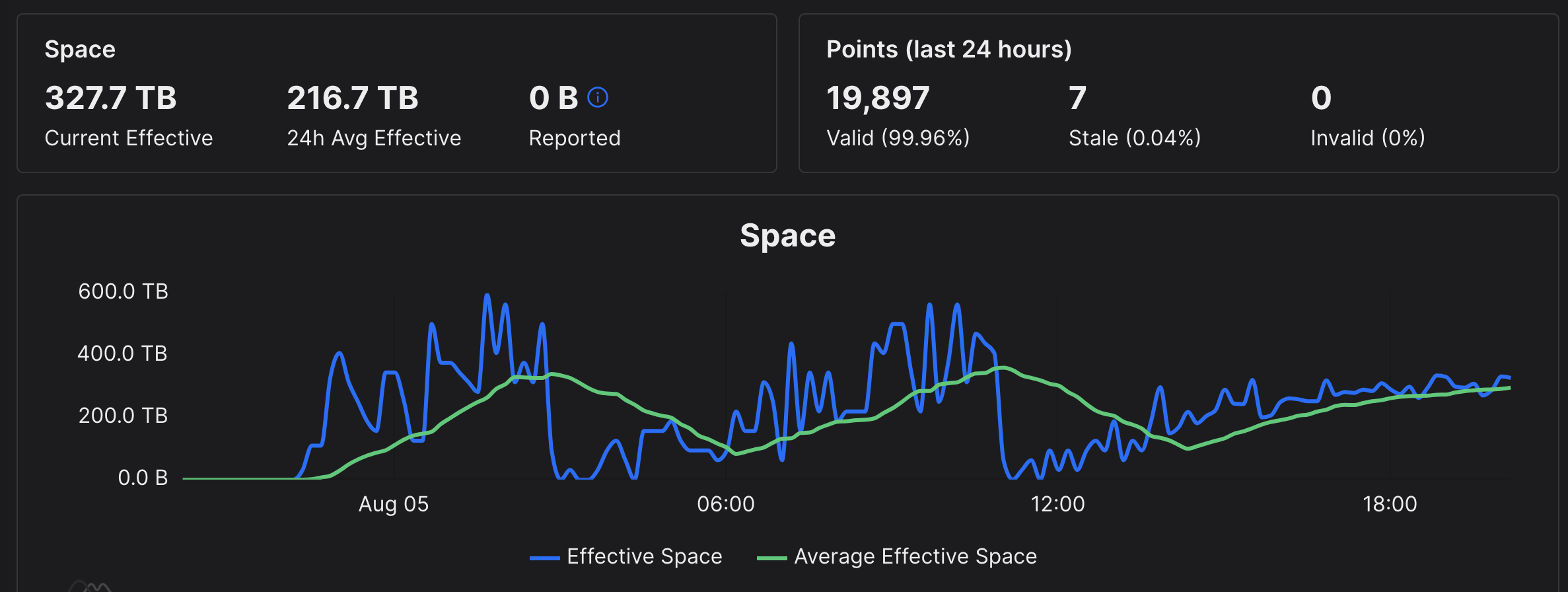
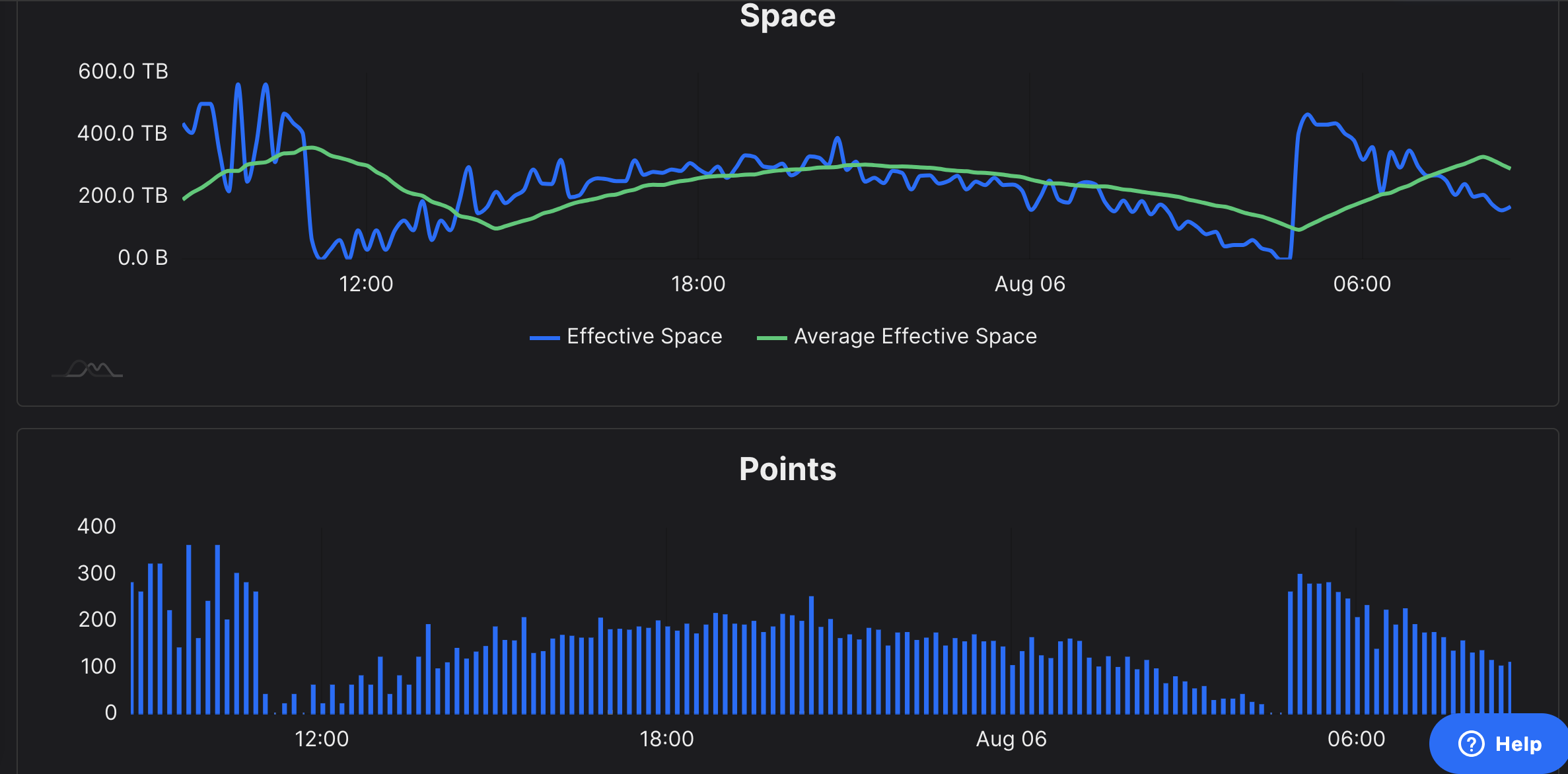
FlexPool diff 20, wild swings. chia plotnft show shows more submitted points. There is a warning not mess with diff. Sadly, payments didn’t reflect that either.
FlexPool diff 1, also weird in comparison to FlexFarmer bridge.
One reason is that Chia compressed plots are still in beta, another is C7 only gives 30% more space, whilst GH C8 is 42% more space IIRC which easily off sets the fee. Another is that GH came months before Chia compressed plots.
I’m personally using Chia, replotted about a month ago to C7
Logically not, as it’s really not a compressed file, but bits are missing that have to be reconstructed within memory (either computer RAM if no GPU or in GPU VRam) to get back to what was stored before the days of compressed plots. So there’s actually less reads from the hard drive (less data stored, hence smaller files), but lots more recalculation (a portion of what old plot generation did before storing), hence why you need more CPU power or a GPU do do this re-generation of the missing pieces on the fly within memory.