I have 2 brand new PC’s for harvesting (they were brand new about 1.5 months ago and bought for this purpose). They both have Windows 10 Pro installed. No other s/w is installed expect from default s/w provided by the vendor, but not much wasteware (as is per usual for some vendors).
The only thing they do is run MadMax.
The PC’s crash anywhere from 20 mins after power up/start harvesting, to over 2 hours or even over a day. I had to setup a monitor script on another PC to run test-netconnection to them so I get an alert when they become unresponsive.
They’ll sit there happily doing nothing, with no crashes but when using Madmax v0.1.1 (latest version) they start to crash.
Using HWInfo, the CPU’s are aren’t hot (60-70C).
All drivers are up to date and there are no obvious errors in Event Viewer.
As a test, I’ve disabled Intel SpeedStep and Turbo boost and this sorted out one of them, but not the other one. Obviously this hurts plotting time so isn’t ideal.
Just food for thought… If you have an NVMe drive that doesn’t play nice with Chia plotting and it is the OS drive, that will cause the system to crash. My recommendation from what I have read is to not plot to your OS’s NVMe for this very reason. Just giving another possible solution here.
Also on the train of thought surrounding NVMe drives and regular SSDs, they can get hot when pegged to full load. What you will want to do is put a heat sink on them and preferably also have a fan blowing air over them to get exhausted/pulled out of the computer. You do not want the SSDs overheating as they can “glitch out” and cause weird behavior.
Thanks for the feedback. For both PC’s, I’m using an SSD for the OS which isn’t shared with plotting and Enterprise Samsung PM1735 - HHHL Cards. I currently have them in software RAID0 in one PC, but the same issue occurred when I used them without RAID too.
Funnily enough, both PC’s have these HHHL cards in them. The PC that crashes more often has 3 of them and the other one has only 1 of them.
I’m currently doing a RAM test, which is taking hours. Once that’s done, I’ll kick off some plots and check the SSD temp’s…
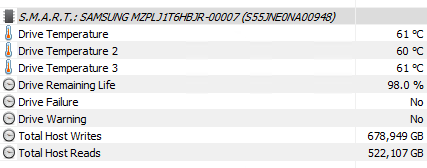
In case it helps, here’s the SMART HWInfo from the harvester which doesn’t crash so much. It’s been plotting for most of today without a glitch
It seems OK.
Unless both PCs are identical, I’d try removing the SSDs and plotting to something else and see if the issue is resolved. There have been reported cases of Samsung (or Samsung based) SSDs having issues and being extremely slow or crashing a system under intense load.
Also, just because a RAM test passes today doesn’t mean that it won’t fail tomorrow. A single bit could flip at random and may cause stability issues with the RAM if it the RAM or system can’t compensate.
Good idea. I have a couple of Micron SSD’s in there, so I’ll plot to them and see if it it’s more stable (unfortunately they’re SATA though, but at least its a good test)
FYI - The PC’s are different. One’s a Z490 and the other a Z590.
There’s just so little information to go on. MADMAX is pretty hard on the system.
A few questions, if you don’t mind:
CPU Model / Cores?
RAM Size?
PSU Wattage?
Madmax settings?
Overclocked?
If it were my pc, I would try to rule out Madmax and find another way to stress the system. Maybe try some long stress test or benchmarking software and see if the system is stable… no idea what could emulate madmax though…
Just in case someone feels kind enough to have a look at this, I logged around 1.5 hours with HWiNFO until the PC crashed.
I honestly can’t see anything obvious in the log at all, which could cause these hangs/reboots. However, the CPU is higher temp that I thought but not critically hot. I checked the last ~20 rows, so just before the crash occurred.
I did this for my two systems and temps cratered to 70-+ degree range under almost any load. For so cheap, it would be a slam dunk upgrade and well worth it.
I didn’t notice those temps further up the list. Certainly when it crashed it was nowhere near 90, but as you say that is flippin’ hot to have ant any time.
So better be safe… New purchase coming up. Thanks
Edit: 2 Water coolers are on order… I hope this is it… Mind you, I already shaved my head. nvm.