5, which is notionally twice as fast, but I believe it is now way underpowered for this role.
If the Full Node service was multi-processing capable, it should be able to scale well on many-core architectures like ARM64 without problem. As a single CPU service it requires a very fast single core CPU
On (3):
The power consumption of my setup is dominated by the full node’s CPU usage. The harvester GPU is consuming about 20W on average, while the single core on the Full Node is using perhaps 150W. The only obvious place for power improvement would seem to be the Full Node.
On (4):
I believe that the proper way to grow the Chia system is to add remote harvesters, each one managing it’s local pool of disks. This obviously works well, as pools have been successful. The question is: How much storage can one Full Node handle? At what point do I need to start another Full Node? In other words: How does the Full Node service scale?
(EDIT)
On a hunch, I did an strace -p <FULL_NODE_PID> to see what system calls the full node process was using. It seems like it may be spinning / polling aggressively, and there are also a whole lot of calls to getpid(). The aggressive polling is normally done to minimize service request latency, but is usually only needed when the latency demands are extremely high. I would expect that a non-polling approach could be used with the Chia Full Node service with acceptable latencies - any opinions?
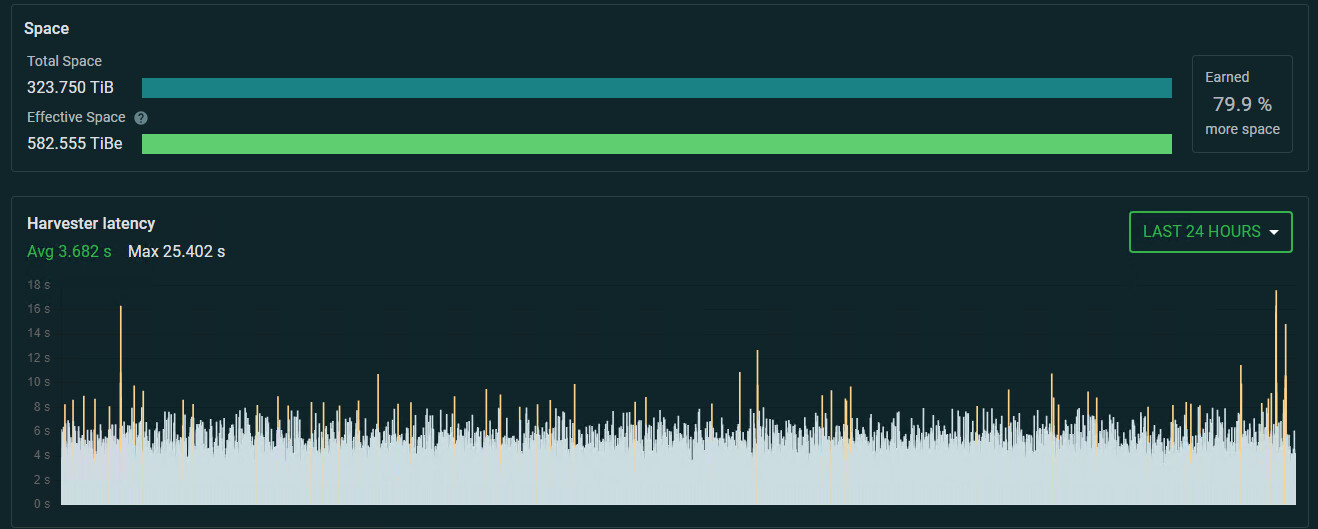
Ronski - In your graph you show SP response times of Avg:3.7s and Max: 25s. This is consistent with what I reported as being too slow for my liking, which is why I implemented the GPU for harvesting. One of my open questions is: What is a reasonable response time for SPs if you want to make sure to not miss rewards?
====== EDIT
Now I see the chart below the first that shows you are getting only 0.3% stale shares, which seems to say that you aren’t missing opportunities for reward at the current SP response times. Is that a correct interpretation?
====== /EDIT
Is there a full node running on this machine? The plots look more compressed than standard chia bladebit, so I presume you are using a pool that provides a better compression?
WRT your comment about “single server doing multiple roles”, I presume you mean to say that there is plenty of capacity on your “lowly i5-10600” in order to negate my concern that there is not enough server performance. *If you are running a full node on this machine, which you would not be if you are pooling, then I suggest the following about your setup:
The Full Node response time will be limited by the single core performance of your CPU, which can actually be quite high for even “lowly” CPUs like yours. In fact, the IPC of that generation Intel I5 isn’t too far from the IPC of my AMD 1950X, but my AMD has a lot more cores. My extra cores do nothing to help if I need more Chia Full Node performance, as it appears that the Chia Full Node code is single threaded. That was the nature of my comment and questions.
Given that the Full Node is single threaded, it will only use one of your cores, leaving all the rest for other duties. However, if there is more incoming load from Chia than your single core will support, Chia services will degrade. The fact that there is extra headroom on your server is an expected consequence of the behavior I reported.
So - in summary - your observation appears to be consistent with mine, though your SP response times appear to be 7x-10x slower than mine. The explanation for that might be any combination of slower GPU, not using GPU for harvester or increased compression versus my k32/c7.
It is running a full node, I’m using Gigahorse C19 plots and on a pool using the official pooling protocol (with GH). I always have the GUI open, even though its not required with Gigahorse.
28 seconds is considered the absolute maximum time, but that includes network transit time as well, there’s no need for really quick response times, sub 20 seconds should be fine, but many will say that’s too slow, all I’ll say is I’m finding blocks, and my average effort is 101%.
Yes, the Chia code does seem to be really poorly optimised and single threaded.
This appears it will be very relevant - specifically the SQLLite and tight loop optimizations:
=============== EDIT
I updated my Full Node (and harvester) to the 2.1.4 release and the Full Node behavior is quite different now. Previously the full node process was pegged at 100% CPU, now it is sporadic and the load average is around 0.4. Previously on 2.1.3, this had tended to go up over time until the CPU was saturated, so I’ll withhold full judgement until some time passes and the load stabilizes, but this appears to be different and vastly improved behavior in 2.1.4 vs 2.1.3.
Another note - I’ve been having stale processes left over after doing a chia stop all -d, one or more of which were holding locks that prevented a restart. This might also be pointing to a bug in the previous code WRT stuck transactions (deadlock) or other potential issues. Hopefully this update also tackled some of that.
BTW - here is the change they made to the Full Node code that fixed-ish the spinning problem: Spin slower `send_transaction()` by arvidn · Pull Request #17166 · Chia-Network/chia-blockchain · GitHub. They changed the sleep period from 10ms to 500ms. This doesn’t really change how this works - it’s a tight loop with polling layered over a SQLLite locking layer to manage their mempool - seems like this needs to be replaced in order to enable multi-processing.
I posted a question to the maintainers to see if they’re open to changing the multi-processing of the event loop in the Chia Full Node code to make it more responsive on lower end CPUs. Note that at this time, on modern-ish CPUs, the Full Node code is near full capacity, so it might actually be a necessary modification if the network traffic increases from here.
=============== /EDIT
After running for several days on 2.1.4, I can now verify that Full Node CPU is down to 60-70% from being pegged at 100% with 2.1.3. Overall system response is much much better and I am not seeing the same spikes in SP response times as before.
I continue to be alarmed at how close to capacity this service loop is - it’s not a long term tenable situation, as there isn’t much headroom left in the FN to accommodate more traffic.
I suspect the short term answer is to limit the peer connections to 40, but that’s a workaround. Ultimately that service loop needs a rewrite.