greetings!
I had previously suspected that the farm status was not working as expected and opened a thread. Unfortunately no one cared.
I kept testing, I will.
May I ask for your comments?
greetings!
I had previously suspected that the farm status was not working as expected and opened a thread. Unfortunately no one cared.
I kept testing, I will.
May I ask for your comments?
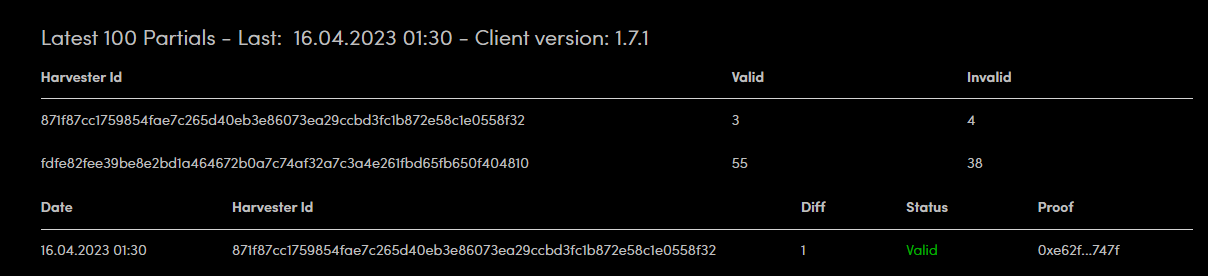
You responded to a challenge in 43 seconds.
You must speed this up to under 30 seconds.
Your losing a large percentage of chances from all those invalid partials.
Possibly a bad drive ( my best guess ) , or to slow node .
Cmon now.
yes i response challenge in 43 seconds and i receive valid.
that is the question.
how is that possible?
Which pool is it? I is possible some of them accept later partials than others.
Other than than there can be al kinds of reasons why the reported time is different from the pool dash. Would have to know a lot about the code of both the pool and Chia.
Some pools also show their reported time of how long it took to receive a partial, that would help to identify the difference maybe.
In any case you are getting a lot of invalid partials, which means something is wrong with your system
i am testing on space pool.
Are you sure you are looking at the correct harvester? You have 2 harvesters and the valid is a minute off so it may have came from the other harvester while this one is definitely stale/invalid and there for the warning before the info line. Your HDDS are falling asleep and it takes 10-30sec to wake them up while on a NAS it can be even longer as it may be starting them in sequence before returning results. If this is a commercial NAS (ex Synology/QNAP) then look at power management for the option to never put drives to sleep and if this is a PC acting as a NAS you can configure drives to never sleep via special tools. I can point you in the right direction if it’s the second just let me know.
i am afraid so i am looking correct farmer and harvester ![]()
no its not nas.
What’s the TX of that proof? I wanted to take a closer look but if this is correct harvester then my next question would be whether the PC clock is in sync with https://time.gov?
As for HDDs sleeping I suggest you watch this video from JM to get an idea of what’s going on behind the scene and fast forward to 20:20 where he goes through SeaChest tool that can be used to adjust the power management on the HDDs. This tool will work on non-Seagate HDDs as well (even USB HDDs or at least it works on them for me under Linux) but you can use it only if you have direct access to HDDs meaning they are not behind a RAID so they have to be either direct attached (ex: SATA, SAS, etc.) or part of a JBOD where HDDs are directly exposed to operating system. If they are not exposed (ex: they show up as a volume that RAID card created) then you rely on the RAID card to control HDD power management. This is one of the reasons why RAID is not advised with Chia unless the RAID card you are using is in IT/bypass mode.
Personally I use openSeaChest and compile it for my Linux harvesters on the harvester directly but for Windows users you can download the binaries from GitHub. Note that below instructions are based on Linux but should work fro Windows just make sure you run it in elevated/admin CMD or PowerShell window after navigating/CD in to the folder where you have your openSeaChest BIN/EXEs:
Get your HDDs handles or hardware path that will be used when addressing each HDD with the “-d” parameter by running “openSeaChest_PowerControl -s”
Now that you have the handle for each HDD inspection the current power settings by running “openSeaChest_PowerControl --showEPCSettings -d <handle of the HDD>”. Note that some HDDs may return more that one handle for each HDD which is the case of WD Easystore which also return SES device with the same S/N so just ignore these additional devices and consider the device with the correct HDD model name/number. Bellow is my output which you want to achieve where all idle & standby values are 0 except for idle A under Current Timer. Typically only Idle A is the slightly lower power mode which still keeps the spindle rotating but refer back to JMs video for more details. The key idea here is to keep the HDD spindle rotating so that it does not have to spin up from 0 RPM which takes most of the time, also a lot of spins down & up cycles will reduce life expectancy of the HDD so by doing this you prolong the life of the HDD at the cost of extra power usage.
Name Current Timer Default Timer Saved Timer Recovery Time C S
Idle A *1 *20 *1 1 Y Y
Idle B 0 *6000 0 10 Y Y
Idle C 0 0 0 36 Y Y
Standby Y 0 0 0 36 Y Y
Standby Z 0 0 0 100 Y Y
openSeaChest_PowerControl -d <HDD handle> --idle_b disable
openSeaChest_PowerControl -d <HDD handle> --idle_c disable
openSeaChest_PowerControl -d <HDD handle> --standby disable
*The last one should apply to both standby Y & Z and if it does not for some reason then use the separate standby_y & standby_z parameters.
The result of each line above should be “Successfully configured the requested EPC settings.” and these settings are applied to the HDD so will survive power down or if you move HDD to another machine.
i am greatful for your support. to be honest you are better then keybase admins!
i guess we have wrong understanding.
I’ve had concerns about my farm working for a while so I intentionally slowed the disks down. I just check the way chia works. because I think something is not right.
it really doesn’t matter to me that a few plots here work, I don’t care because I’ve already tried to make it not work.
The important thing is how something works that shouldn’t work.
plus i have +50 seconds valid.
greetings!
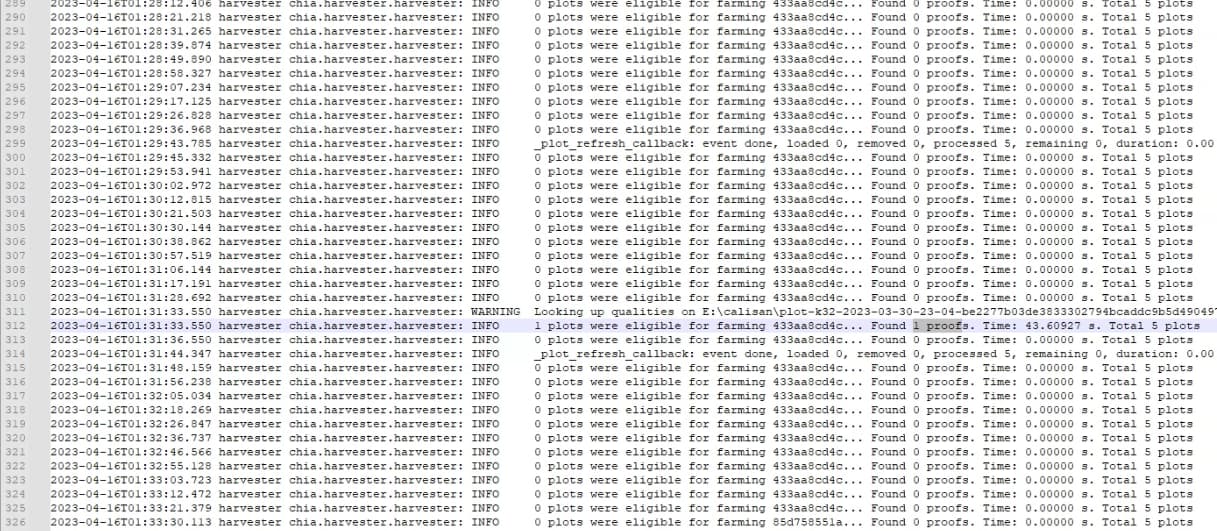
2023-04-16T01:31:33.550 harvester chia.harvester.harvester: WARNING Looking up qualities on E:\calisan\plot-k32-2023-03-30-23-04-be2277b03de3833302794bcaddc9b5d49049705f51756068b6ecdba5b9bfc7bb.plot took: 43.60927152633667. This should be below 5 seconds to minimize risk of losing rewards.
2023-04-16T01:31:33.550 harvester chia.harvester.harvester: INFO 1 plots were eligible for farming 433aa8cd4c… Found 1 proofs. Time: 43.60927 s. Total 5 plots
I forgot to mention that your Idle A should be set to 1 so that HDD switches to slightly lower power usage ASAP and you get some power saving while HDD is not accessed but your spindle is still rotating. If it is higher now you can change it using:
openSeaChest_PowerControl -d <HDD handle> --idle_a 1
Obviously you can disable idle A as well and you will have no power savings at all but I see no point as with idle A = 1 my >600TB farm still scans plots at <500ms per challenge on avg.
Interesting, how are you slowing down your HDDs? According to the information you provided the pool got your proof before log was recorded with the delay.
tons of copy paste. + oldest hard drive.
yes log has delay.
Not sure I understand, can you explain in more detail how you are slowing down the HDDs?
Also, are you using Chia original farmer or 3rd party (ex Gigahorse)?
Lastly, is there AntiVirus and if so have you tried excluding Chia folder and plot location from AV scanning?
ofcourse.
old hard drive 5400 rpm 2.5 inch laptop drive.
when its in farming runing robocopy. its start copy and paste files. because of tests.
another interesting part is, i receive stale 33 seconds and 11 seconds (other topic) but +40 and +50 seconds is approved.
no anti virus, all windows firewall closed. yes offical 1.7.1 full node and 1.7.1 harvester.
here you are offical answer from the keybase… throw ball to another, another person throw ball to another… keep surcle like that…
Ok so there is a lot to cover here. First the “old” HDDs with 5400rpm are perfectly fine and I get <1sec response from my USB HDDs with similar specs.
The reply you received is correct as pools can set whatever rules for stales they like to enforce and typically it will be <25sec so they have time to find a block and if they accepted proofs >30sec old they they are paying you for nothing as proof that old will not year a block.
This is an interesting issue and I think it is not about >30sec valid proofs but some delay on your system that delays the scanning stage looking for proofs. I have not personally looked at farmer source code but consider something like this flow:
Looking at above if proofs are submitted at step 3 and not at the end of scan in step 5 then that would explain why entire scan can end later than proof receipt time. Now if you have some severe delays in accessing HDDs like in your case this would be more visible.
This is the most logical explanation I’ve heard in my entire chia life. however, this plausible explanation needs confirmation.
Note that step 4 could be IO based like scanning additional plots or it can be something completely artificial like AV freezing a process when it scans the executing process memory. Although I’m not a Chia dev I do other software dev and the above flow is what I would implement as you want to return proofs ASAP since they may result in a block. This is also why you have difficulty levels as with bigger farms this approach would generate a lot of proofs to the pool if the difficulty was not adjusted for your number of plots. The above approach also does not consider scanning process use of multiple threads for simplicity sake ![]()
You could try changing your logging level to debug and that will give you much more insights in to what is executing and when although that will also generate a considerably larger log files.
i will try that.
when i see something suspicious i will post it here, even though you are the only one interested in this issue ![]()