I am getting this weird result on my 3970x with 128GB RAM plotting to 3 1TB 970pro and a MP600 pro. 3 plots stopped at 96.25% for the second time. I deleted my first plotting attempt with this machine and now it just happened again!
The other plots are still running. Any idea what caused this?
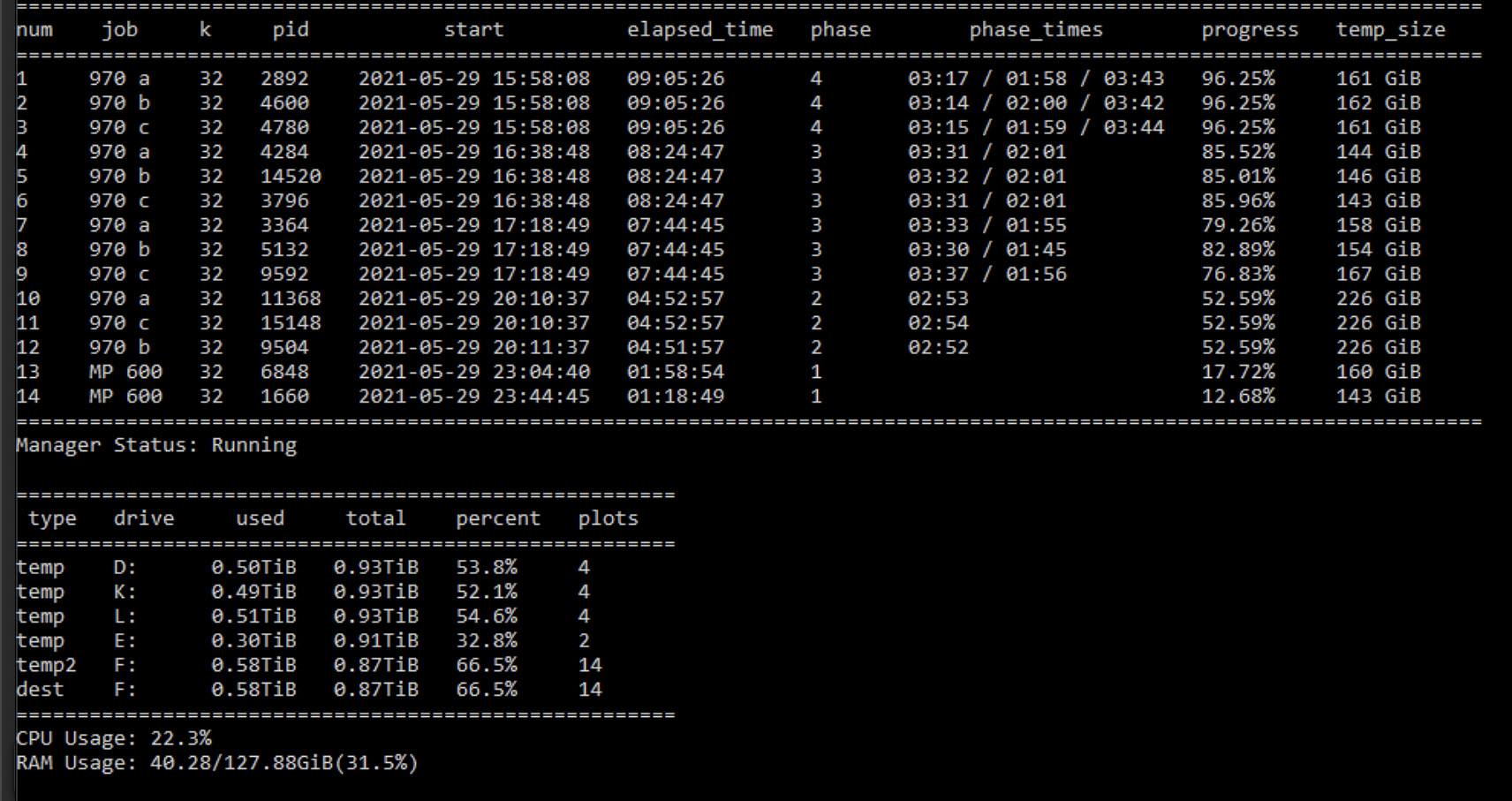
here are my swar settings
- name: 970 a
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: D:\
temporary2_directory:
- F:\
destination_directory:
- F:\
size: 32
bitfield: true
threads: 6
buckets: 128
memory_buffer: 4000
max_concurrent: 4
max_concurrent_with_start_early: 4
stagger_minutes: 40
max_for_phase_1: 2
concurrency_start_early_phase: 3
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false
- name: 970 b
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: K:\
temporary2_directory:
- F:\
destination_directory:
- F:\
size: 32
bitfield: true
threads: 6
buckets: 128
memory_buffer: 4000
max_concurrent: 4
max_concurrent_with_start_early: 4
stagger_minutes: 40
max_for_phase_1: 2
concurrency_start_early_phase: 3
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false
- name: 970 c
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: L:\
temporary2_directory:
- F:\
destination_directory:
- F:\
size: 32
bitfield: true
threads: 6
buckets: 128
memory_buffer: 4000
max_concurrent: 4
max_concurrent_with_start_early: 4
stagger_minutes: 40
max_for_phase_1: 2
concurrency_start_early_phase: 3
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false
- name: MP 600
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: E:\
temporary2_directory:
- F:\
destination_directory:
- F:\
size: 32
bitfield: true
threads: 6
buckets: 128
memory_buffer: 4000
max_concurrent: 4
max_concurrent_with_start_early: 4
stagger_minutes: 40
max_for_phase_1: 2
concurrency_start_early_phase: 3
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false