Madmax has this, with the -s parameter ![]()
Yep, BB disk & the mmx fork version, creates a .tmp file in the output directory during plot creation and renames with a .plot extension once it is done. Yes also, to the simple batch file to move the .plot file to a local spinner. Here is my batch file (.bat) that looks for a .plot once every 110 seconds
@echo off
:loop
move G:*.plot D:
timeout /t 110
goto loop
No significant difference in plot time of the first plot vs subsequent plots as I consistently get plot times of 16.8 - 17.1 minutes per plot with cache 110G and long as you reserve 2 threads for the O/I writes, e.g. if you have a 16 core/32 thread CPU, set -t 30
1 Like
I have a different understanding of -s param.
I don’t think this is right. The next plot doesn’t start until the plot is about to be moved to the dst drive (not to staging), so there is no benefit to flush the ramdrive. My understanding that the staging folder is used to basically separate reads (whatever was built) from writes (the final assembly) to speed up phase 4.
Once the plot is finished in stage, the next plot starts (at this point ramdrive, t1, t2 are cleaned), and the final moving process starts.
What it means is that you can speed up your plots when you actually have 3x NVMe (t1, t2, stage), and use stage NVMe as your final destination.
I cannot say that I am 100% right, but I think I saw such behavior.
Also, when you run MM with -1, you can only specify one final destination, so MM will not be able to keep filling up your empty drives. This is what the batch file does for me (picks a plot from MM dst folder and moves it to a disk that is available).
Also, if your plotter is faster than your drive, you can have that batch file to move files to several drives at a time.
How long does it take you to move that plot to HD? In my case it is about 5-10 mins (10 toward the end of the disk). So, my take is that assuming that moving process takes 8 mins (in your case), when you reserve 1 phys core for I/O, that core sits idle for half of the plotting time.
For that reason, I always rather overbook my physical cores, e.g., on 10 phys / 20 logical cores, I specify 22 threads (I have tried -K 2 -r 11 vs. -k 1 -r 22, but I didn’t see any (significant) difference). The reason to overbook for me is that in case some core is doing I/O, that extra core can pick up the CPU during that time. To some extent, the hyperthreading should take care of it, but every time I did a comparison plots, the overbooked plotter was always faster. Also, the difference between hyperthreading and that overbooked thread is that thread swaps will be slower for the overbooked one, although that should be rather negligible (my guess), as threads swaps with the hyperthreaded cores are already there.
Although maybe depending how the box is built, sometimes it is better to overbook, sometimes under-book.
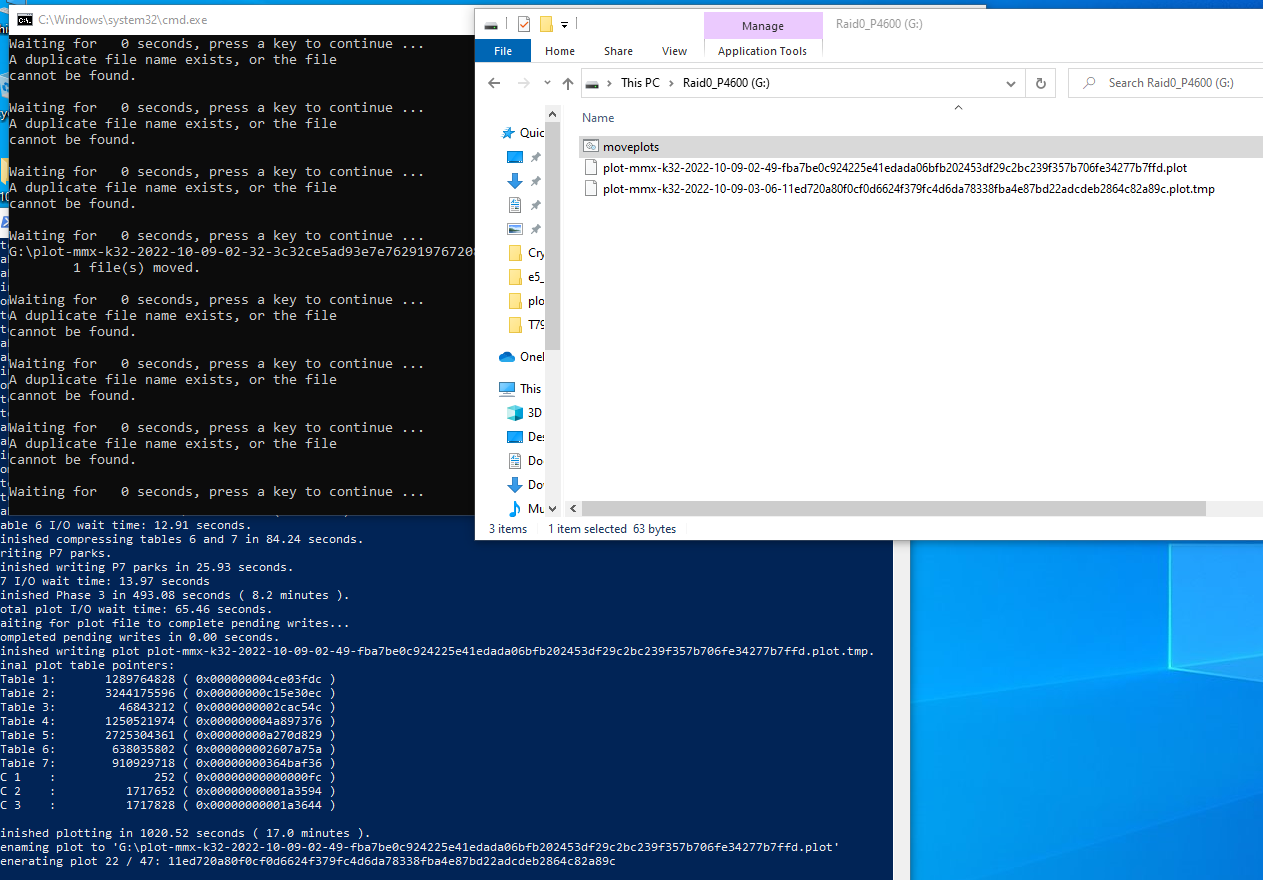
My 10TB hdd is currently 72% full and taking a little bit over 8min (195MB/s) for the k32 copy. I agree with you the 1 phy core that is reserved for I/O is idle for Phase1, but I think this happens only on the first plot for BB disk. After the 2nd plot starts, in phase1, the 1 phy. core is actively copying over the 1st plot from the staging NVME drive to spinner. At least that what I see from BB disk during the middle of Phase 1 with the 2nd plot.
1 Like
With madmax plotter, I could see a slight difference in Phase2 times between -r 22 -K 2 vs -r 44, with my E5-2696 v4. -r 22 -K 2 was about 20 sec. faster. That was with -2 110G Ramdisk.
1 Like
I have never run BB, so really don’t know how it is structured, although most likely both MM and BB are just highly optimized versions of the original Chia plotters (or rather process similar parts of the plotting process), so the load on CPU, RAM, NVMe is similar.
As you said, the first plot is an outlier, so just all the other plot times count. That means that the second half of the plotting process is the one when the I/O core is idle, and that part is more or less the assembly part (less heavy on the CPU). Maybe during that time whether there is one extra or one missing core doesn’t matter that much, as more time is spent there waiting for either RAM or NVMe.
By the way, I see similar (tad longer) times under Windows, but really a bit faster times on Linux. I have never looked into that. Maybe the real copying times are about the same, but Linux is better utilizing caching, so returns back from the moving process before the actual copying finishes flushing the RAM cache.
Not necessary. The copy requires minimal resource, maybe slows the plot process marginally, as in a some seconds/plot. The batch file move from @Scavenger is a good solution.
By the way, I see similar (tad longer) times under Windows
@Jacek …If you are not beating MM times, don’t believe you followed setup directions correctly, as I described for @ksevin.
Last, one thread is necessary & sufficient to handle IO overhard for plotting & copying from my experience. Your processor may require two if really slow.
1 Like
Sorry I was not clear. That comment was just about the plot copy phase.
With MM 26-28 min.
With BladeBit 2.0 infinite…
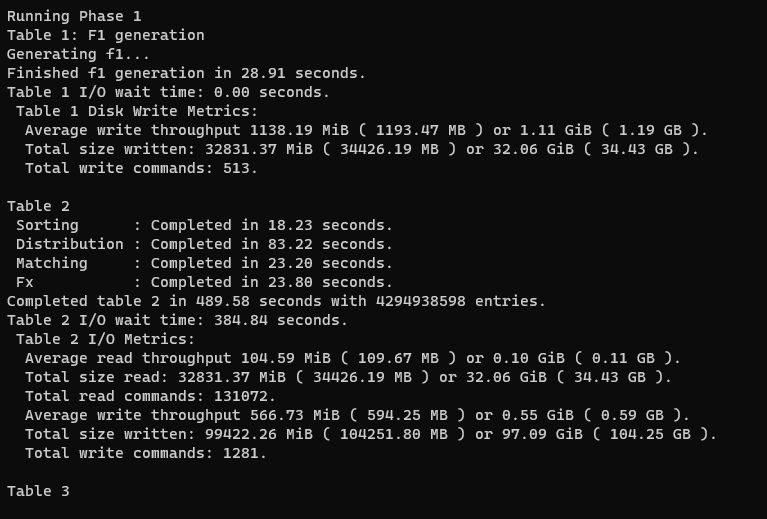
It stopped at Table 3… for more than 30 min, and I stop plotting.
You definitely need to work on that table 2 I/O wait time ![]()
Mine looks like this > “Table 2 I/O wait time: 0.05 seconds.”
Just in case, here is the page - Releases · zcomputerwiz/bladebit · GitHub with Win binary and the source code.
I went through the code changes, and everything was clean. I wish that people would not be providing the whole enchilada, but rather just modified files to be copied over the original code (Harold’s github). This way, it would be easier to check them.
Yeah, I am not beating MM results, and if yes than rather by seconds. I did follow your instructions. Also, my box is very similar to yours (i9-10900, 128 GB RAM, WDC Black NVMe - basically, the same gen). My plotting times were around 31 mins. Also, there was a bit of activity on NVMe, and it looks like NVMe had plenty of headroom.
Actually, one interesting thing. I first run it without specifying the number of threads. As such all logical cores were used. Those results were a bit slower. Then I specified just 19 threads (left one for whatever), and plotting speed improved (down to that 31 mins). So, MM looks like likes to be overbooked, where BB cannot handle that (maybe thread priorities for crunching numbers are boosted - didn’t check that).
Your i9-10900 has more cores/threads & much higher turbo than the i5-10500. You did get 22% faster times (31 vs 39.9) that’s decent for sure, although I would have guessed better from this benchmark > CPU Comparison. Did you run 2 instances of MM? That does help if you have enough threads to split, like yours. There are other little things that are hard to discern at a distance, i.e., I mentioned the one less than total threads, which your tried. Was ur BB destination directory on the HD or nvme?
Anyway, feel happy. I only get 14-15 min times with my 16C Threadripper with extra nvmes.
1 Like
I think that that CPU comparison page is more paper-based than real life. For instance, the turbo performance is really overhyped. Sure, if only one core is running and the CPU is not overheating, one can see that turbo speed, kicking in but the minute more cores are active, so much for turbo, especially as our processors are non-K version. But as you, I was also expecting something closer to 30%, or at least few minutes faster than MM. Maybe your processor due to a higher base clock speed can actually run at tad higher rates than mine. Both have the same TDP, so more cores, more heat, more throttling (my CPU temps are low, though). That would be my guess. Also, maybe motherboard is at play as well (less fortunate chip selection).
Actually, one thing that I didn’t check is whether my temp NVMe is the one sitting directly on the CPU.
Yeah, that box has 2x WDC Black NVMes. One for tmp drive, the second for dst. So, no spinning drives were around that plotting.
Actually, the one thing that I did differently than you is that I have a batch file to start the process (thus CMD prompt), but PowerShell is used in that batch file to start the plotter (basically, to get tee on the plotter output). Is there any reason that you suggested PS Admin?
As far as MM, I was running just one instance on that box, as MM is really good at managing a single CPU.
I also have a second plotter (dual Xeon v2), with 256 GB RAM. I was running 2 MM instances on that box (NUMA locked to respective CPU/RAM). I will need to dust it up to try it. However, if I will need to replot, I will potentially wait for Max to update his plotter or get more RAM and switch to BB v1.
To me, BB Disk is kind of a pride point on Chia side. They hired Harold to get BB v1, and have him work on it. Although, that plotter is kind of targeting whales (not too many people have boxes on the level that JM is pushing), where the standard chia plotter just sucks. It looks like they soured relationships with Max, so BB Disk is something to fix the lack of a good in-house plotter. Maybe once BB Disk will be stable, they will just ditch the original plotter, or use it just in the lab to test for compatibility / correctness.
Still, the fact that the original plotter is the default one in GUI, and that OG plots are default is just nonsense basically giving newcomers the worst part of chia to boot.
To sum it up. Maybe I didn’t see any gains with BBD, as my MM was potentially well tuned, where the only thing that I changed on BBD was lowering the thread count (should have played more with buckets).