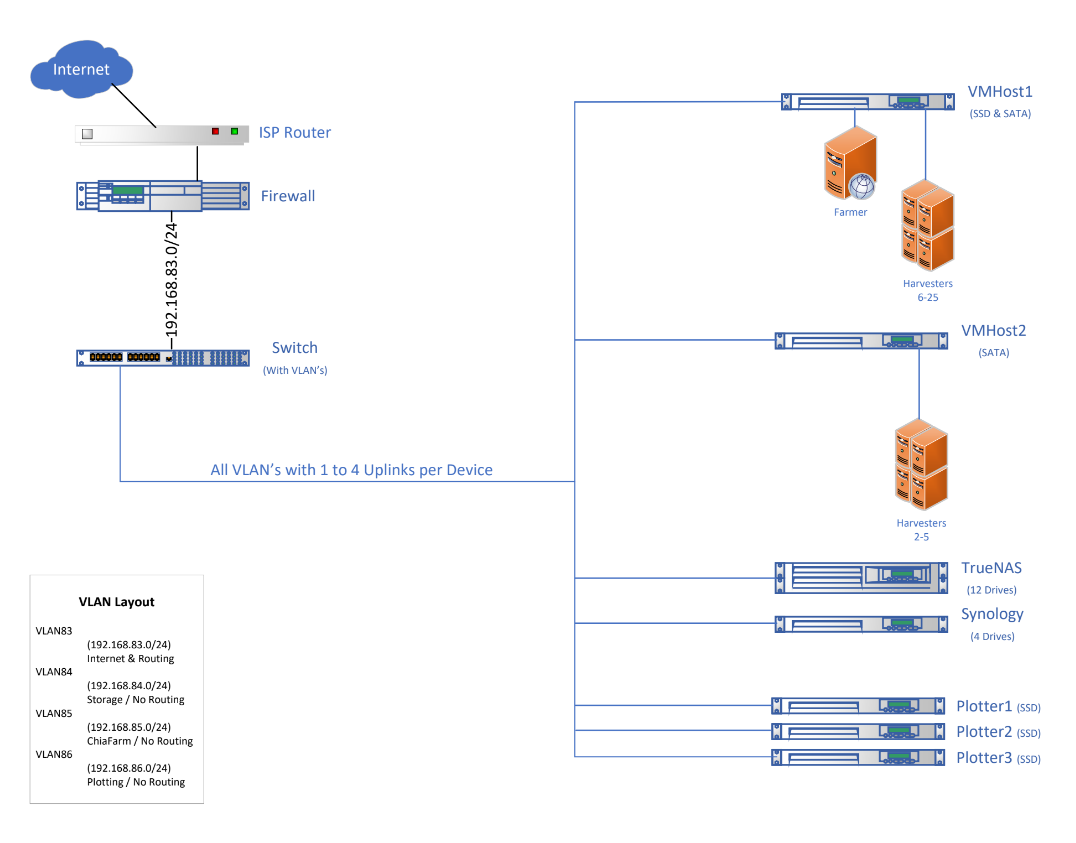
We have a unique infrastructure which I’ve mapped out below. We are not able to get any proofs, so something is amiss. We would greatly appreciate feedback/assistance/support from the community about what is wrong with our system, and how we may be able to remedy the problem.
I will be monitoring the thread, and will follow up on any further inquiries, requests, or suggestive solutions as replies come into focus. Thanks in advance for you all.
No one wants to analyze complex systems, where the problem was introduced most likely early in the process.
Why don’t you
shut down everything but your farmer, and analyze logs
once you see that farmer logs are clean, add to that farmer a couple of drives, and check logs whether those are recognized (by default, every 3 minutes it should be some entry about those drives)
after that, you can try to bring up one harvester to see whether it can communicate with the farmer
if all is good at this point, you should be able to bring one VMHost at a time, and make it work
Otherwise, it is just too many moving parts to look at and/or suggest anything.
Although, I kind of fail to see the advantage of using VMWare to split the box for instance in separate harvesters. If all VMClients on such VMHost can work as advertised, just one system should also handle all connected resources. (Although, maybe this layout gives you some advantage when using 1Mbps Ethernet cables connected to separate NICs on the same box - potentially less expensive solution to going 2.5 or 10Gbps route.)
If I counted right, you have ~180tb of data (plot) drives. Holy cow, you could farm that w/one (slow) NUC. Are you planning on expanding to a PB farm or is that it? If that is it, perhaps simplify the whole thing to one plotting PC and a NUC and have at it.
I can speak to this because I have 3 harvesters running as vm’s on one system. The reason is speed. For some reason when a Chia harvester is given multiple remote locations, it runs dramatically slower. It must have to do with it opening and closing connection between resources. But if you assign one harvester to each remote set of drives, it runs great. Even if you have multiple harvesters on the same system.
Here is a thread I did on this setup:
But the bottom line was: 1 harvester with multiple remote drive arrays = very poor performance, 1 harvester per remote drive array = great. Even if those harvesters were on the same system.
Good read that other thread about your VM route. It looks to me that you should report it on Chia’s github Issues page and have them look at that setup. If the problem is really the harvester code, I would think that insight gained from your setup could further improve how harvester works.
There is always a chance that the issue is no longer an issue. That setup/test was done in May of 2021. I am still running that setup because it works. But since there have been many updates since then, the issue may be gone or reduced. I don’t know. Not worth reworking my setup to find out.
Without a whole bunch of info about every little thing in that setup and all the system logs, I think anyone would have a hard time figuring out where the problem lies.
I think the only way to diagnose (unless you get lucky) is to start simple and work your way back into this setup so you can see when the problem pop’s up.
Connect a farmer with some local hard drives directly to the Switch, run with a pool, so you can quickly see if partials are being correctly received by the pool.
If that works, enable the vlan’s again see if it still works, add a harvester, etc, etc.
Trouble shooting a complex system like this for a not typical workload (chia farming) is going to have you chasing ghosts for ever unless you break it down.
I have a similar setup, its awesome. I would first check to make sure your farmer has connections on port 8444.
Run:
chia show -s -c | wc -l
(how many connections)
and
chia show -s -c
(shows actual connections on 8444)
To confirm connections.
I did have harvesters slow down when I put more than 1500 plots per harvester.
Keeping it around 1500 keeps responses below 0.25 sec.
This is a chia software issue. I use VMs to get around it.
The Synology is connected via Samba, NFS for the TrueNAS.
TrueNAS protocol was changed to NFS recently in an effort to reduce response times. It’s noteworthy , our response times were reduced to below 1 second
We begin having our issue with 0 proofs around this time, but haven’t conclusively linked this protocol switch to the issue.
I don’t have much over-network plot space (it’s 95% direct attached) but I have not seen any appreciable difference on TrueNAS using NFS over SAMBA. In fact, I reverted back to SAMBA having researched performance and read articles from reputable sites that benchmark the two options.
What I did end up doing on my TrueNAS box was adding a dedictaed NIC for the SAMBA share and also adding a dedicated NIC on my harvester machine, then linking the two directly with one cable so that they are the only two devices on the network (point to point/end to end). Then, I set MTU to 9000(/9014) often referred to as ‘jumbo frames’ on both NIC’s on the link with a positive increase in performance.
Typical average response times are less than 0.25s, and only go near 5s when a proof is found.