Up until now, I have been checking that my Chia system is up and running through the GUI. However, yesterday I noticed that my logs did not have any harvester info. Turned out that although the node, plotting, harvester etc were all showing a green, connected status, my harvester network list was empty. Has anyone experienced similar issues? I have noticed that when I go back to keys, the harvester network finds the harvester again. However, after a few moments, it drops it again.
Throughout this whole time, the last attempted proof -table is showing attempts completely correctly, so the plots are there and farming seems to be on.
I do not think this problem has always been there since I have won some Chia in the past. I am currently running the latest available version. I have also noticed that my HDDs have started to go to sleep, which I now have tried to forbid from the Windows settings - although this does not seem to help with the harvester issue.
Are there some good instructions on how to move from GUI to powershell system? I have had so much trouble and unreliability issues with the GUI that it starts to seem that the bugs there are causing more trouble than actually helping.
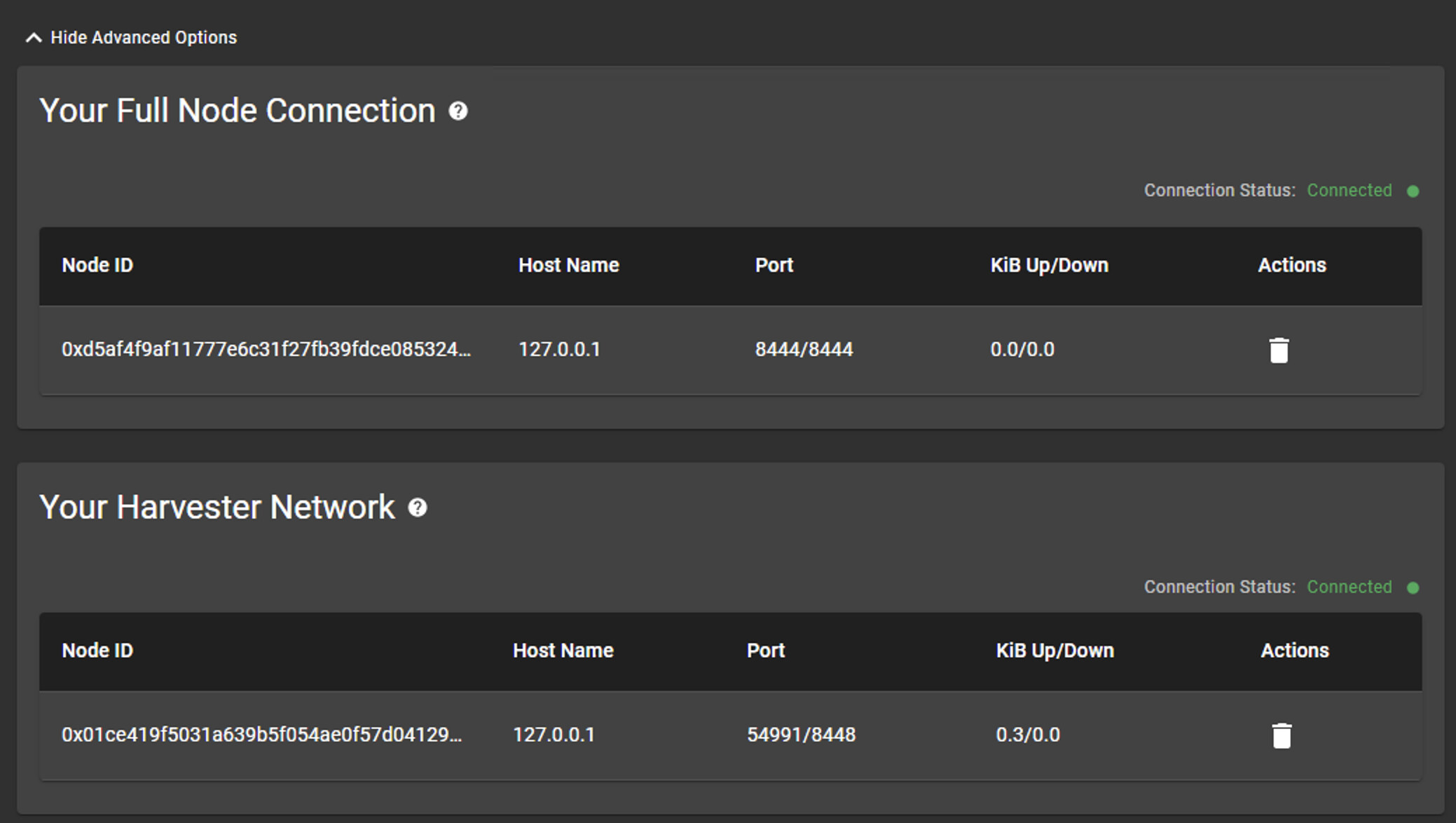
Btw, I recommend checking that your harvester is actually on the list - it is not enough that the connection is green. And, of course, this is not directly visible from the GUI since it is hidden under the advanced options -button.
Sure, I’ve been checking these. This was exactly how I noticed that the harvester was not online - there weren’t any logs related to the harvester. The situation is not helped by Chiadog since its “harvester appearing to be offline”-notifications are very buggy and seem to be completely unreliable on Windows.
Also the logs aren’t the best since they seem to be overwriting more or less hourly so it’s tough to go back in time and see when things went wrong.
I have noticed that even the full node sometimes shows to be missing from the GUI’s Farming page although simultaneously being synced in the Full Node page. Overall, it is unfortunate that debugging such things is extremely difficult due to the huge amount of bugs. I have now started to move towards shell scripts and hope to get rid of the GUI completely. Still haven’t completely figured out the best way to do this, since running the starting commands just start the services but do not show any real time status. Gotta figure out, what is the most reliable way of monitoring that the system is all good.
I’ve been running some tests, and it seems that my harvester goes offline when the computer is not used. I wonder if anyone else has had problems keeping their systems awake?
I have already changed the settings so that my Windows 10 wouldn’t go to any sort of sleep or save mode ever. I’ve also set the external HDDs etc so that the USB ports should not be ever shut down. Gotta keep on looking if there is still some switch hiding somewhere that likes to shut down harvesting-type of program. Simultaneously, however, plottings and full node have never had any issues and run nicely 24/7, so the issue seems to be solely harvester related.
Perhaps I should create a script that checks time to time whether the harvester appears to be online, and tries to start it automatically, if not.
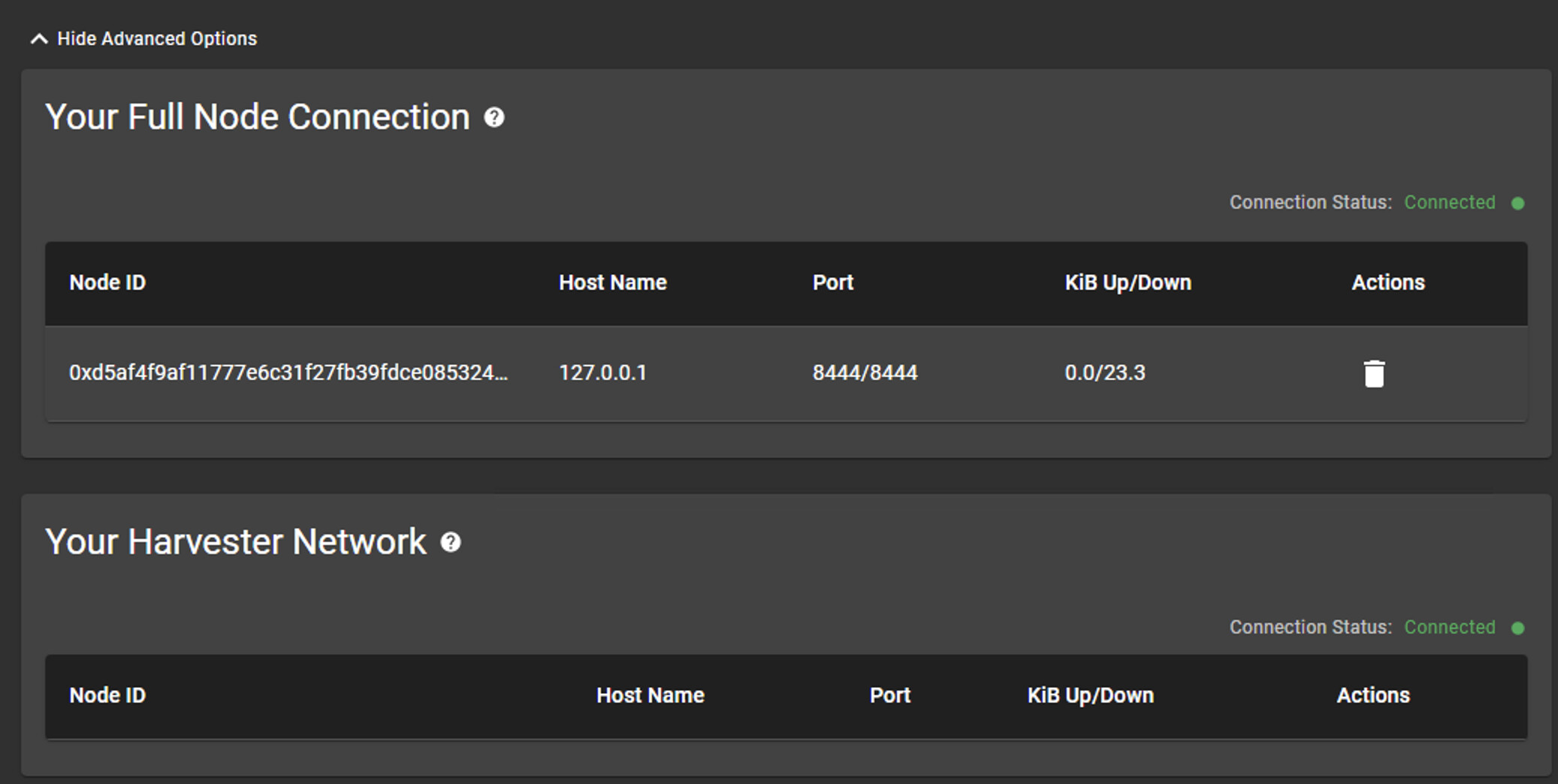
I’ve noticed this exact problem - the local (127.0.0.1) harvester disappears from the ‘Advanced’ list at the bottom of the Farming tab, it no longer seems to look for plots to pass the filter, and I can’t seem to get it to comer back on the list even if I run ‘chia start harvester -r’.
Once I restart it, the debug does find plots passing the filter, but is there some kind of connection which has been broken between the harvester and the node which means it isn’t farming correctly?
Before:
I’ll try to catch next time it happens so I can find the output in the debug.
Could it be something to do with the port it’s using? The full node is using 8444/8444, but the harvester is on 54991/8448 - should I be opening up 8448 so it’s directly accessible? Or something?
@heimo_vesa I just checked my power settings and noticed that it had slipped back into balanced mode rather than high performance - I’ve set it to stop anything going to sleep and I’ll monitor it intensely for the next few hours!
[EDIT]
NO. It’s still happening.
Does anybody know why this might be occurring? After this, the harvester disappears off my advanced tab, and I get no more attempted proofs.
2021-05-11T14:57:56.881 farmer farmer_server : INFO Connection closed: 127.0.0.1, node id: 01ce419f5031a639b5f054ae0f57d0412950b6980a32192aeb86401092a4d6bd
2021-05-11T14:57:56.881 farmer chia.farmer.farmer : INFO peer disconnected None
2021-05-11T14:57:56.881 daemon __main__ : INFO Websocket exception. Closing websocket with chia_harvester code = 1006 (connection closed abnormally [internal]), no reason Traceback (most recent call last):
File "websockets\protocol.py", line 827, in transfer_data
File "websockets\protocol.py", line 895, in read_message
File "websockets\protocol.py", line 971, in read_data_frame
File "websockets\protocol.py", line 1051, in read_frame
File "websockets\framing.py", line 105, in read
File "asyncio\streams.py", line 679, in readexactly
File "asyncio\streams.py", line 473, in _wait_for_data
File "asyncio\selector_events.py", line 814, in _read_ready__data_received
ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "chia\daemon\server.py", line 172, in safe_handle
File "websockets\protocol.py", line 439, in __aiter__
File "websockets\protocol.py", line 509, in recv
File "websockets\protocol.py", line 803, in ensure_open
websockets.exceptions.ConnectionClosedError: code = 1006 (connection closed abnormally [internal]), no reason
In some bug discussion in git, one of the main developers mentioned that the version might be very old if it still uses aiter. So, perhaps that could be related to your case.
I believe, I am using the latest version of Chia. After googling your logs, it turned out that for the past few months every now and then someone has faced this same problem, and no one has ever provided a clear explanation or solution for it.
Some discussions were proposing also that a broken plot could be behind this. Some mentioned upnp.
However, none of these explains my issues, I believe - as long as I sit on my computer, everything seems to be working fine. So, I have started to assume that once my screen goes off (15 or 30 mins without usage), perhaps something else goes also into a power saving mode, which perhaps causes the external HDD to go to sleep (I’ve heard that some HDD’s have their own software inside them that doesn’t listen to Windows’ settings), and this would lead to the shutting down of the harvester.
I also noticed that my system makes regularly checks for new plots, and last time the crash might had happened while adding these plots into the farming. So, not sure if there are some issues there - if I’m following the process from the GUI, everything works just fine.
Quite a sad issue. I started plotting my harvesting “power” and noticed that over half of the time (nights and daytimes while I’m working), the harvester is often off, and I end up farming only less than 50 % of the day. This, obviously, eats quite a bit of my profits away while still my node is running just fine.
Hmmm. I’m on 1.1.4 currently (going to update once my current plots have finished) - did this use Aiter?
The issue happens on a Windows PC in my office - I’ve got an identical setup at home which has never experienced it. I’ve just setup a Raspberry Pi 4 which I’m going to take in tomorrow and run for a bit instead of the Windows one, to see if that makes any difference. If it persists on a different operating system on a different PC, I guess it must be the network environment in the office.
I’ll carry on testing out different combinations, and keep you posted.
I agree that it’s incredibly irritating that we assume everything’s okay but actually the harvester might be doing absolutely nothing!
This is one great mystery here.
I assumed that plotting directly into the farming directory could have had something to do with this stopping, but now, after changing the plotting directory elsewhere, the harvester still keeps stopping.
I have also downloaded a bunch of programs to make sure that my external HDD’s are configured to never go to sleep.
So, perhaps next, I’ll just try stopping all plotting etc, in case there is just too much ongoing for the memory / CPU. Perhaps I could also somehow limit the full node’s activity since I believe I’ve had often >50 simultaneous connections (seemed to be much more than most in the forums, if I’ve understood correctly).
Damn.
There’s been some discussion in this other thread too. I just posted there a bit.
I’ve managed to keep my harvester online now for the past 12 hours, which is the first time it didn’t stop during the night. What seemed to be the fix for me was to decrease plotting.
I have a Ryzen 7 5800x CPU (8 core, 16 thread), and 16 GB RAM. I’ve been plotting 3 in parallel on my 1 TB SSD, so that I’ve used 12 threads and 12GB RAM. However, I’ve been checking from Task Manager / Performance Monitor my memory usage, and even with only 2 plots (that seem to consume only 2,5 GB each based on the Task Manager), my memory usage keeps jumping between 40 and 70 % depending on the plotting phase. So, with a few other programs and GPU miners, it might not be impossible that during some heavy phase, I just run out of memory, and the harvester is the least prioritized, leading it to shut down or who knows what. No other program has ever been affected, nor full node or plotting itself. But regardless of what’s going on, at least now it seems to be working for me.
Btw, I think I also kept getting these websocket errors, so I went through everything possible from allowing Windows Defender to pass everything through Chia, rejecting any sleeping from any program, HDD etc, updating all the software, stopped plotting into the farming folder etc, and nothing helped. This is also quite mysterious since I believe I have been plotting 3 in parallel for the past 1 month. So either this bug/issue was introduced only a few versions ago, or I’ve been extremely lucky being able to win some Chia even while harvesting being stopped >50 % of time.
Okay, I was plotting at the same time as farming, I’ll stop that and see how long it lasts. It’s literally crapping out every 10 minutes or so at the moment!
I can feel your pain - I asked help in here, Reddit, Keynote (which is truly awfully unusable piece of software - unfortunately) (+ read all the related bug reports and discussion in Github), and no one has been able to give any hints on this harvester disconnecting -issue.
Lets hope that just stopping the plotting will help. Obviously, this is also problematic, since now I either have to buy a separate farming machine, or plot very carefully, and neither of them is very optimal solution. But, after all, if the farming isn’t working 100 %, there’s no point of even considering plotting…
Since you had the same issue with Ubuntu, it really sounds like something that is not directly Chia related. Without being a professional here, I would assume the options would be either hardware or network related. People have been proposing to check that those right ports are open, and trying upnp configured as true/false etc. But at least for me, those didn’t have any effect.
Since shutting down the plotting is the last “test” anyone wants to try (I highly recommend just stopping it completely for 12-24 hours to see the effect - For me it wasn’t enough to just decrease the RAM and threads used for plotting but literally plot fewer plots). Hopefully it will also help you locate the issue.
That’s my last resort option - I’m starting to think it’s something to do with the network environment in my office, where that PC is located. I’ve got another one at home (with far fewer drives attached unfortunately) which hasn’t fallen over once.
If it still happens, I’m going to give up the office farm and try to cram everything into my tiny room at home!
Good point. I also had issues with the connections at my office network (*although this was seen not only in harvester but in the node and other connections too), so I ended up only plotting (without any remote farming or other online activities) at the office, and moved the full node and all the farming to my home network.
I also have this exact same problem occurring, a Windows 10 harvester. It crashes 1 time per day, every day. It seems to crash when I am sleeping (of course).
Not sure if the time of the crash is always the same or not, will start monitoring the crash time.


 I can feel your pain - I asked help in here, Reddit, Keynote (which is truly awfully unusable piece of software - unfortunately) (+ read all the related bug reports and discussion in Github), and no one has been able to give any hints on this harvester disconnecting -issue.
I can feel your pain - I asked help in here, Reddit, Keynote (which is truly awfully unusable piece of software - unfortunately) (+ read all the related bug reports and discussion in Github), and no one has been able to give any hints on this harvester disconnecting -issue.