Hi Max, please, see attach, I think error is happening because this motherboard have an Intel integrated GPU, first time this happen
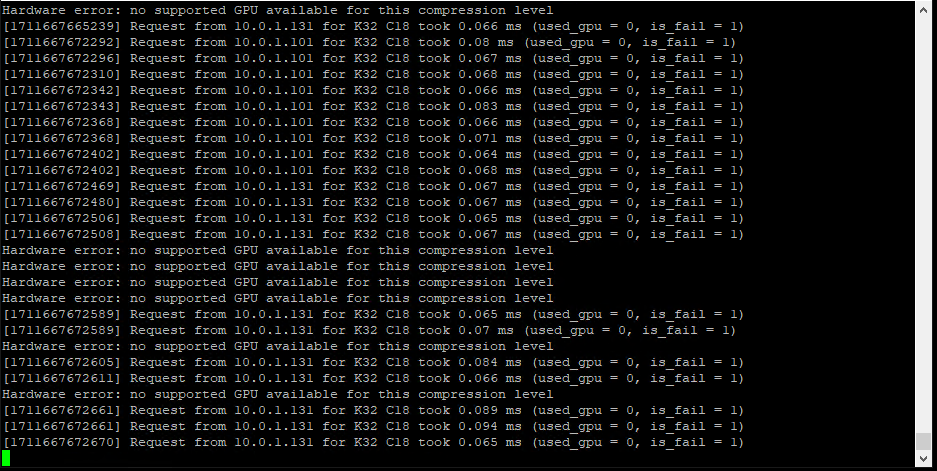
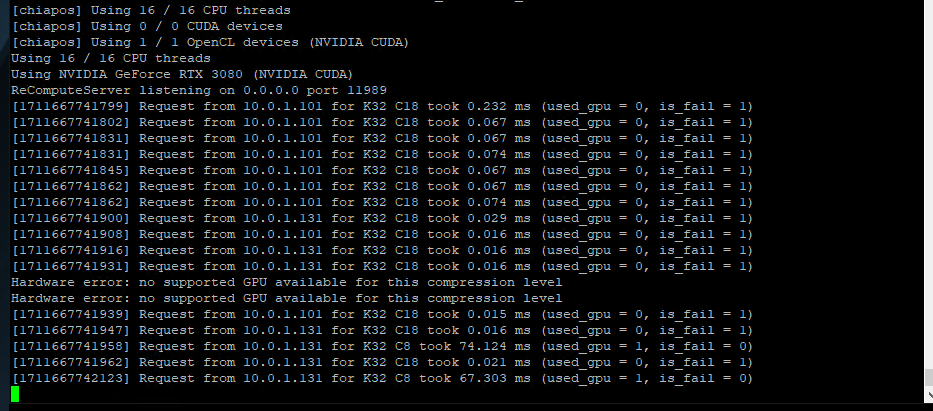
Did you upgrade to the latest recompute server?
yes! everything has been updated, windows has no problem.
In taskmanager do you show a GPU at the bottom of the list? If so how much memory does it show?
.
.This is one of my machines.
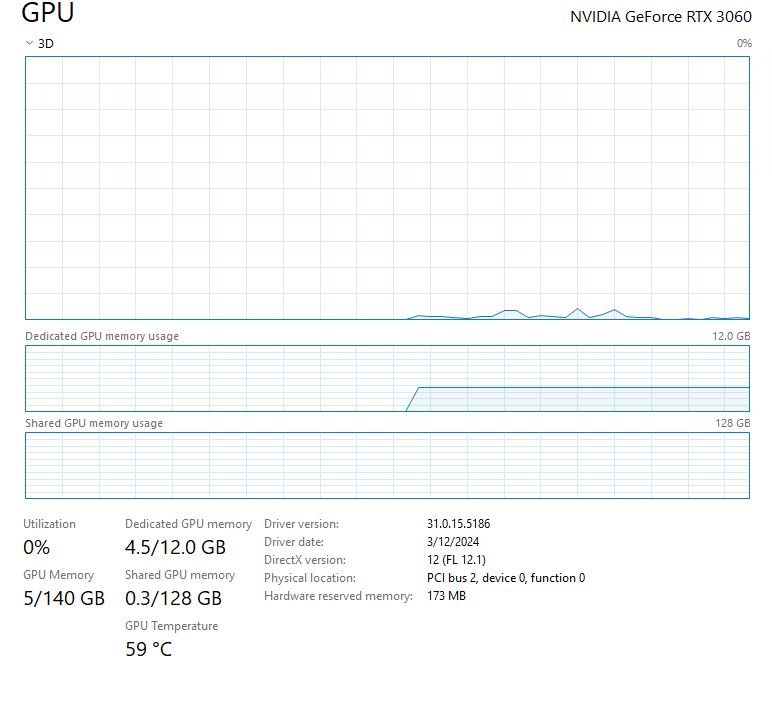
windows is working fine, problem is on Ubuntu I’m running a 3080 but motherboard have an integrated GPU and I think that is the issue.
I have reversed to previous version and everything works fine.
1 Like
Looks like an issue with CUDA, it’s not seeing any CUDA devices, but OpenCL works for some reason.
Did you try to reboot? And what does nvidia-smi show?
Yes, I have reboot it, see what nvidia-smi shows on G33 and G34
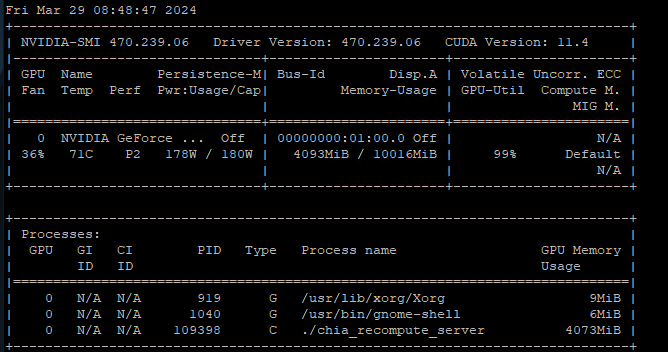
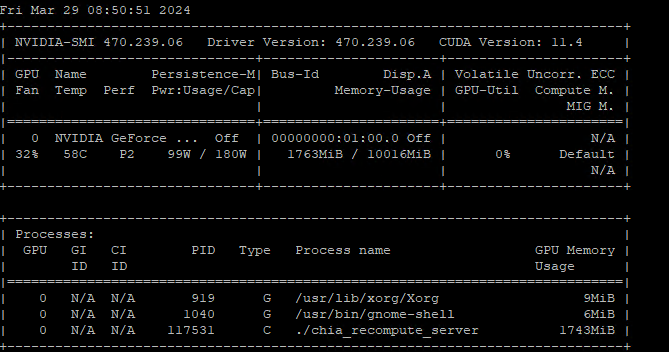
Thats strange that it doesn’t show the card type…
Sorry guys, it was Driver issue, just notice I have 470 and upgraded to 525 and it is working now
Fri Mar 29 09:39:43 2024
±----------------------------------------------------------------------------+
| NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
|-------------------------------±---------------------±---------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce … Off | 00000000:01:00.0 Off | N/A |
| 98% 60C P2 145W / 370W | 4096MiB / 10240MiB | 0% Default |
| | | N/A |
±------------------------------±---------------------±---------------------+
±----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1081 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1140 G /usr/bin/gnome-shell 6MiB |
| 0 N/A N/A 1577 C ./chia_recompute_server 4076MiB |
±----------------------------------------------------------------------------+
2 Likes
Why doesn’t it display the card type?
no idea, it have rtx3080 12gb
I was just looking at your picture thinking the driver version and cuda version were a bit old.
Hi Videce, how did you get chia_recompute_server to work in ubuntu? and is the GPU uncompression being done on the second server not putting extra GPU load on the first one? Thanks
¡Hi!, I’m running Gigahorse recompuete_server on a dedicated PC as farmer with no HDD on this server.
- Install Chia
- Install Gigahorse
- Be sure to have latest Nvidia drivers (default driver will not work)
- In my case, install screen, then: (cd chia-gigahorse-farmer) then run: screen -S recompute
- Now that you are inside recompute screen run: ./ chia_recompute_server
- Run: sudo ufw allow 11989 (to open recompute_server:port
- Use CHIAPOS_RECOMPUTE_HOST=(recompute server address) in all your harvester. if running locally type: EXPORT CHIAPOS_RECOMPUTE_HOST=local (if more than one recompute server, add IP’s separated by a ,
- To exit from screen without stopping recompute server use CRT+a d (like in hiveos shell)
- type: screen -r to go back to recompute screen
- And I think that’s all.
2 Likes
Instead of using screen (used it initially), I created a systemd script, so it runs on boot. This lets me use systemctl restart recompute-script to restart it if needed (Ubuntu). If no harvester is using it, there is very little overhead, so no need to worry about it. Although, if needed systemctl stop recompute-script will stop it (till next reboot).
[Unit]
Description=Starting mmx recompute server
After=multi-user.target
[Service]
ExecStart=/usr/bin/bash /home/llama/mmx/node/remote_compute/mmx_recompute.sh
ExecReload=/bin/kill -HUP $MAINPID
Type=simple
Restart=on-failure
[Install]
WantedBy=multi-user.target
By the way, that mmx_recompute.sh script (in my case) specifies which version of recompute to use, and tees output to a log file. However, it can point directly to chia_recompute_server.
2 Likes
Got it, thanks! I might be making it more complicated in my brain than it actually is for some reason. I initially copied the CA certificate from one server to another and thought that was all I needed then read about it on this forum and chia_recompute_server looks like the answer as my chia1_main server started to throw stale partials so I need to start moving plots to my chia2 server. I only have two servers.
Ok, so I think this should work
Machine A chia1_main RTX4070S 192.168.3.3
./chia_recompute_server
./chia.bin start farmer
Machine B chia2 RTX306012Gb 192.168.3.2
./chia_recompute_server
CHIAPOS_RECOMPUTE_HOST=192.168.3.3
./chia.bin start farmer
Is there any way to monitor how is the Machine B utilized and this process actually working? I try to use nvtop to see if it has any spikes on GPU utilization but it looks pretty flat so far with only 70plots, I’m moving more now.
Thanks
Your both boxes point to box A (…3.3) for recompute (CHIAPOS_…); therefore, your recompute on box B will not be used at all, no need to start it (the box B harvester talks directly to recompute on box A). So, nvtop on box B will be flat.
By saying load balance (the other post) you imply that you want to use 2 GPUs (from both boxes) at the same time. If you want to use just 1 card it is more like centralize load processing (what you have right now). So, which one scenario you want to implement?
Hi Jacek, thanks for going over it. The goal is to have plots that are on Machine B to be processed on GPU on Machine B, and plots on Machine A to be processed on GPU on Machine A. I’ll manage load balancing of plots by moving them between two netapps manually to make sure I’m not getting any stale partials.
Ok, corrected the IP, would this work on machine B?
Machine A chia1_main RTX4070S 192.168.3.3
./chia_recompute_server
./chia.bin start farmer
Machine B chia2 RTX306012Gb 192.168.3.2
./chia_recompute_server
CHIAPOS_RECOMPUTE_HOST=192.168.3.3
./chia.bin start farmer
Thanks
That looks like what you had in mind. Although, for that setup there is no need for CHIAPOS_RE… on box B (if there is no CHIAPOS… env-var, harvester will default to a local recompute server).
However, think about recompute as your friend that will do some extra work for you and again that it is completely independent from your farm setup. What I mean is that if you set recompute to do load balancing, you will need to worry less about how you balance your plots, how GPUs are being used.
So, that would be my preferred setup:
Machine A / chia1_main / RTX4070S / 192.168.3.3
./chia_recompute_server
CHIAPOS_RECOMPUTE_HOST=192.168.3.2,192.168.3.3
./chia.bin start farmer
Machine B / chia2 / RTX306012Gb / 192.168.3.2
./chia_recompute_server
CHIAPOS_RECOMPUTE_HOST=192.168.3.2,192.168.3.3
./chia.bin start farmer
Also, I would run recompute and farmer in separate shells. This way, whether you need to stop the farmer, do some other thing, local recompute will still serve the other box. Basically, because of that I switched to that systemd setup for recompute (don’t need to worry about running it anymore). Also, I think that systemd will restart it, if for any reason it would crash (haven’t see it crash yet, though).