Ah yes, yes, I am! 
And I fully agree, NAS or rather NFS connected shares can work fine, but you do have to keep an eye on it. Have a share that’s full, it’ll mess up the whole system for instance!
Ah yes, yes, I am!
And I fully agree, NAS or rather NFS connected shares can work fine, but you do have to keep an eye on it. Have a share that’s full, it’ll mess up the whole system for instance!
This has been quite the thread! I discovered it when I began noticing my search time warnings. I have pinpointed it to the cause:
When my plotting finishes and is transferring the plot to my storage, it is transferring at my drive’s full speed (200MBps) and so the drive has a tough time keeping up with queries. I do have an 8 bay nas that does fine when it is not writing to disks. I also have a usb external which exhibits the same behavior. So it isn’t just us nas folk that are so lucky. I think a possible solution would be to limit the transfer rate to the drive. I could do this by plugging my node into my network through gigabit instead of 10gbe but then that connection would be saturated. I guess I have to look into having a separate harvester along with this approach unless I can find a way to limit the transfer of my plot to my drives. I may be able to do this in my switch by adjusting the quality of service.
I did verify this was the issue by pulling up the logs right before the transfer was initiated and then after it completed. Every plot that passed filter on that disk threw up a warning.
Hope this helps someone!
You could try some software traffic shaping solutions such as
or
(I have no experience with these)
If you are using Cygwin Linux utilities or running Linux native you can use the bandwidth limiting capabilities on rsync to throttle the bandwidth in use
Ah yes, I forgot about the application level. On windows you can use the /IPG parameter in robocopy to specify the “Inter Packet Gap”. Robocopy copies packets in 64KB blocks. With the /IPG you can force gaps (in miliseconds) between consecutive blocks so as not to saturate your network.
Thank you for your help! Looks like I have some research to do and with some direction now. Currently on windows because my new workstation seems to need specific drivers to install linux. Spent some time trying and decided to revert to windows and try again at a later time. Traffic shaping solutions sounds great tho.
Thanks for the help! Do you know if I have to use rsync to move the files around to get the bandwidth limiting benefits? Or can I apply to that to the chia application?
My follow up on this topic after some weeks, see it as a Synology guide if you want:
I deleted the big SHR Raid on my one Synology1 and had all the correlating drives converted into JBOD one disc drives (18GB WD GOLD). Seek times are mostly below 1 second for this Synology system.
On my Synology2 I tried a different approach: Since the drives are smaller there (12GB WD GOLD) I merged them into JBOD 2 disc drives giving me around 22 GB net disc space.
I setup my farmer on Synology1, upgraded my whole network to 10Gbit/s and connected Synology2 via network drive to my Farmer on Synology2. Seek times are generally higher there, bus still below 5 seconds.
A chia win along the way ensured, that even with seek times >1 sec (mostly 2-3 seconds) are good enough. So no USB ghetto style farming for me for the next 5 years 
Next upgrade is a Disk Expansion unit to Synology1 via eSATA.
So for those you who are using a NAS to organize multiple machines with a single harvester, I have a setup running that I managed to get working. For context, currently I have
So far starters in regards to organizing your RAID/NAS system you do need 10Gbe on all of your machines. Recently I did a reconfiguration where one machine was 1Gbe and is causing problems.
Secondly do NOT use Linux mdadm or other such technologies. You will exhibit problems with random reads/rights possibly causing you to lose out on proofs. What I am using is TrueNAS/FreeBSD/ZFS. The main reason why is ZFS has a concept called ARC which basically acts as a cache and you also have 2 levels of cache, one which is RAM and the other which is a hard drive (typically a fast/reliable SSD).
The cache massively increases the speed of lookup times for blocks that are used for proofs and most importantly makes the lookup very reliable (since you are just accessing either memory which is ultra fast or SSD).
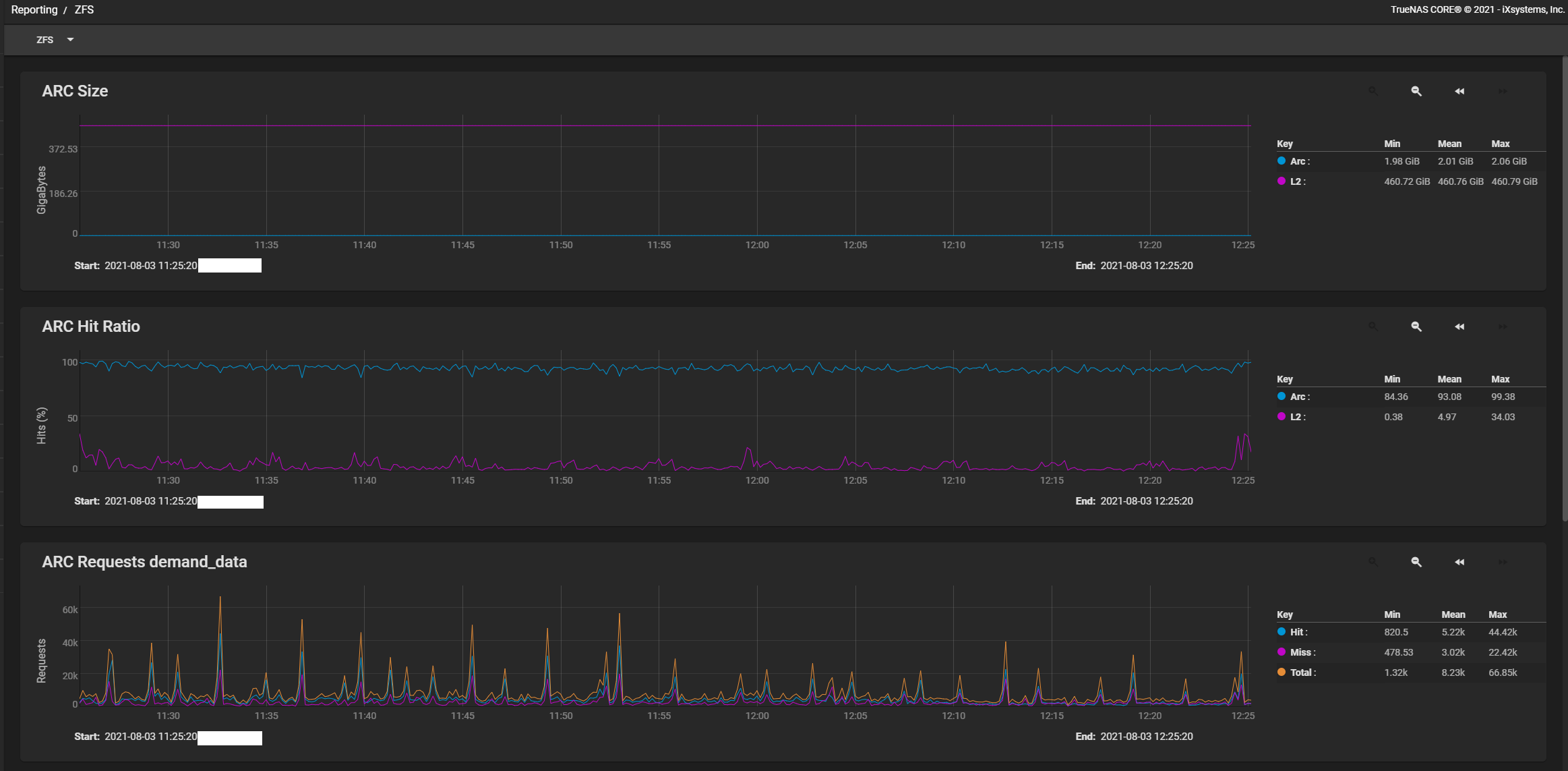
Here is a screenshot of the Arch cache stats for a 360TB single machine with a RAIDZ-2 (ergo RAID6) of 24 disks
As you can see (blue line is memory, purple line is SSD), for memory the cache hit rate is 95%+ (which means that 95%+ of the time the reads are coming off RAM). For cache hits that are 50% or lower its going off the SSD which is also incredibly fast (i.e. much faster than the mechanical hard disks)
What this means is that the worst case latency when a you have a cache miss (i.e. it ends up hitting the actual mechanical disk) is around ~800 ms which is acceptable.
So if you are going to go for NAS, what I would strongly recommend is using ZFS as your main filesystem and throwing a good amount of memory (each of my machines has 32 gigs but I can definitely go higher) and an SSD (in my case I have a 2.5inch 512gb SSD for the machines but I am strongly thinking about upgrading it to a 1/2tb nvme SSD soon).
For network sharing, use NFS instead of Samba/Windows shares (its much faster) and also enable things like noatime (i.e. no access time) to speed things up a bit when listing the directory.
The actual farmers are also sitting inside one of the NAS’s (this is where the 10gb/e becomes important), since I am using TrueNAS/FreeBSD which is not Linux there isn’t a nice way to run the farming tool so I opted to use a Virtual Machine via bhyve with Ubuntu, Make sure you use VirtIO as the adapter for the NIC/disk for performance reasons.
I would not recommend using Synology NAS’s, you basically need a RAID/filesystem optimized for this usecase which currently from what I can tell is only ZFS. I am not aware on any other filesystem/RAID which has these caching capabilities and is as mature as ZFS. FreeBSD is also a bit more picky what hardware you use, I would recommend only using Intel NIC’s for 10gbe (i.e. X540/X550) and make sure RAID controllers are set as passthrough/HBA (i.e. ZFS is software raid). You can also use ZFS with Linux via OpenZFS and TrueNAS is developing such a solution called TrueNAS Scale however its not marked as stable yet (such a solution would avoid needing a VM).
Good luck!
I did a couple threads on this same topic and found what works. Synology is fine as long as you have your network and harvesters setup properly. Here are a couple threads if you want to read up (a summary is provided below). My network is entirely 1Gbps.
A quick summary of what I did.
As long as you do these things, using a NAS is no problem at all. I have almost 6000 plots and 3500 of them on are NAS devices.
What is the technical reasoning behind this? I don’t see how this is going to make any difference unless you are also physically laying out the disks along with splitting the folders (i.e. each NAS folder is representing its own RAID).
To be clear, in my case I have a single NAS folder with 30k+ plots (and this is with a single harvester) and haven’t had any problems, but then again this is ZFS with a cache.
I have no idea why this helps. But it has been proven time and time again. Not just by me. I believe it has something to do with the software. How it indexes the plots. Not sure. But if you put a thousand plots in one folder, it will be slower than 5 folders with 200 plots in them. Again, not sure why.
A lot of Farmers are having issues that don’t get noticed. One obvious example is this farmer who got into our closed alpha, switching from the official client led to a large increase where his space finally began matching his hardware. We have no idea what caused the problem but glad it was solved so easily. The current client appears to have a lot of issues recognizing valid plots and with lookup times. I’d suggest every farmer look into it if their average isn’t matching where it should be.
So I think I may have found the cause behind this. I read somewhere else that the way the current Chia Blockchain is designed is that it only parallelizes on a folder level rather than on a file level, i.e. when it getting the proofs from your plot files it reads one file after another but if you designate multiple folders then this is done in parallel.
If this is the case it would explain why having multiple folders helps, its not that NFS is faster in a non trivial way with this setup, its that the actual blockchain only reads files sequentially. I believe that the current Alpha that @Chris22 alluded to implemented parallel file lookups which would solve this problem.
In any case in regards to scaling with NFS + large number of drives I still do recommend ZFS because of its caching abilities. As stated before, current setup is on data center levels (i.e. 24 drives at 18tb each on a single machine) and even with all plots stored in a single folder my worst case proof was15 seconds (with a cap of 30 at which point you start losing potential winnings).
I don’t disagree with your preference, I don’t have enough knowledge in those drive formats to give intelligible feedback, but as a comparison, I have a Windows 10 system running a full node with a 60 drive JBOD attached (Dell MD3060e). That full node has all folders added to it and is farming locally. I rarely see any proof over 2 seconds (currently with 2500 plots over 20 folders).
In my case its a single folder with 3500 plots and worst case proof is ~15 seconds.
I am willing to bet that if you took 15 minutes and split it up into subfolders, the response time would be below 5 seconds.
Indeed, in open beta now (for the linux/pi/docker version). Whenever someone brought up an issue we fixed it so it just grew from there. Lookups are averaging under a second for everyone on it. Not much help to anyone here as you need to be run an open source python script in windows to get your plots key (which is quite hard to do for beginners). Once we have an easier way for windows users to do so I assume many more will use it.
True but since its a non issue currently and the problem is going to be solved in the future its not necessary.
Great to hear, can’t wait till the next release of Chia then!
I am not a coder in any way shape or form. So I can’t be sure this is the problem I am having, but it sure seems like it. I have 5 qnaps and 1600+ plots and counting and suspect my times are off since over several months have hit nothing.
I really wish the GUI would tell us if our checks are going to slow. It also seems like there should be an easy way to setup each NAS as a harvester if that makes it more efficient. Any tips for a person who has zero experience with powershell etc?