Brilliant, thank you Gladanimal.
So if compression of tables 5 and 6 starts at around 85% of total single plot time, then it seems using a secondary temporary drive shaves off 15% from the duration of each plot, without increasing disk usage.
Brilliant, thank you Gladanimal.
So if compression of tables 5 and 6 starts at around 85% of total single plot time, then it seems using a secondary temporary drive shaves off 15% from the duration of each plot, without increasing disk usage.
That’s right! That’s why I started this testing.
New hardware:
Plotting parameters:
Overall:
Time for phase 1 = 5074.508 seconds. CPU (162.030%)
Time for phase 2 = 2212.331 seconds. CPU (90.880%)
Time for phase 3 = 3109.913 seconds. CPU (139.740%)
Time for phase 4 = 284.687 seconds. CPU (102.400%)
Total time = 10681.442 seconds. CPU (139.220%)
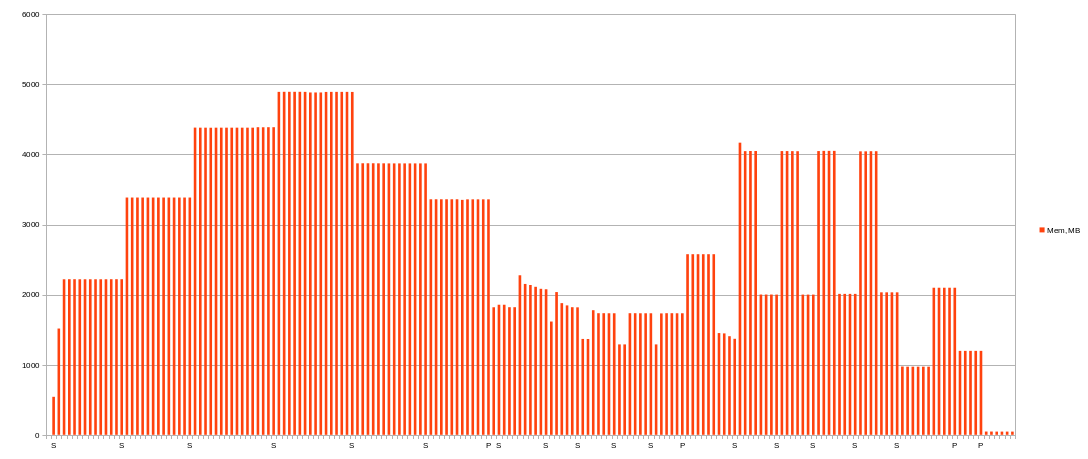
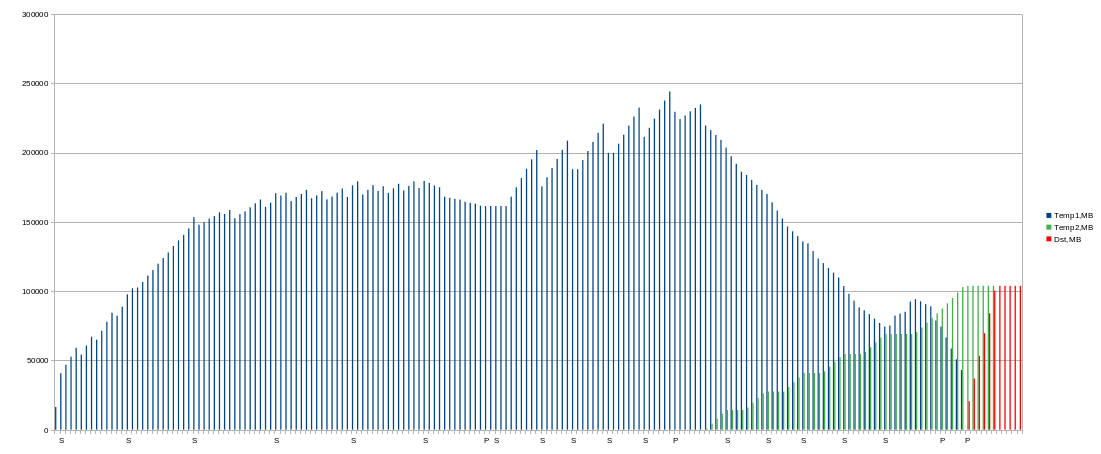
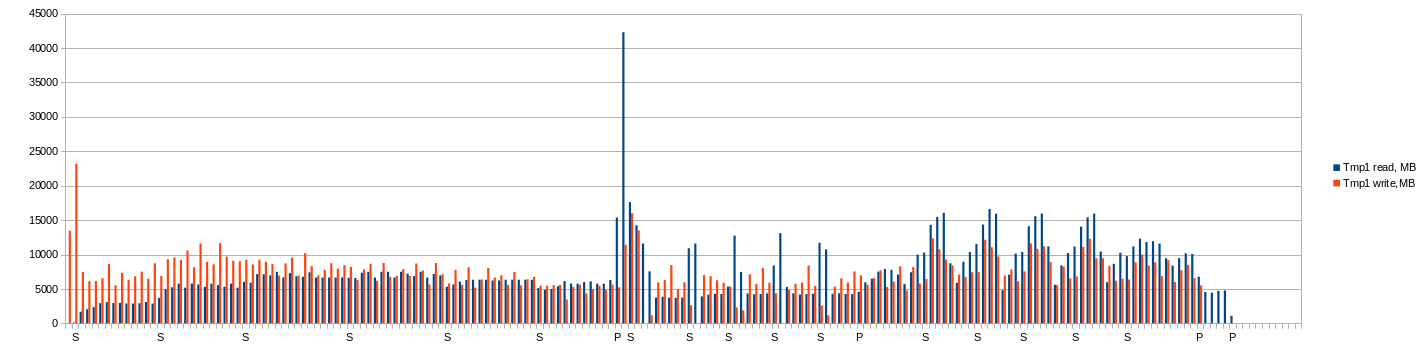
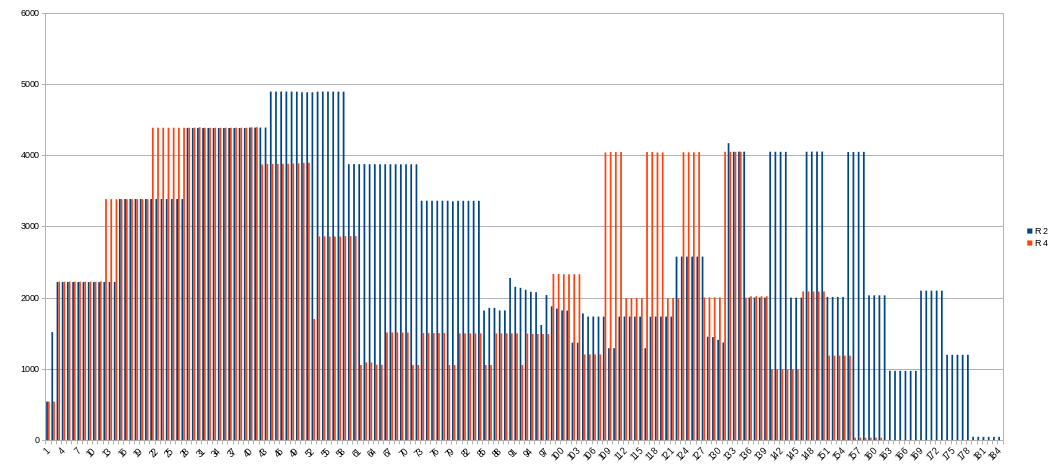
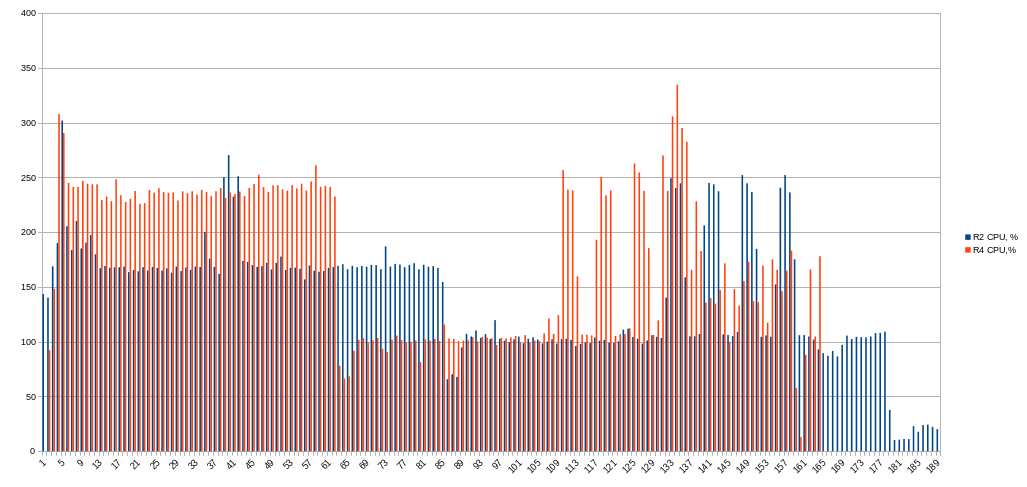
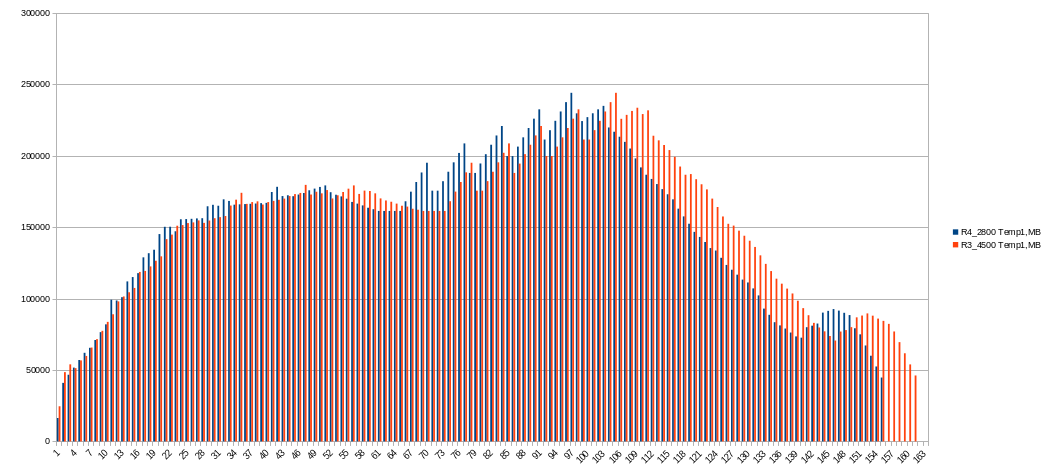
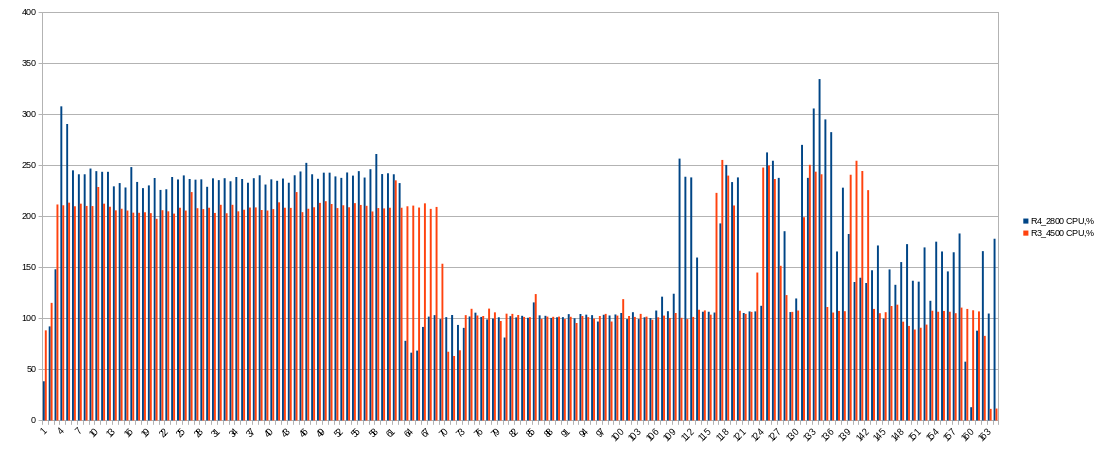
Note: next charts shows average values per minute! In moment them could be higher.
CPU usage:
Looking at the charts above (Plotting process measurements - #3 by gladanimal, Plotting process measurements - #23 by gladanimal) I found using default buffer size (3389MiB) affects to (especially) composing tables 4 and 5 at first phase and thus increases temporary storage I/O. So using 5000MiB would be optimal for performance on k=32 and u=128. Higher buffer size would not be utilized!
Would you mind trying 4 and 6 threads also?
Right now I have 4 threads raw results. Charts are coming 
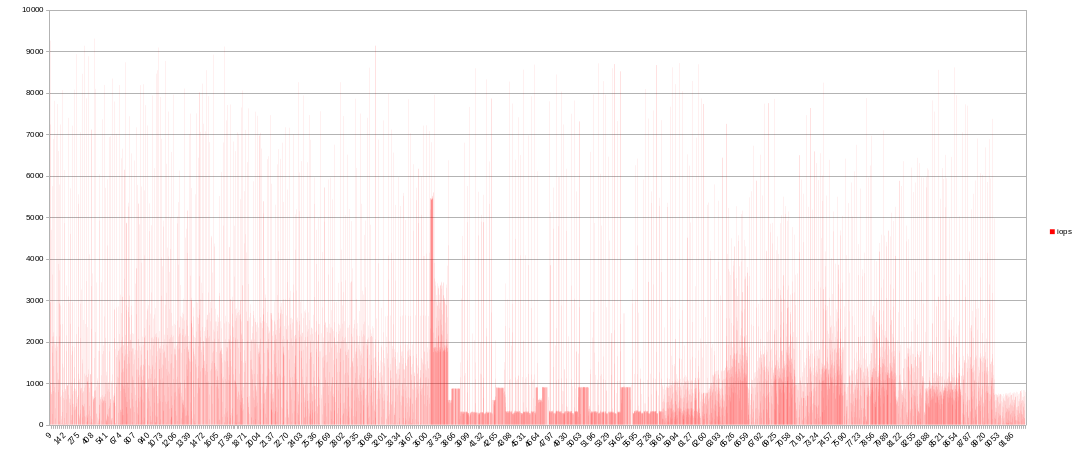
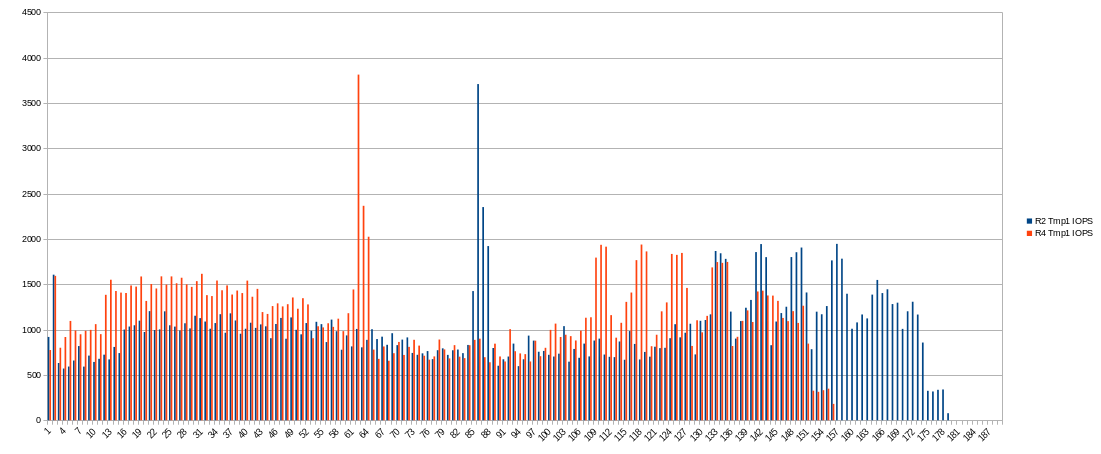
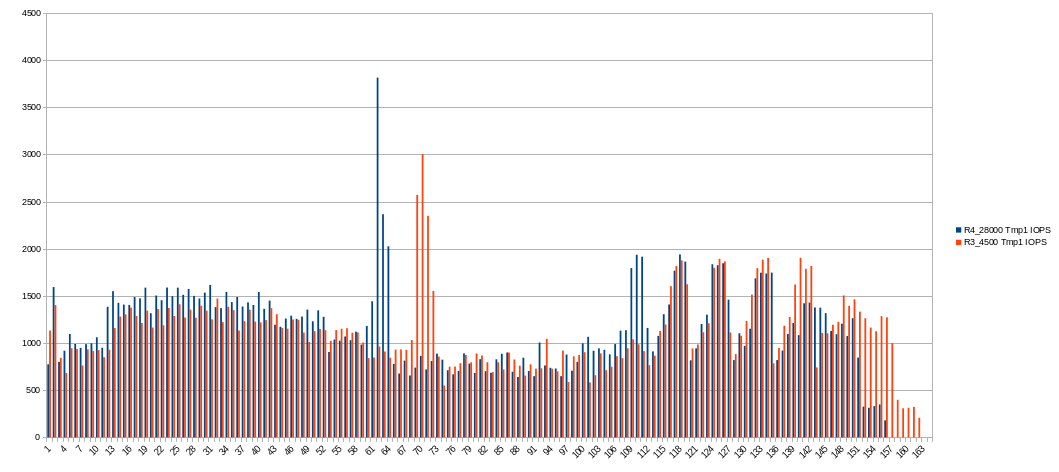
I captured real-time IOPS for temporary drive. Looks very nice. The peak value is about 9000 IOPS. Not so high as I think before. I assume slower CPUs would produce lower values (but not the fact).
So I assume IOPS is not bottleneck on modern NVME SSDs. For example my ADATA SX8200 Pro has 390K/380K, it’s more than enough to handle I/O for about over 50 parallel plot seedings (but actually its SLC and DRAM cache size and R/W speed is bottleneck)
It’s very easy to measure it on linux. Run this command in separate terminal before you start plot seeding:
iostat 1 | awk '/nvme1n1/{print $2}; fflush(stdout)' >> your_iops_log.txt 2>&1
where nvme1n1 is a name of your temporary drive and your_iops_log.txt is a complete filename to place logs.
After plot seeding finish press Ctrl-C and import results from log file to spreadsheet and make a chart.
Your charts are welcome!
Plot size is: 32
Buffer size is: 28000MiB
Using 128 buckets
Using 4 threads of stripe size 65536
Using optimized chiapos
Overall:
Time for phase 1 = 3630.957 seconds. CPU (230.460%)
Time for phase 2 = 2212.198 seconds. CPU (90.180%)
Time for phase 3 = 3170.369 seconds. CPU (139.560%)
Time for phase 4 = 299.807 seconds. CPU (102.430%)
Total time = 9313.333 seconds. CPU (162.080%)
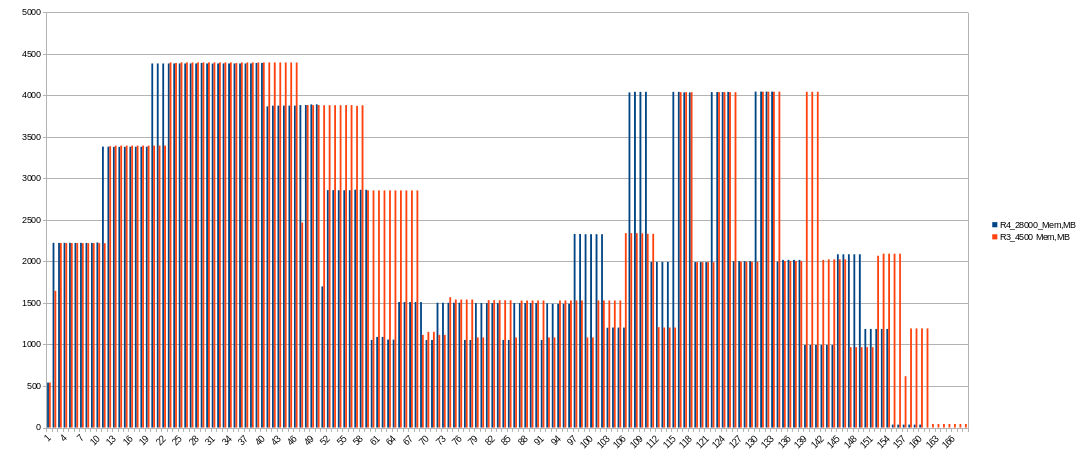
It’s really faster than 2 threads for about 1380 seconds (~23 minutes). First phase is shorter, other phases the same as 2 threads. Now lets look inside…
Memory usage decreased to 4392 MiB at peak at first phase and a little bit for second one.
Temporary drive space usage is a same as 2 threads, but shorter in time.
At first phase CPU usage is greater, but not at 400% as expected. (This is average values per minute, I would check it later).
It seems to be optimal parameters for me is -r 3 -b 4500 for 128 buckets
Great info @gladanimal, sorry for my noobness, do you mean -r 3 is for 3 threads and -b 4500 is for 4500MB RAM buffer?
No, extra thread efficiency is diminishing with every thread added !1 thread 97%, 2 threads 150% :::). Even 6 threads will just see you around 280%.
Exactly. I mean exactly this
Thanks for info, would test it
Thanks for this testing (number’s) .
Can you test with more threads, like 12 -16 maybe.
I’d run -k 32 -r 3 -b 4500 -u 128
Plot size is: 32
Buffer size is: 4500MiB
Using 128 buckets
Using 3 threads of stripe size 65536
Using optimized chiapos
Overall:
Time for phase 1 = 4108.402 seconds. CPU (201.390%)
Time for phase 2 = 2186.909 seconds. CPU (90.780%)
Total compress table time: 643.945 seconds. CPU (95.100%)
Time for phase 4 = 289.450 seconds. CPU (102.300%)
Total time = 9693.975 seconds. CPU (153.760%)
Total time is greater for 300 seconds. So average CPU usage is so close but it is average.
Comparsion with previous (4 threads, 28000 MiB RAM). Amount of used memory looks really the same.
It’s OK! 4500 MiB is enough for 128 buckets with 3 and 4 threads.
Matches the previous test.
CPU usage average is lower, so using 4 threads is better for phase 1 than 3 threads.
Using 4 threads and 4500 MiB of RAM is good enough for k=32 and 128 buckets.
Plot size is: 32
Buffer size is: 28000MiB
Using 2 threads of stripe size 65536
Using optimized chiapos
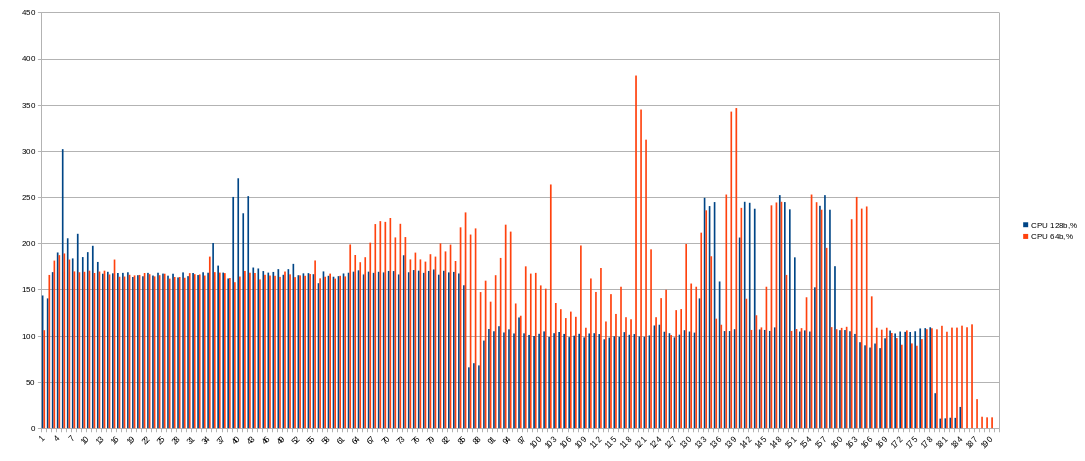
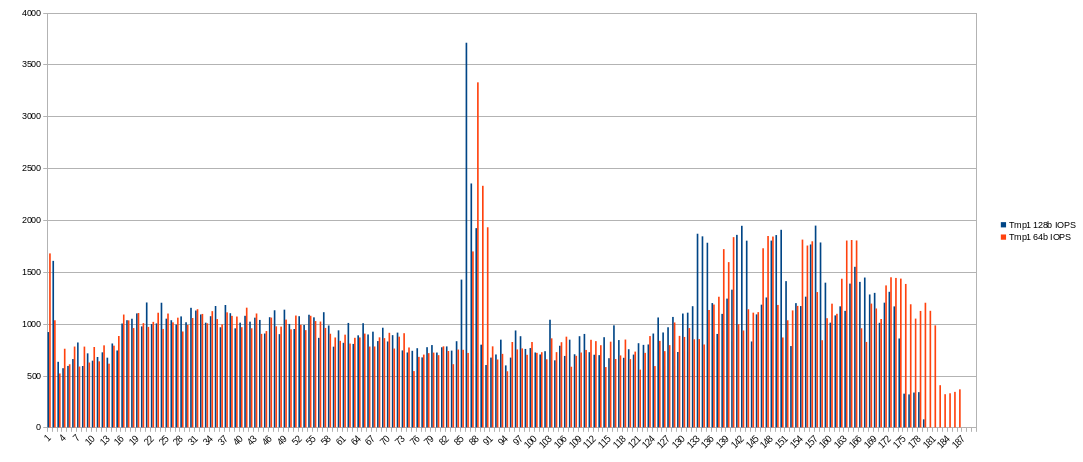
128 buckets (blue) overall
Time for phase 1 = 5074.508 seconds. CPU (162.030%)
Time for phase 2 = 2212.331 seconds. CPU (90.880%)
Time for phase 3 = 3109.913 seconds. CPU (139.740%)
Time for phase 4 = 284.687 seconds. CPU (102.400%)
Total time = 10681.442 seconds. CPU (139.220%)
64 buckets (red) overall
Time for phase 1 = 5216.343 seconds. CPU (160.510%)
Time for phase 2 = 2314.673 seconds. CPU (90.890%)
Time for phase 3 = 3341.300 seconds. CPU (139.510%)
Time for phase 4 = 309.550 seconds. CPU (102.170%)
Total time = 11181.868 seconds. CPU (138.210%)
I didn’t find reasons to use 64 buckets (for 2 threads; will try 4 threads later). Just higher CPU and memory usage and 500 seconds slower. No profits found yet.
Do you plan to run these with optimized chiapos or the vanilla client? (the former is probably better for you while the latter is more usefull for the community).
I’d updated test schedule ))
Btw, are the resulting plots from the optimized client smaller in size? (do they drop table 1?)
Plots are completely the same