Intel(R) Celeron(R) G4930 CPU @ 3.20GHz 3.19 GHz
RAM 8GB
Win 10 nvme 2TB setup win
Case server 35 Hdd 14TB
wired connection
I’m using a another machine and renamed the db to db-1 and the same for the wallet db to db-1. Then Installed 1.3.3 to see how long it take to sync on my end. My disk is 250gb, 8gb memory and 3.4 ghz core cpu for this test.
The wallet already synced up.
Only thing I might say is that the CPU is a little light and you have to wait.
A couple things…
-
Your CPU is very slow, sorry to tell you. That will have major impact on syncing speed, as you can already see on your task mgr CPU graph. On a typical mid range inexpensive CPU, those bumps will just be little mounds reaching up towards the top, not saturating @100% as you see your doing. That may well be the crux of your problem.
-
You say “Win 10 nvme 2TB setup win”. Have to say that tells almost nothing. What is the brand and model? PCI-E motherboard speed? Those specs have major impact on sync speed.
-
Are you doing any other tasks on this same PC whilst syncing?
That CPU has only 2 phys/log cores, so it is not great. Although, it is a 2019 Coffee Lake, so rather modern single core performance. I think that CPU is saturated, as he started syncing from scratch, so one core is taken by start_full_node dispatcher, the other is just cranking blocks. (On my box, during the first half of syncing from scratch I also have all cores saturated.) Although, this means that the sync process will take really long time, and potentially during the light dust storms it may not have enough horsepower to sync.
Instead of syncing from scratch, download db either from https://www.chia-database.com/ or https://www.elysiumpool.com/.
In that Full Node / Connections sections, how many peers do you have? On your screenshot there were 6 Full Node lines, but do you have total of 8 or rather a lot? If you have “a lot” you need to restrict your number of peers down to 10 or so, as otherwise this is the main problem for syncing on a slower CPUs.
–This– is the issue that will continue to bedevil his node going forward. –Now– he just can’t get caught up and so has no functional node to be able to farm. So what’s the point of wasting electricity/time/effort?
He might as well face fact, and fix the issue now (weak CPU), as it will not get better just bemoaning the fact.
1 Like
During the initial syncing, the brunt of the work is on sub start_full_node cores that crunch blocks. The fewer those cores, the slower the process. So, IMO there is really no point to sync from scratch (a week? with just one core crunching blocks), but rather download db.
However, when the box is up to speed, the choking is not really the brute force of those extra cores, but the main start_full_node dispatching process. This process will have more headroom if number of peers will be limited to 10 and potentially when blockchain db is converted to v2 (I would also like to move dbs off the OS drive).
To get those things done is just a couple of hours (download db, convert to v2), restrict nodes, and wait for another hour or so.
I am not saying that the box is a top of the line (I would buy another 8GB or 32GB RAM today), rather that he potentially may still get by, at least for some time. My take is that his box is at least as powerful (in some respect) as RPis, and those somehow manage to run full nodes.
Of course, another option would be to switch to FlexFarmer, and be done with this start_full_node nonsense.
So, I am not really disagreeing with you, but rather would want him to get up to speed now, and have more time to think how to upgrade his box.
Also, kind of a rather dumb math, but. If he can pull off syncing close to the current in a week, that means that his box can process about 40 weeks of data in 1 week, so has room to run ~40x bigger dust storm comparing to what is running right now. It may be that the current dust storm is knocking his box off right now, though. Limiting peers down to 10 may help with this problem. (During the initial sync, the number of peers may be irrelevant, at least during the initial phase.)
CPU upgrade first step…
I really thank everyone for their response, but what did these things you said have to do with my problem? I have two systems with specifications ram 64 cpi i9 10900k z490 mb nvme2tb 2x Corsair Force MP600 These were plotting systems And my farming system is for Chia, which has 41 hard drives installed on the motherboard, and I do not think a strong system is needed for farming. But in the end, I ask the development team to find a solution to this problem, which is the worst problem, which is to sync this program, and save us.
We all know that the code around syncing is bad (i.e., start_full_node). And we all know that Chia at least for now has no intention to get it fixed (at least short term). The main problem is that this is rather a complex code and small localized fixes will not do anymore (they tried in Nov with v1.2.10, but it didn’t improve much) and rewriting that code will be a big task.
As far as your setup, if you have that i9 10900k box, why do you bother to sync from scratch on that Celeron? Your i9 will fully sync in less than 30 hours, and you can move db to your Celeron (if you don’t want to download).
As I wrote, my take is that your Celeron box has problems syncing due to the number of peers, and I asked about more details. So, from my side, I am a bit confused about what you would like to accomplish.
Please understand we are, in fact trying to address your problem. We can only address what is practical and doable to resolve issues that we have little to no control over. We are not the Chia dev team, or have any sway directly over their code.
Your beliefs may be unfounded or not. Take our collective advice, and then, certainly proceed as you see fit. The results of your choices from those suggestions are up to you. Good luck!
1 Like
Thank you, my dear friend. I thought that at least the development team would think or listen to our words, which we have spent a lot of money on at the peak and we are extracting with great difficulty. I now realized that the data file can be downloaded from the site and replaced in the data folder, I did not know. Thank you very much to all my friends. Just one more question, should I download the data file of series one or two?
Doesn’t really matter. Your i9 box can convert v1 into v2 in less than an hour. So, it is more a preference, whether you want to do a browser download (getting v1) or torrent download (getting v2). You want to have v2 on your Celeron box before moving forward.
(@elysiumpool it looks like your SSL cert is broken.)
1 Like
How do I make it? 

Not sure what is the question.
convert v1 into v2 in less than an hour. How can?
On your i9 plotter, you will run (modify paths, and file names)
chia db upgrade --input v1.sqlite --output v2.sqlite --no-update-config
Once done, you can move v2 to your Celeron box, and modify config.yaml to point to v2. Once you start chia, just wait about 30 mins to 1 hour to get it settled down. Let us know how many peers you have in your Full Node / Connections section. Most likely, you will need to limit that number through your config.yaml.
By the way, that means that your plotter needs to be on v1.3.x as well.
Actually, your Celeron single core performance is about 30% lower than i9. Also, that upgrade process is a single core program. Therefore, your Celeron may do conversion in about an hour (if NVMe is not throttled being the OS drive). Yeah, 8GB is not going to provide any db caching, so that will slow it as well. Still, my take is that it should be less than 2 hours.
@Starcoin
Regarding your CPU usage graph:
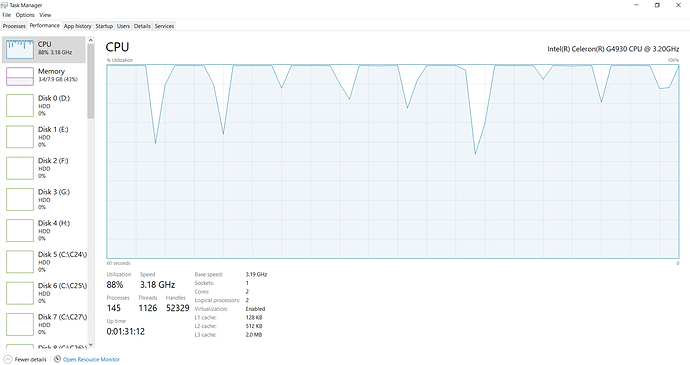
What is consuming your CPU cycles? What is pinning your CPU to the ceiling?
Click on the “Details” tab and sort by the “CPU” column.
Syncing from scratch on two physical cores, as such one core is fully utilized by start_full_node dispatching process (network, db, block processing dispatch), the second core is also start_full_node, but block crunching process (just fully maxed one core per start_full_node - different code path - the more of those the better, but his CPU has only 2 cores).