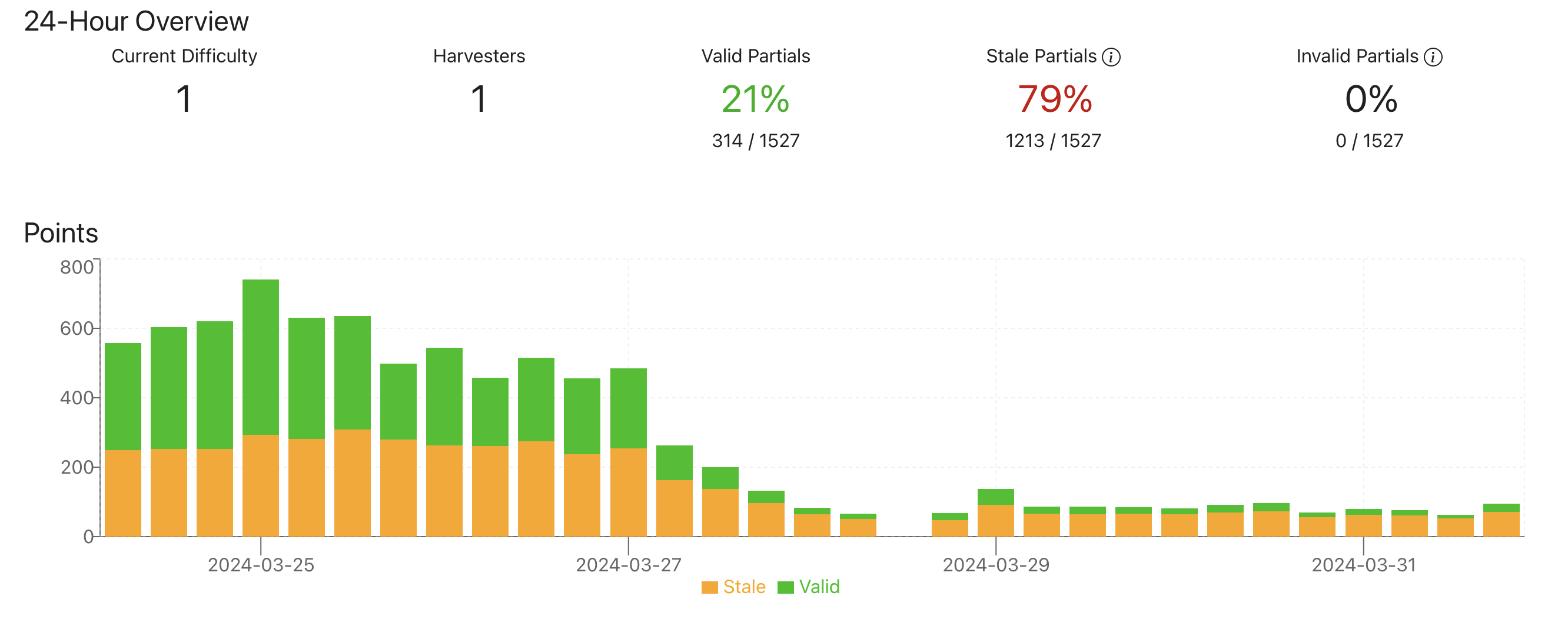
I’m experiencing an issue with an unusually high rate of stale partials (around 80%) in my farming. I have only noticed it since reduced payouts from Spacepool. Below, I’ve outlined my setup, the problem, and the steps I’ve taken so far.
Harvester/Full Node: Running in a container technology (CT) environment (DELL R620), provisioned with ample RAM and CPU resources.
Storage: Plot directories are bindmounts of drives mounted to the Proxmox VE via HBA with a SAS expander, ensuring what should be efficient disk I/O. Currently I have 50TiB.
Network: The connection between my router and the harvester is sub 1ms, operating over a high-speed fiber internet connection (not port forwarded).
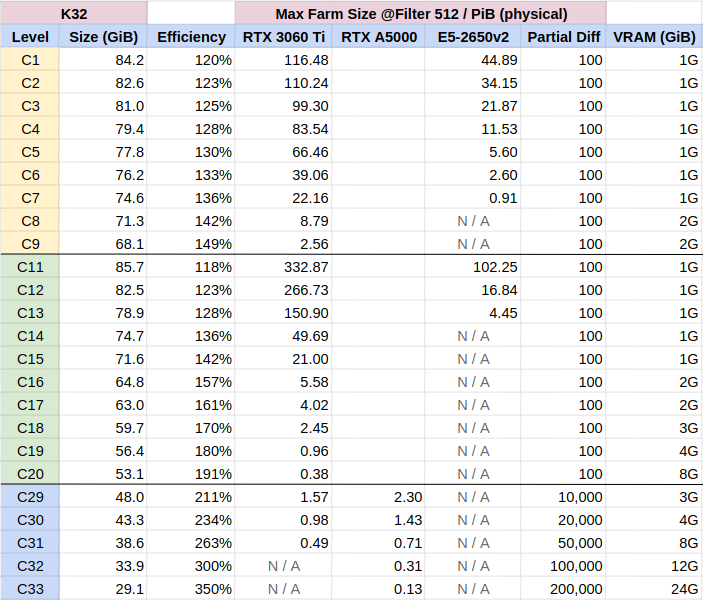
I recently re-plotted to C7 with BB on a separate machine. I’m thinking this is what exacerbated an issue perhaps already present. Previously I was getting some rewards at least.
Problem: Despite what seems to be a well-optimized setup, I’m seeing an 80% rate of stale partials, significantly impacting my farming rewards. This issue persists even after ensuring there are no apparent bottlenecks in CPU, RAM, or disk I/O, and after addressing potential network latency issues both internally and to the internet.
Chia log shows lots of warnings about lookups taking 20-40 seconds (instead of optimal sub 8 seconds)
Steps Taken:
Separate plotting and harvesting operations on different machines to prevent resource contention (plotting has finished a few days ago in any case)
Ensured the harvester and all related systems (Proxmox VE, container environment, HBA/SAS setup) are configured for optimal performance, with sufficient resources allocated and no virtualization overhead impacting performance. Currently 8CPUs which sits static at ~27% utilisation. 8GiB RAM at ~20% utilisation.
Some older HDD drives in use, but checked all SMART passing
Monitored system load, disk I/O, and network performance closely, without identifying a clear bottleneck.
Was running chia-blockchain 2.1.4, now updated to 2.2.1.
Just seen this in the log “WARNING No decompressor available.”
I’m using CPU, not GPU. I notice now that this page suggests GPU is required for C7. Is this a hard requirement? If so, this is a nightmare. I plotted C7 in RAM after buying a huge amount of RAM for the server, and assumed farming would be trivial by comparison, in terms of resource requirements. I actually have a handful of C5 on there. Which might explain why I do get a rare valid partial.
Is there anything I can do to farm C7 without adding a GPU to my 1U server, which will obviously be difficult, and add unnecessary cost. Especially after going the route of RAM plotting.
OK it seems to be CPU resources. I have cranked up the CPU allocation to 20 and decompressor_thread_count: 20.
I’m seeing quicker lookups now. It just wasn’t obvious before because I had limited threads available and that made it look like CPU I had allocated wasn’t being maxed to 100% giving me a false sense of security. I’m guessing the bottleneck was making a backlog of decompression requests and hence the “unavailable” warning. I’m no longer getting that warning.
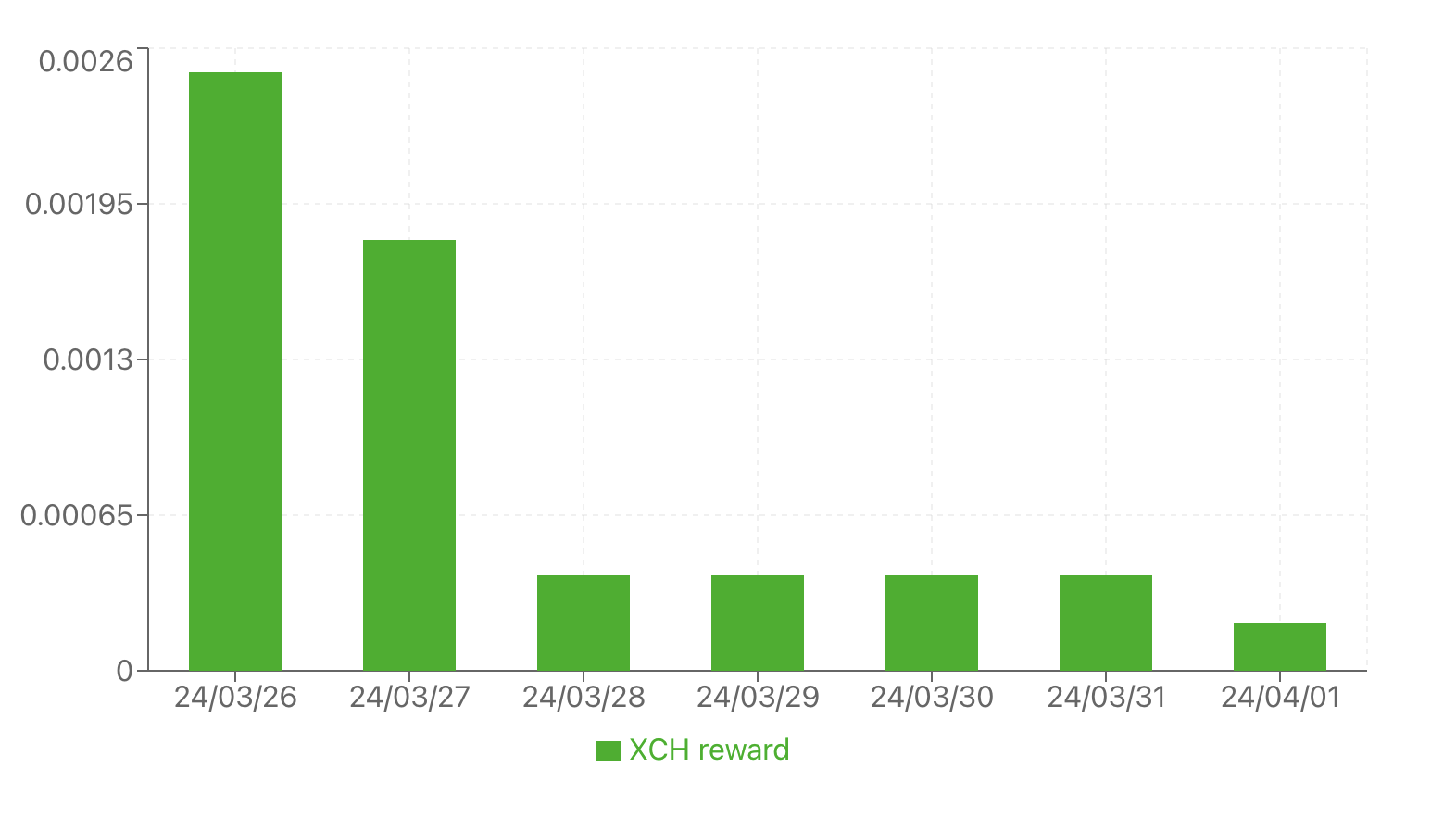
Lookups are taking ~10-20 seconds which is still a bit slow (though, much faster than before). Spacepool is starting to recognise my total plot size. Prev reporting 3TiB of 50TiB, but now climbing.
You’re going to have fresh issues once the filter halves on 13 June, it means the workload will double.
If you only have 50 TiB is it even worth running? I can’t see a Dell r620 being very power efficient, it’s probably costing more in electric than your earning.
I have solar so that helps a lot. I can strap in a GPU for farming with a riser cable, I suppose. It’s just making the cost of farming (along with the power, and plotting machine costs), untenable. Not to mention it’s $200 bucks per drive if I want to increase my netspace.
Really trying to make this work but it’s starting to feel like a sunk cost fallacy.
How does adding more net space help with economies of scale here?
Is GPU harvesting for C7 that much more more efficient? Maybe I just need to grab an old budget gaming PC off Marketplace and slap my SAS HBA card in there. My JBOD is external.
Getting waaaay over capitalised and disenfranchised TBH.
C7 was never meant for CPU farming (C5 is CPU sweet spot). Seeing you only have 50TiB I get it that adding a GPU does not make sense, in the end it is all about OPEX & CAPEX.
Thanks for the links. I guess we have gone full circle and are now PoW. Definitely lots to consider.
Seems a long way from the original sentiment of the project. This arms race too is forcing people to continually re-plot, which in and of itself is mental.
Not entirely PoW though, it’s sort of halfway, and actually more efficient than adding more discs, but obviously the replotting is power intensive, although GPUs have made it substantially quicker.
I’ve now plotted five times, OG, NFT, BB C7, GH c19, GH c30. Can’t remember how long the first two took but it was a long time, especially the OG plots. but the other times it was about a week each.
We will have another replot coming up in a year or so as another compression resistant format is being planned.
What do you mean “compression resistant” - Are you saying compression is undesirable and Chia are trying to discourage it by creating a compression resistant format that will be mandated? I would kind of support that TBH.
{kind=link}