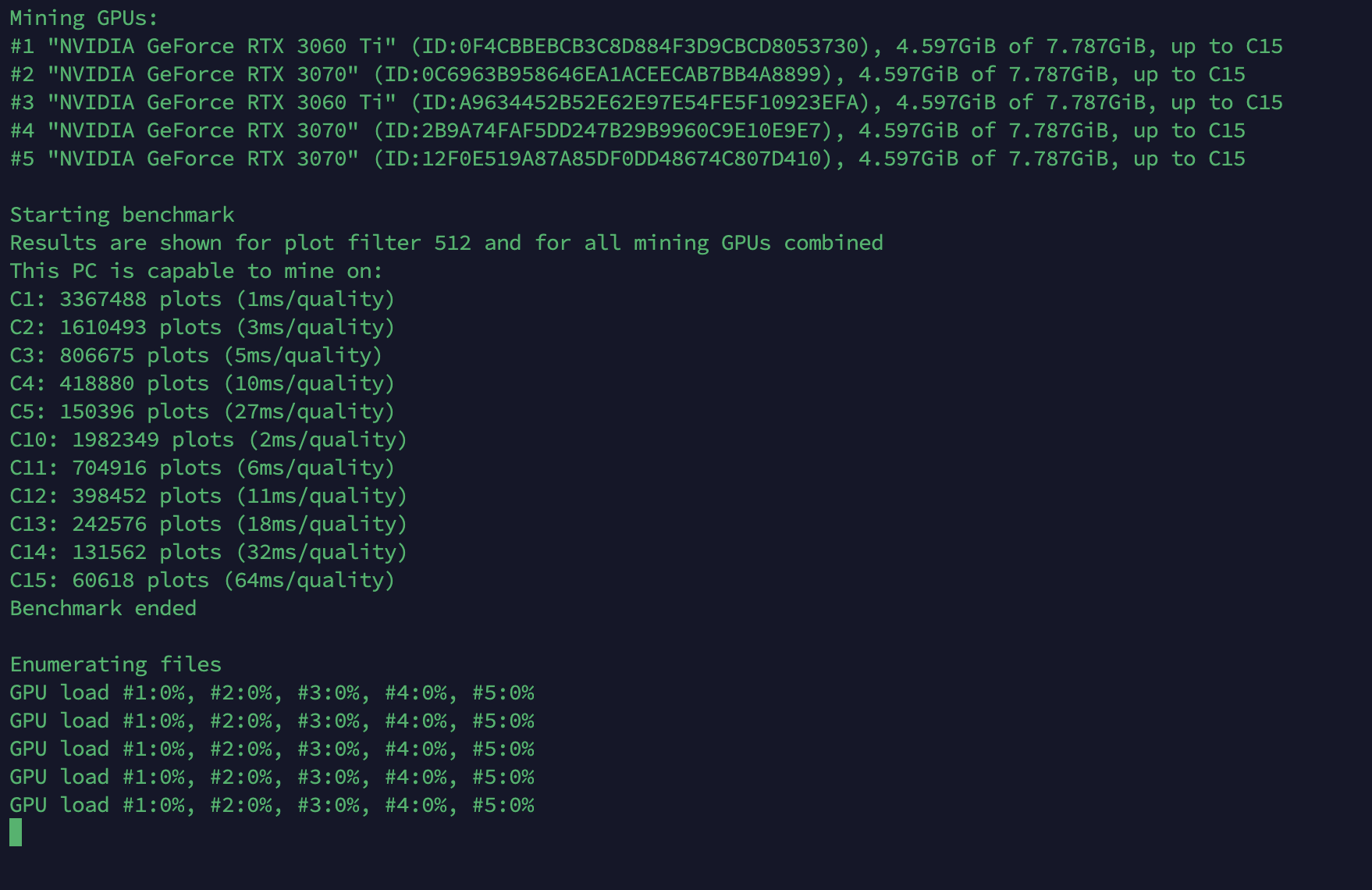
I have 129000 plots on 20 disk arrays (24 HDDs each), total 480 HDDs. They’re connected to the motherboard via an LSI HBA controller.
It takes forever to enumerate the files.
Any way to boost the startup process? I’ve been waiting for 20+ minutes and it doesn’t start.
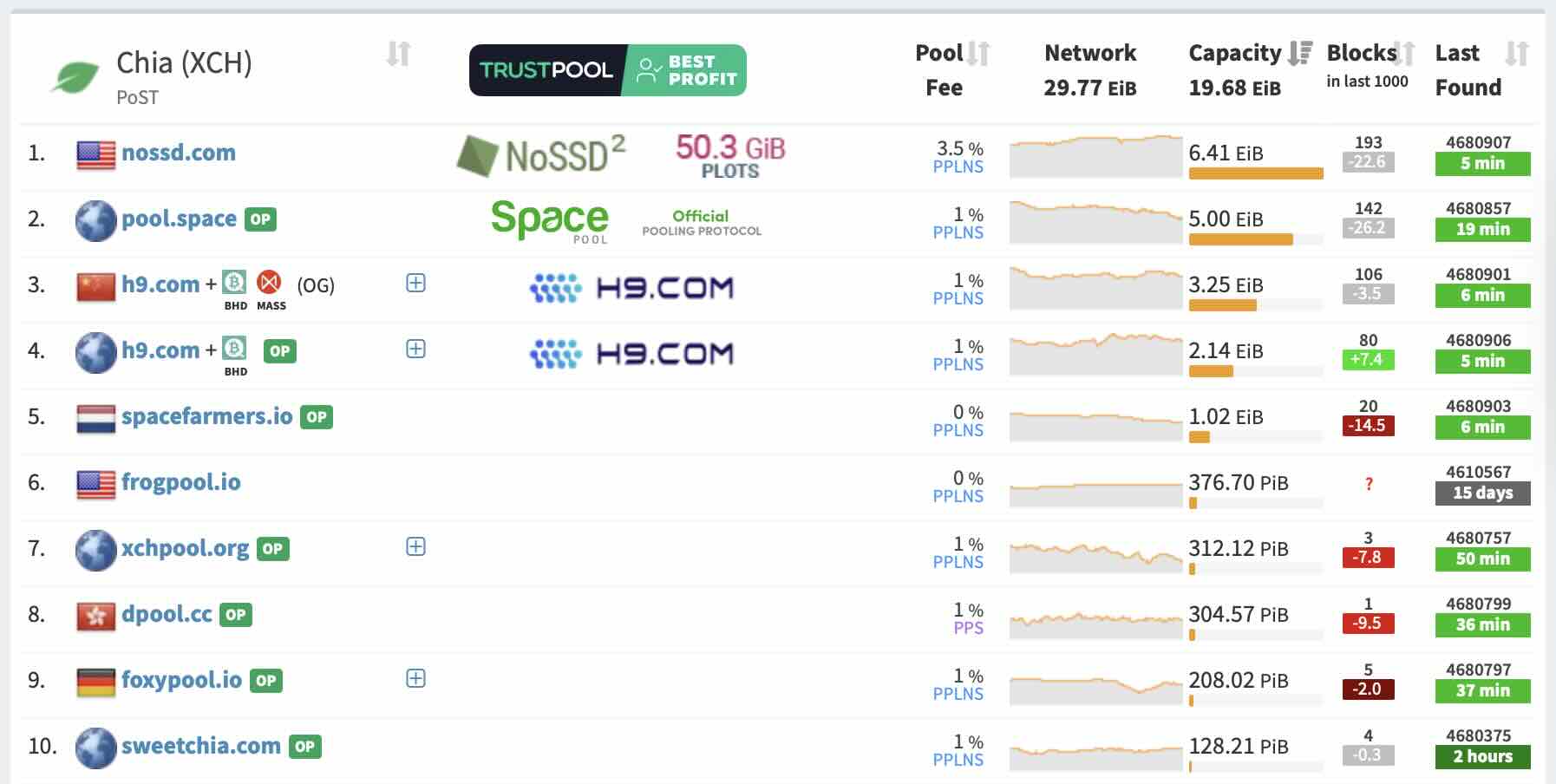
Maybe not. I am not sure how good that data is, but here you go (GH usage) - XCH.farm | Compressed Netspace Estimate
By the way, not sure why you used US map for NoSSD. Most likely that is either Russian or Chinese outfit.
1 Like
![]() I pulled from the mining pool stats website. Hmmm, what’s the probability/hunch of it being neither versus the former or latter?
I pulled from the mining pool stats website. Hmmm, what’s the probability/hunch of it being neither versus the former or latter?
We could leave it at in enough time all things hidden are revealed etc. Classic case of mystery crypto theater.
The only way to use NoSSD is to join the NoSSD pool (thus it is easily visible). On the other hand, GH and BB let you join any pool or farm solo (thus it is harder to say how much netspace they cover).
Also, the majority of netspace are big solo farms and those are not reflected in that pool info you provided, further making it difficult to say how much GH covers.
Lastly, when you check NoSSD stats, they have way less farmers than Space, meaning they are whale heavy. This may hint that other whales prefer to go with GH (as they are not joining NoSSD).
Max is the only person that could provide the exact data.
1 Like
Not that I’ve found, would love to hear if anyone else knows though.
All I’ve found is that you can monitor its startup progress by the allocated memory it accumulates or by monitoring the (very small) disk activity. I just try not to stop it very often.
Oh good. I only have a machine capable of CPU plotting for now.
I’m using Nossd but I’m still running a full node too.
No need to worry about it. NoSSD has about 2k farmers, where there are close to 100k farmers out there, so it really doesn’t matter that much as that is just too small percentage to pose any issues. As I wrote before, if the number of nodes will become an issue, that will be primarily on chia to incentivize people running nodes to avoid a potential disaster. Also, GH is less visible, but potentially has 2x the netspace comparing to NoSSD. Most likely, we can expect a new GH version that will match NoSSD performance (making those two a toss the from earning point of view). (GH requires a node, so it balances itself out.) (I would assume that virtually all pools are on the phone with Max asking for the next version. ![]() )
)
16:57:11 SP2104: completed in 15533ms, duty cycle: 165%, average duty cycle: 106%
Which values should be expected here to ensure no-stale operation?
BTW, are developers present in this thread so I can tag them to directly request technical support?
Average duty cycle should probably be <100%, but the most important thing is how many timeout qualities do you get.
Just search for the string like this:
WARNING: 100 qualities out of 100000 were not processed in time
This number directly reflects your loses. If you get significantly more than 0.2% timeout qualities, you probably should add more GPUs.
Version 2.3 uses one thread for each directory during plot enumeration (if --r-threads is not set manually).
So, if startup is slow, just increase the number of directories.
how many timeout qualities do you get.
I get none, fortunately. But I’d rather increase the PL then, thanks.
just increase the number of directories.
I have 480 HDDs, each is in a separate subdirectory. I specify
-d,r /mnt/*
at launch. Do you mean that I should specify every subdirectory separately? I know that I can use ChatGPT to do that quickly, but would it really help?
Or should I specify a --r-threads parameter?
Then it should be very fast, don’t know why it’s so slow.
Writing “d,r /mnt/*” is equivalent to specifying all directories by hand.
You can try to set “–r-threads 32”, but I’m not sure if it will help.
Right now the only thing that works correctly is running 5 threads of NoSSD, each tied to its own GPU, and specifying only some of the directories for each GPU so that they are not overloaded.
But I’ll try the --r-threads method. Does it matter how many cores & threads my CPU has when specifying this option? Because my GPU mining motherboard is a H110 Pro BTC with a G3900, which is 2C2T.
Note that GPUs will have slightly worse performance with this setup, because there will be no load ballancing.
No, it doesn’t matter.
1 Like
Yeah, I’ve already noticed that, unfortunately… that’s why I’m more interested in running a single client “in full”.
By the way, should I try to increase or decrease the value of --r-threads in order to try to fix my loading time issue? I would like to play a little with this value.
I would try 16 or 32.
By default you have 480 threads and maybe it’s too many for your system.
On the other hand using less than 16 may affect proof reading performance.
1 Like
Thank you for participating here with community support Anthony.
Can you provide any comment to us NoSSD harvesters about the upcoming plot filter halving? Do you anticipate any issues on the NoSSD farmer end? If our GPUs are at 50% load now, should we be fine?
Is there an upper limit to the --r-threads parameter? For some reason I thought 256 was the limit, but I looked at the help page again and that’s just the recommended max.
Also, I was wondering if you might be able to help with a weird issue I am having. The shares generated message in the log seems to more or less correlate to the online shares graph, shares are usually +/- 1 or 2 off and generally average out. Recently, there are some hours where the shares claimed on the website are noticeably less than those in the client log, but there are no errors in the log and no stale shares online. I had one hour today that was off by -8 shares and 2 off by -6 shares and no errors to explain it.