I’ve seen several other topics which are similar in nature, but so far I haven’t seen any solution yet. I feel like this isn’t just an issue of poor hardware performance. I am using port 8444 and am running chia 1.3.4 In the past 4 to 5 months of mostly non-stop syncing, I my local system’s block height gas gone from ~2,5,000,000 to 4,610,000. At its current speed, it will likely finish syncing in about 1.5 days. To start out, my system specs are as follows:
System:
Dell PowerEdge T300
OS: Mint 20.2
CPU:
1x Xeon X3363 @ up to 2.83 GHz; 1 physical CPU, 4 physical cores, 4 logical threads.
CPU cache:
L1 data: 4x 32KB
L1 data: Same as above
L2 unified: 2x 6MB
RAM:
2x 4GB moduels of DDR2, 667 MT/s (Total 8 GB)
GPU:
AMD Radeon HD 8570, 1 GB onboard RAM
Storage:
4x 500GB HDD in a RAID 5(?) (The total capacity is 1.5 Tb and it can tolerate the loss of any single drive, and can be rebuilt from any 3 remaining disks)
It is using a Dell PERC 6/i Adapter hardware RAID controller with 256 MB of onboard cache memory which is connected on a PCI-E bus. I have benchmarked its read rate at 147 MB/s with 12 ms latency
Internet: 2x Gigabit Ethernet controllers (independent of each other) built into the mobo. I just checked their speed with ookla and it is listed as getting about 200 mb/s down, about 400 mb/s up (yes, its higher, its not a mistake) with 4 ms latency. (interestingly enough, I am using the second Ethernet port on this thing to supply an internet connection to another computer nearby, and that computer can consistently get speed tests with 900-1000 Mb/s up and 900-1000 Mb/s down, and gets comparable speeds in real world workloads. (It is somewhat newer, but not nearly as robust or high end for its time, which makes sense because its just a desktop and not a server)
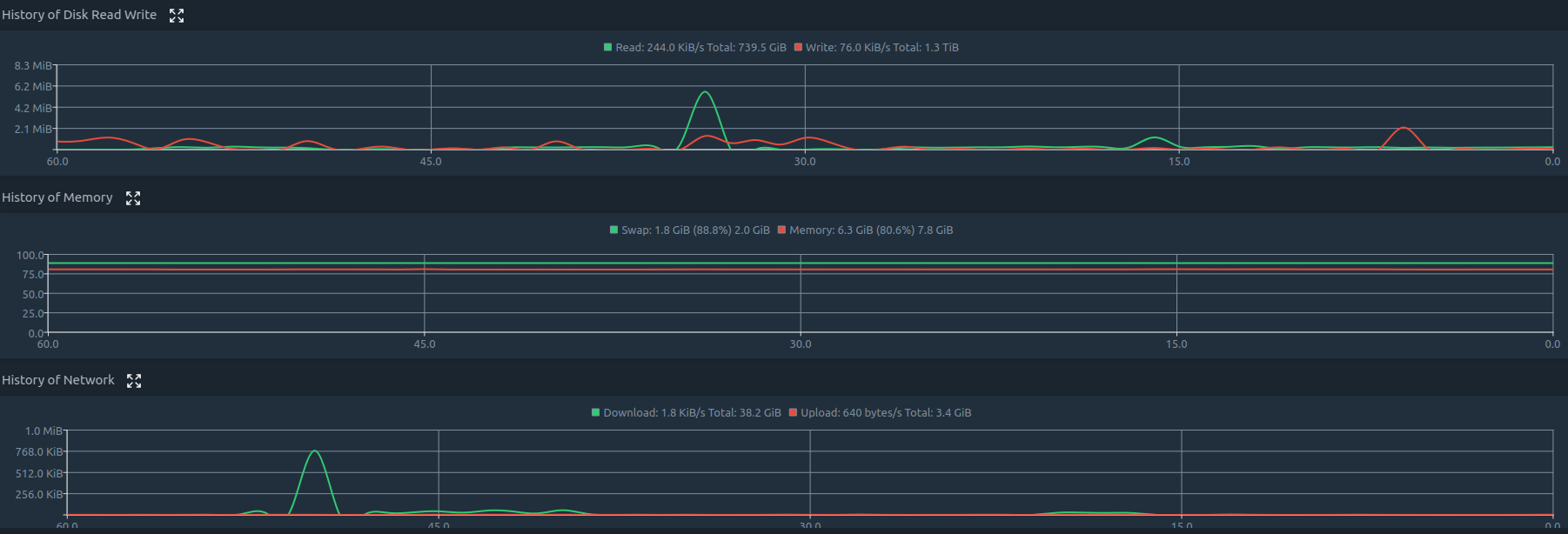
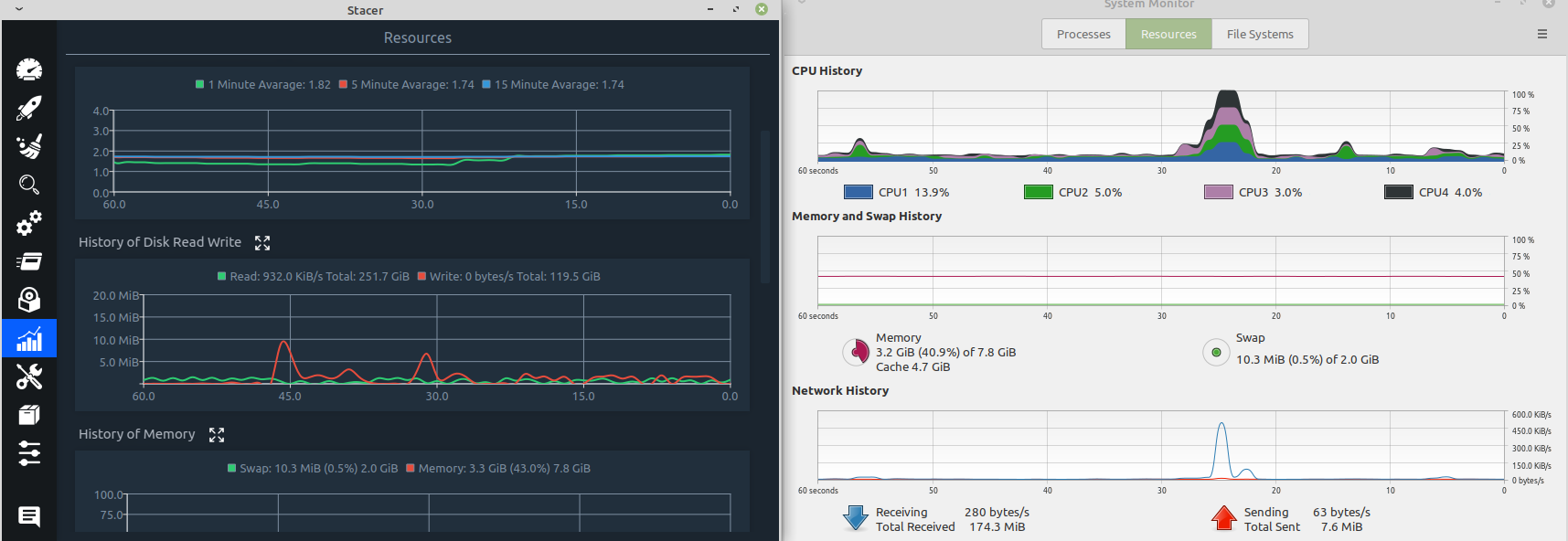
I have been running this server for most of the semester, so around 4-5 months almost non-stop. Pretty much any time I have the server powered on, the chia client is also running. current uptime is 29 days. It seems to process about 3 days of transactions ever day. The weird thing is that it seems that most of the time is spent not doing anything obvious. There are brief periods of time when all CPU cores are fully utilized, but most of the time they are not. Likewise network upload and download utilization are often very low, usually under 1 MB/s. RAM veries, but right now 75% of the RAM is in use, with the remainder being used as cache. The swap partition (only 2GB) is about 80% full, but normally its around 20% when its just Chia running. I would think that would indicate the problem is with the HDD array, and while it does seem to be more or less constantly active according to the indicator on the physical machine, it doesn’t look like its either working on one MASSIVE file or MANY tiny ones either as the read/write rate at any given time is mostly up to 200-400 kB/s, and hardly ever peaks above 4 MB/s, and there is plenty of time where it doesn’t seem to be reading or writing at all, yet I can HEAR the heads moving so its doing SOMETHING. I just cannot figure out what the bottleneck is here.