I can attest to this, currently have ~2000 plots online, all linked over NFS.
So my current setup is a VM for the farmer (and full-node). It has multiple linked NFS shares locally which it farms and these are spread out over 4 different machines.
It’s still working fine and I am answering 99,95% within time. I do also have everything hooked up with 2.5Gbit and 10Gbit and they are fast machines.
But as plots increase it becomes more and more obvious that a harvester runs through the list it has sequentially, so if the list grows it will start to take longer. But worse, if a linked system responds a bit slower then the others, you’ll get a lot of slowed down searches.
In the future I’ll move the boxes that are going to hold the most plots to having their own dedicated harvester processes. The way I see it, currently it’s this:
Farmer → harvester → do all the looksup
It’ll then become:
Farmer → harvester → do it’s own look ups
→ harvester → do it’s own look ups
→ harvester → do it’s own look ups
So parallelism will increase and thus lower your times vs running the harvester from a single box. So as I’ve learned, NFS or linking NAS shares even itself isn’t the issue, but it will still limit you speed wise in the end.
Thanks! Totally agreed and I have figured it that way. Just be curious, if there any way to monitor these remote harvesters? I know GUI can have a total size of plots but if we all set it as remote harvesters, then how we can know how many plots we current have? All Appreciated your help! @codinghorror
On the harvesters themselves, in the .chia/mainnet/config/config.yaml file, change the log level to info, and then watch the logs… I use tail -F ~/.chia/mainnet/log/debug.log | grep -E "proof|WARN|ERR" and either keep the window open, or allow ssh access to the harvesters and monitor them from elsewhere.
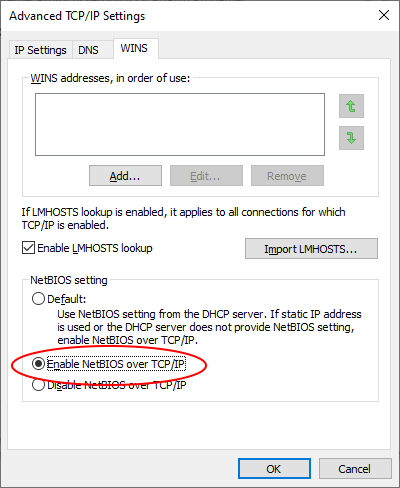
Some people have seen massive improvements op problematically slow mapped NAS fileshares when they re-enabled NETBIOS over TCP/IP (in the ip4 advanced settings)
As you increase the size of the network shares the times go to pot. I got 3 x DAS drives for 12 HD drives (think NAS connected via USB) and 8 x SAS drives in PC.
Also windows SMB share from a Windows PC where much better than a NAS but still the PC SMB share become a problem once I got pass 500 plots.
Yeah that’s consistent with my experience. Plus, if you read the above topic, you’ll see I had the bright idea, mid-way through the project, of putting all the plots in a single folder on the NAS and whooo boy was that a disaster.
Hi Guys,
Sometimes the time is less than 1s and at times its ~1.5s for the 3 plots. Is this normal?
This is a cloud instance with 16TiB volumes attached.
2 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 0.18815 s. Total 640 plots
1 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 1.01484 s. Total 640 plots
3 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 1.58773 s. Total 640 plots
0 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 0.02204 s. Total 640 plots
1 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 1.02178 s. Total 640 plots
0 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 0.02728 s. Total 640 plots
2 plots were eligible for farming 1b4133310a... Found 0 proofs. Time: 1.08672 s. Total 640 plots
And then there is this. 3 plots were eligible for farming 5b8bcd87cd... Found 0 proofs. Time: 0.15986 s. Total 640 plots
Should I be worried for more optimization or thats ok?
(venv) ubuntu@ip-172-31-31-55:~/.chia/mainnet/log$ grep -i 'Looking up qualities' *
debug.log:2021-05-20T20:23:59.017 harvester chia.harvester.harvester: WARNING Looking up qualities on /chia/farm-vol4/farm-1/plot-k32-2021-05-13-20-05-8398fdd068fda3c92b5895b96ae685637457e00b90dfaf4dd4dd69b992d29ae9.plot took: 5.217837572097778. This should be below 5 seconds to minimize risk of losing rewards.
debug.log:2021-05-21T03:30:27.920 harvester chia.harvester.harvester: WARNING Looking up qualities on /chia/farm-vol4/farm-1/plot-k32-2021-05-17-10-46-3d6431ca4031056e08d19842214428d9e7f730712d81f72831020a4074b45059.plot took: 5.181518793106079. This should be below 5 seconds to minimize risk of losing rewards.
debug.log:2021-05-21T13:03:59.525 harvester chia.harvester.harvester: WARNING Looking up qualities on /chia/farm-vol2/Farm-1/plot-k32-2021-05-11-13-15-98b0fdd6c12db903b85e4e7198938bd200be9c952e9ea93310ca071af234dfdb.plot took: 38.454846143722534. This should be below 5 seconds to minimize risk of losing rewards.
debug.log:2021-05-21T13:03:59.530 harvester chia.harvester.harvester: WARNING Looking up qualities on /chia/farm-vol4/farm-1/plot-k32-2021-05-13-20-43-da69d9c96a23965487213941596f9973606f16f394d9b10038842f9436336f0a.plot took: 38.460407733917236. This should be below 5 seconds to minimize risk of losing rewards.
debug.log.3:2021-05-16T09:01:53.246 harvester chia.harvester.harvester: WARNING Looking up qualities on /home/ubuntu/chia/farm-vol2/farm-1/plot-k32-2021-05-11-19-37-c34c772ae8feafda8026e78a886c7bc0117e89d3b6db567e45d6cd2709d353e9.plot took: 10.81737756729126. This should be below 5 seconds to minimize risk of losing rewards.
debug.log.3:2021-05-16T09:24:37.301 harvester chia.harvester.harvester: WARNING Looking up qualities on /home/ubuntu/chia/farm/farm-1/plot-k32-2021-05-09-09-51-372d1f88d664eee4318f59e452a17e6398ec6ba82befc855c8b036a6a404975a.plot took: 8.997605323791504. This should be below 5 seconds to minimize risk of losing rewards.
debug.log.3:2021-05-16T09:32:19.421 harvester chia.harvester.harvester: WARNING Looking up qualities on /home/ubuntu/chia/farm-vol2/farm-1/plot-k32-2021-05-11-18-30-53e01aff404cd397ad1121243c25ce010e4c0d2657bf302b9a54cd6f12866e92.plot took: 13.647049903869629. This should be below 5 seconds to minimize risk of losing rewards.
Want to bring my contribution to this topic for all NAS users. I am farming for 3-4 weeks now on a Synology 1821+ with an SHR raid level, 5x18TB WD gold (42% filled) as one drive, shared in a network. Farmer runs directly on the Syno with extra sufficient cores & RAM. More drives & extension modules are to add soon, but I doubt I have to overthink my whole 5 years farming strategy.
I read of possibile issues with NASes before but thought this was due to a low quality / underpowered / misconfigured NAS. Unfortuately it seems not to be the case. I am investigating this behaviour now with (only) 260 plots since I get occasionally warning messages like this :
WARNING Looking up qualities on (path to file on Synology) took: 10.319631099700928. This should be below 5 seconds to minimize risk of losing rewards.
If you want to see how your NAS farming is doing adjust your logging levels to INFO and look for the time messages.
I am interested in your strategy on how to farm with bigger NAS setups. My next steps are now:
Activate NetBios on TCP/IP v4 (see what happens)
Split the one big drive into smaller ones (see what happens)
Get rid of SHR Raid (see what happens)
Get rid of Synology and go the USB way (I hope not having to do that, since I love the Synology drive information & software features)
Synology does have a WSD deamon (wsdd) running normally I believe, so enabeling NetBios over TCP/IP should not be necessary. This was more for those NAS’s that do not have wsd, and therefore still fall back to SMB1 for the discovery (which as far as I read was unfortunately left out of SMB2/3)
My latest on this. I reconfigured my network a couple weeks ago to separate farming and plotting traffic. I really helped with the issues presented while plots were being uploaded. But as time went by, my search times slowly began to climb. I currently have two NAS running and were being monitored by one farmer/harvester. I could see that it was going to be a problem. Yesterday I setup the docker version of Chia on the Netgear ReadyNAS as the first test. It has 155 plots and growing. It is currently running searches in .01 - .03 seconds. Much better than the searches over the network. The other NAS is currently still being farmed over the network. It is monitoring 76 plots on a Synology and searches take anywhere from .07 to .50 seconds. I will be setting up chiadog (in docker) on the ReadyNAS today. Once I feel I have a good method to set these up, I’ll do the synology (and the other synology when it comes time).
I believe IF you would have had the correct proof for that plot it would show some more logging. This is just logging that you had a chance (but not that it found it) and that your changes are less then ideal since response time is too long.
So I don’t believe you’ve lost anything yet, but yes, it’s important to get a handle on it.
Running a NAS infrastructure can certainly be done, or rather, running over file shares, but it will inherently slow down after a while like I detailed before.
That said I currently have ~2400 plots running over NFS. Single Full-Node/Farmer/Harvester VM which only has NFS links to 4 other hosts which all have USB disks shared over NFS. As long as you take care of this, no disks are full and have a sufficiently fast network (so that one transfer doesn’t fill up a link somewhere) it works fine and my average response time according to Chiadog is 0.75s.
Oh…you are Intermit.Tech? I’ve watched you YT videos by coincidence
No, not yet lost, but everyone with a NAS as a farming solution should be close watching those numbers. I am trying a few things out the next days, to see what helps.
 topic, you’ll see I had the bright idea, mid-way through the project, of putting all the plots in a single folder on the NAS and whooo boy was that a disaster.
topic, you’ll see I had the bright idea, mid-way through the project, of putting all the plots in a single folder on the NAS and whooo boy was that a disaster.
