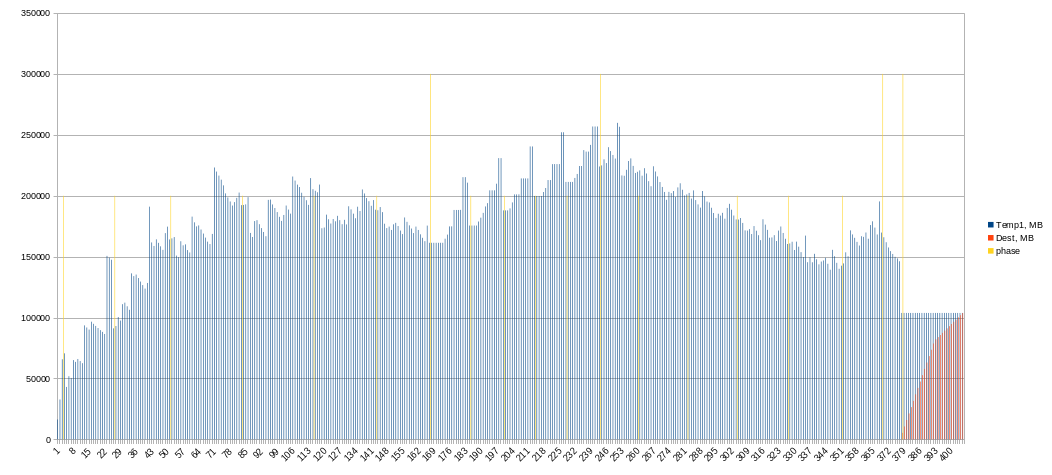
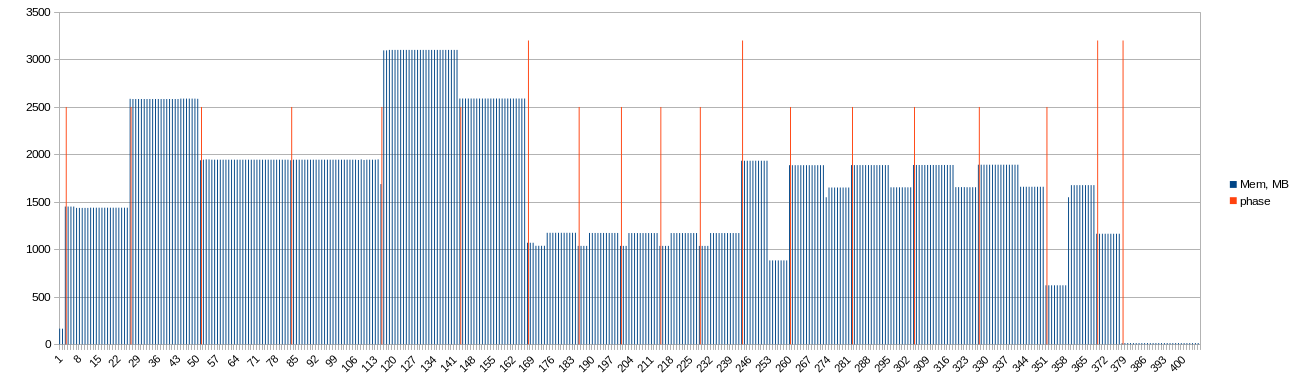
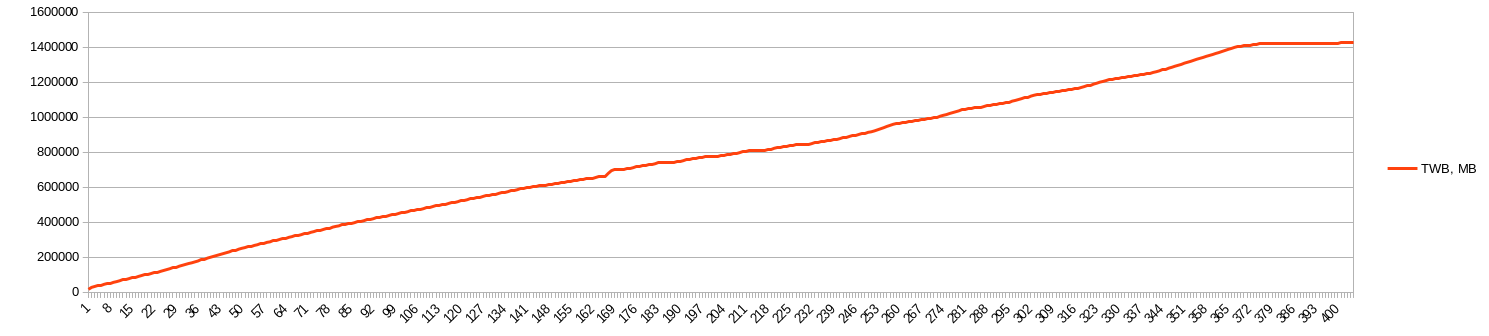
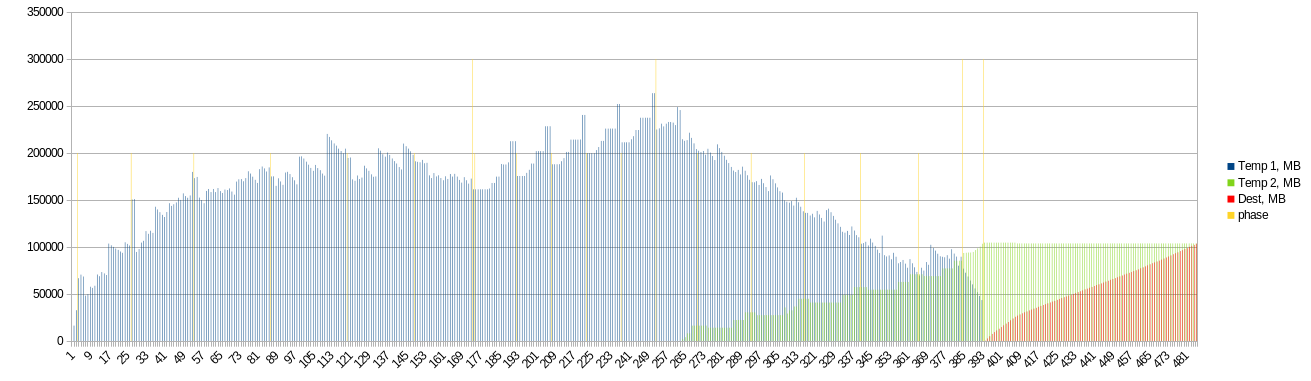
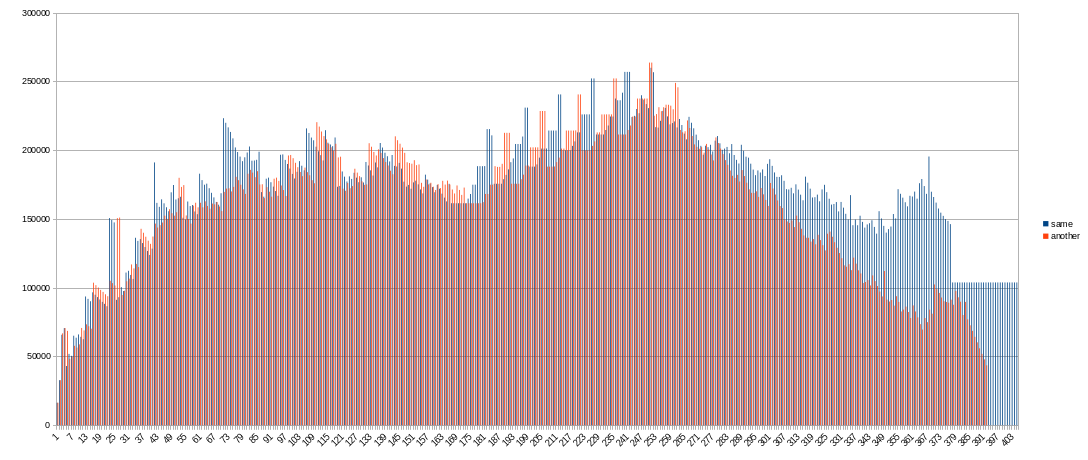
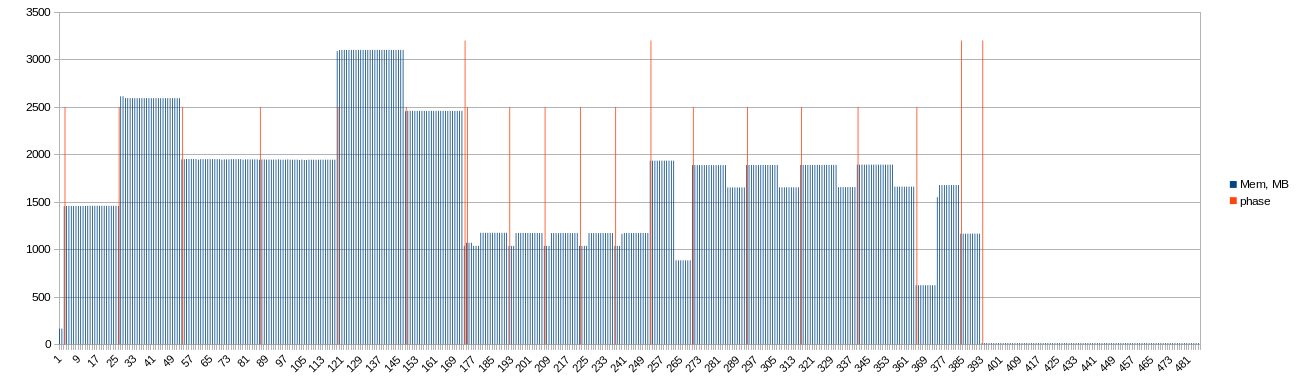
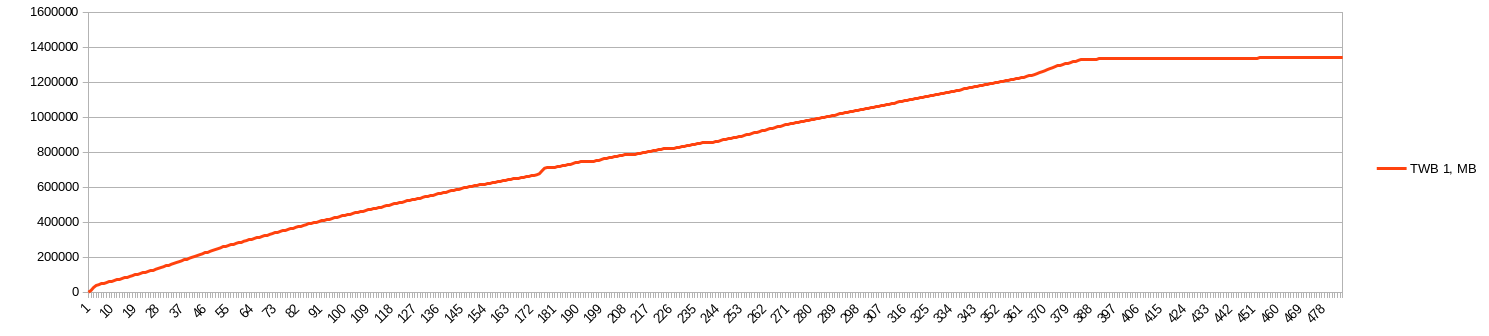
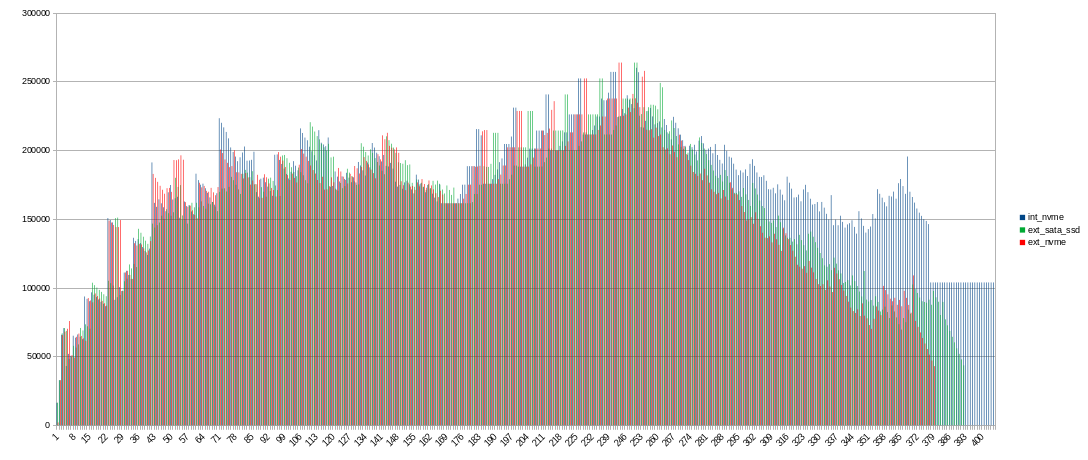
I upgraded my script. Results will be soon.
Script is launching by cron every minute and captures single plot seeding statistics. Output is formatted to import to spreadsheet with tab-separated format. Paths and device names is actual for my environment!
Here is script, not perfect, but working:
#!/bin/bash
# Capture date and time meaurements begins
DATE=`/bin/date +%Y-%m-%d`
TIME=`/bin/date +%H:%M:%S`
# Settings section
TEMP1=/temp1/
TEMP1_DRIVE=nvme1n1
TEMP2=/temp2/
TEMP2_DRIVE=nvme0n1
DEST=/plots16t/
DEST_DRIVE=md127
OUTPUT=/home/lv/testing/log2.txt
# Capture IO averages for 60 seconds
IO=`iostat -m -y 60 1`
# Capture disk space usage
TMP1_S=`/bin/du -s $TEMP1 | awk -F$'\t' '{print $1/1024}' OFMT="%3.0f"`
TMP1_IO=`echo -e "$IO" | awk -v var="$TEMP1_DRIVE" '$0~var{print $2,"\011",$3,"\011",$4,"\011",$6,"\011",$7}'`
TMP2_S=`/bin/du -s $TEMP2 | awk -F$'\t' '{print $1/1024}' OFMT="%3.0f"`
TMP2_IO=`echo -e "$IO" | awk -v var="$TEMP2_DRIVE" '$0~var{print $2,"\011",$3,"\011",$4,"\011",$6,"\011",$7}'`
DST_S=`/bin/du -s $DEST | awk -F$'\t' '{print $1/1024}' OFMT="%3.0f"`
DST_IO=`echo -e "$IO" | awk -v var="$DEST_DRIVE" '$0~var{print $2,"\011",$3,"\011",$4,"\011",$6,"\011",$7}'`
# Capture TWB for nvmes
TMP1_TWB=`/usr/sbin/smartctl -a /dev/$TEMP1_DRIVE | awk '/Data Units Written/{gsub(",","",$4); print $4*512/1024}' OFMT="%3.0f"`
TMP2_TWB=`/usr/sbin/smartctl -a /dev/$TEMP2_DRIVE | awk '/Data Units Written/{gsub(",","",$4); print $4*512/1024}' OFMT="%3.0f"`
# Capture CPU stats and memory usage
MEM=`/usr/bin/smem -c "name uss" --processfilter="^/home/lv/chia-blockchain/venv/" | grep chia | awk '{print $2/1024}' OFMT="%3.0f"`
CPU=`echo -e "$IO" | awk '$1 ~ /^[[:digit:]]/ {print $1}'`
WA=`echo -e "$IO" | awk '$1 ~ /^[[:digit:]]/ {print $4}'`
# Make heading row for new file
if [ ! -f $OUTPUT ]; then
COMMONLBL="Phase\tTime\tCPU,%\tWA\tMem,MB\tTemp1,MB\tTemp2,MB\tDst,MB\tTWB1,MB\tTWB2,MB"
TMP1IOLBL="Tmp1 TPS\tTmp1 rs,MB/s\tTmp1 ws, MB/s\tTmp1 r, MB\tTmp1 w,MB"
TMP2IOLBL="Tmp2 TPS\tTmp2 rs,MB/s\tTmp2 ws, MB/s\tTmp2 r, MB\tTmp2 w,MB"
DSTIOLBL="Dest TPS\tDest rs,MB/s\tDest ws, MB/s\tDest r, MB\tDest w,MB"
echo -e "$COMMONLBL\t$TMP1IOLBL\t$TMP2IOLBL\t$DSTIOLBL" >> $OUTPUT
chown lv:lv $OUTPUT
fi
# Make output
COMMON="\t$DATE $TIME\t$CPU\t$WA\t$MEM\t$TMP1_S\t$TMP2_S\t$DST_S\t$TMP1_TWB\t$TMP2_TWB"
echo -e "$COMMON\t$TMP1_IO\t$TMP2_IO\t$DST_IO" >> $OUTPUT