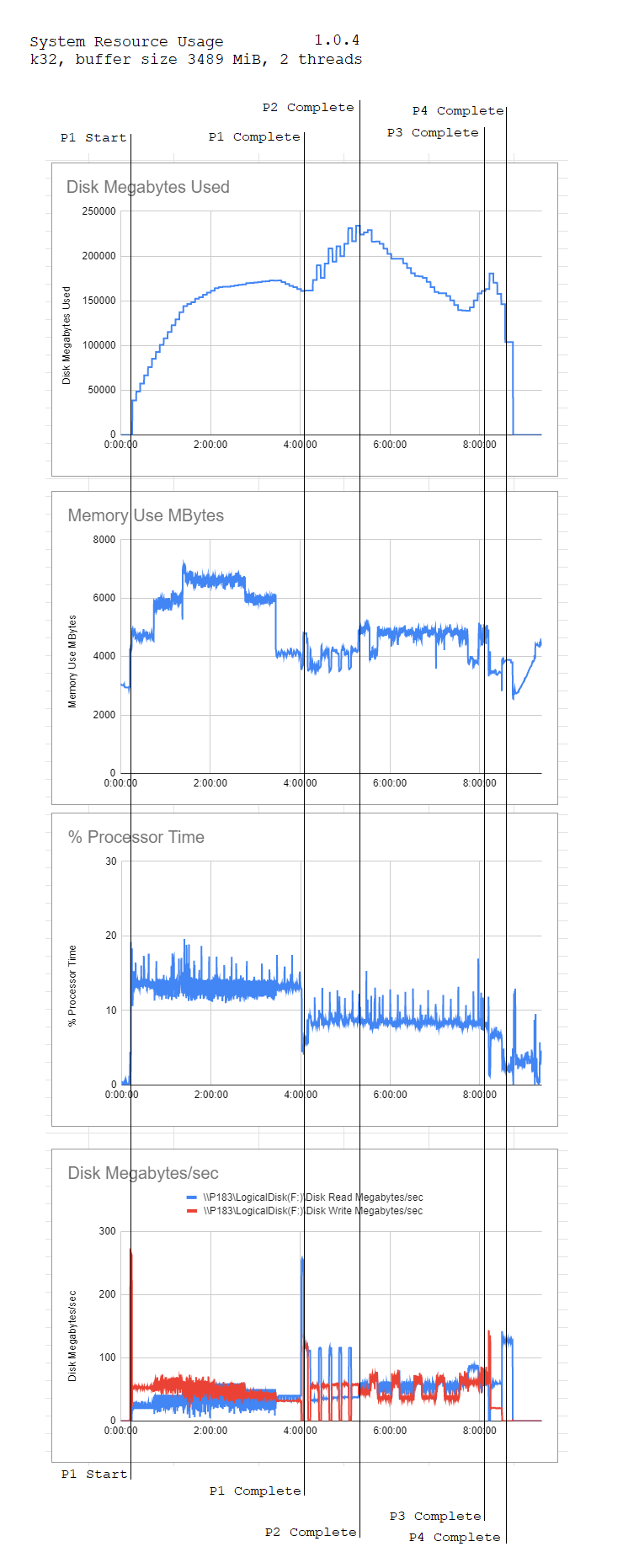
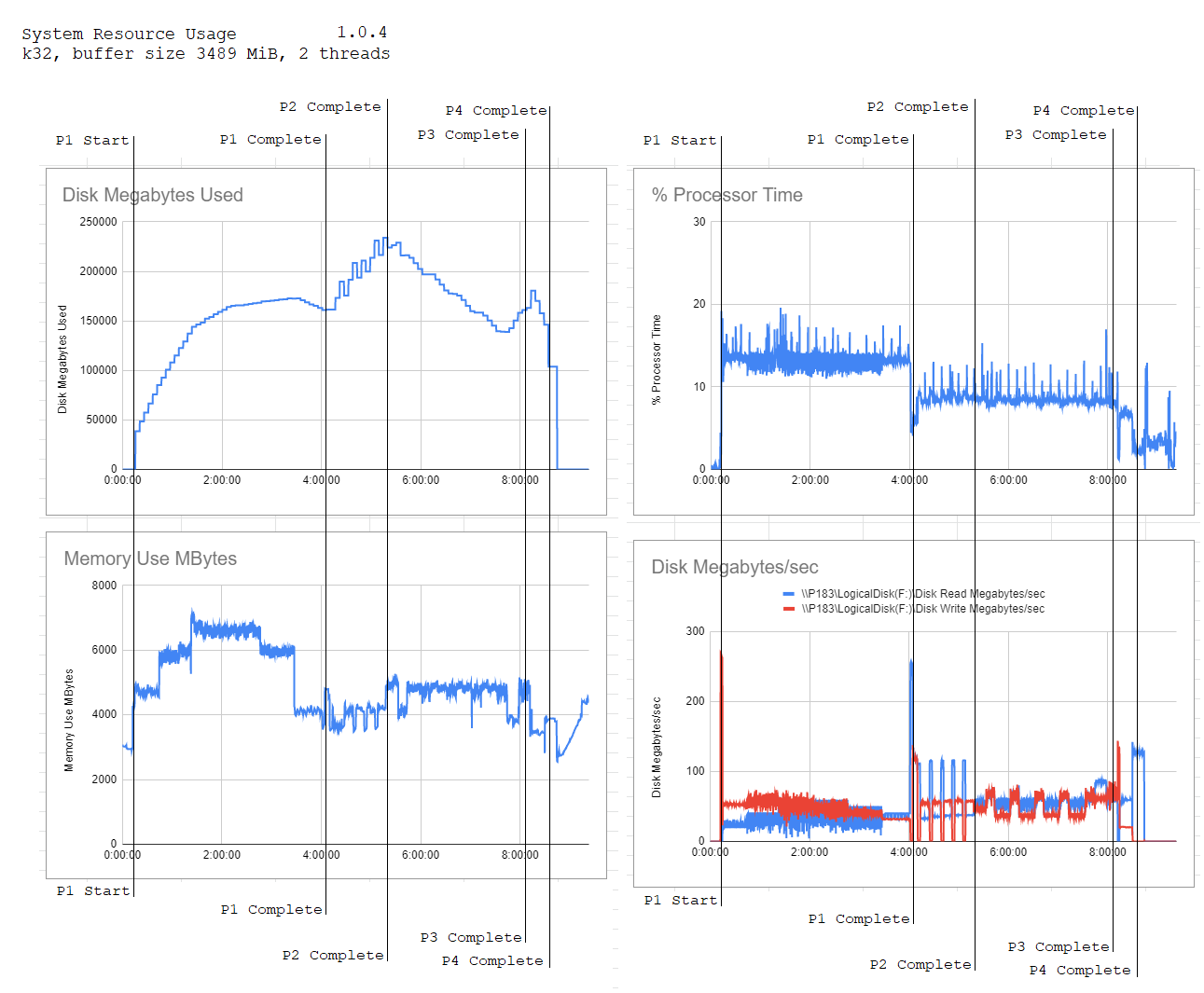
This is such a great resource! Note that it is “only” 2 threads, but 2 threads is the default.
It indicates to me you that you want to stagger at about the 55% point right after P2 completes, during P3?
In the past I compared giving plots a lot of memory and it barely improved plot times, and others have reported that going to 6 threads also barely improves plot times. I need to test two things:
Yeah these are super helpful visuals. I think in general, despite Chia’s main GUI being really really nice, there is a lot of opportunity for someone to build software with strong UX for managing plotting operations. Plotman is great, but it’s still very technical as a CLI solution.
I’m running my plots with 2 threads each, 3400MiB of RAM, and staggered start time of 1hr each. Phase 1 generally runs for 12000 seconds or so. I think I can benefit from stretching out that staggering a bit more to reduce the number of simultaneous Phase 1 plots.
I did successfully manage to run 4 plots at once on a 1TB NVME last night, so that was good. Made my plot times go from ~27000 seconds/plot to about ~32000 seconds/plot, but since it was 4 at once rather than 3, it looks like I can get about 1.2 more plots/day out of that setup, so I’m going to keep fiddling with that setup this week to squeeze out as much as I can from that little NUC.
I’m gonna go ahead and test this now because I really need to know. Testbed machine is Surface Pro 7 w/ i7-1065g7 CPU, plotting to (very fast!) Orico 20gbps USB enclosure w/ ASM2364 chipset on Samsung 980 Pro 2tb drive.
Default (2t/4gb)
Time for phase 1 = 10777.255 seconds
Time for phase 2 = 4038.702 seconds. CPU (88.930%) Tue Apr 20 01:09:14 2021
Time for phase 3 = 7548.655 seconds. CPU (91.340%) Tue Apr 20 03:15:03 2021
Time for phase 4 = 566.737 seconds. CPU (83.320%) Tue Apr 20 03:24:30 2021
Total time = 22931.356 seconds. CPU (114.160%) Tue Apr 20 03:24:30 2021
22931s, or 6:22
+threads (4t/4gb)
Time for phase 1 = 7871.510 seconds. CPU (196.580%) Tue Apr 20 09:22:35 2021
Time for phase 2 = 3764.802 seconds. CPU (88.670%) Tue Apr 20 10:25:19 2021
Time for phase 3 = 7541.225 seconds. CPU (91.380%) Tue Apr 20 12:31:01 2021
Time for phase 4 = 561.317 seconds. CPU (83.700%) Tue Apr 20 12:40:22 2021
Total time = 19738.871 seconds. CPU (132.600%) Tue Apr 20 12:40:22 2021
19739s or 5:29
+mem (2t/8gb)
Time for phase 1 = 10719.412 seconds. CPU (143.690%) Tue Apr 20 15:47:48 2021
Time for phase 2 = 3801.722 seconds. CPU (88.280%) Tue Apr 20 16:51:10 2021
Time for phase 3 = 7546.705 seconds. CPU (90.940%) Tue Apr 20 18:56:56 2021
Time for phase 4 = 584.979 seconds. CPU (84.160%) Tue Apr 20 19:06:41 2021
22653s or 6:18
+threads +mem (4t/8gb)
Time for phase 1 = 8557.745 seconds. CPU (200.080%) Tue Apr 20 22:29:29 2021
Time for phase 2 = 3755.357 seconds. CPU (87.410%) Tue Apr 20 23:32:04 2021
Time for phase 3 = 7519.871 seconds. CPU (90.850%) Wed Apr 21 01:37:24 2021
Time for phase 4 = 561.806 seconds. CPU (83.230%) Wed Apr 21 01:46:45 2021
Total time = 20394.802 seconds. CPU (135.840%) Wed Apr 21 01:46:45 2021
20395s or 5:40
Complete! I did 1 plot at a time so there are were other variables… it’s currently doing 23703 seconds with 2 simultaneous 4c/8gb plots, staggered by 4 hours.
Hmm. My data is a bit weird, since the 4t/8gb time is worse than the 4t/4gb time! I can’t explain that!
At any rate, what you can take away from this is the following:
increasing memory barely improves plot time at all (6:22 vs 6:18) so don’t bother with increasing memory. If you have a ton of memory and absolutely nothing else to do with it, sure, but overall you want more cores, not more memory.
increasing from 2 threads to 4 threads improves plot time by about 15 percent!
parallel plotting is definitely the way to go, even on this machine with “only” 4 cores 8 threads, having two staggered plots reduces plot time 20% overall (19739 vs 23703) but you are producing two plots at once instead of just one!
I recommend you stagger at roughly the 55% point when P2 is complete, on this rig that’d be 23703 * 0.55 = 13037 seconds or 3:37.
This is very useful for balancing the load.
Could you advise on the staggering process.
How to set it up using the CLI commands. I’ve read through the Github but have not find one.
I can see that it’s possible to do it manually but if I can out that in PowerShell it would help automating the process.
Not sure how to do it in Powershell, but in Bash/Unix CLI, there’s a sleep Command you can preface any other CLI command with to handle the staggering easily. I’m sure powershell has something comparable.
(The total doesn’t add up to 100 because 1% of time is the setup and shutdown phases of the plot, I think. You can kinda see this on the graph as well; there’s a bit of time before phase 1 starts, and after phase 4 ends.)
Current wisdom as of 1.1.2+ is that the buckets and memory defaults are pretty much optimal; changing those params is highly unlikely to result in any improvements. I can say that my experiments here confirmed that adding memory does almost nothing for plot time.
* this is what the -2 second temp directory is supposed to help with
You wont use 8GB unless you reduce buckets to 64. The memory you specify is the MAX it can use.
If you use 4GB with 64 buckets, you see a lot of QS in the logs as the max buffer memory available is 4GB. However with 64 buckets, it now has a max buffer of 8GB so a bigger bucket will be processed in memory.
Results from my experiments!
What did you use to for this graph? Command line utils dumping data into log files and made graphs from there or some other monitoring tool?
If Phase 3 is DISK I/O heavy then we should have seaprate NVMes for both temp1 & temp2 instead of having a slower SSD for temp2?
FYI, mem amts for different buckets (rounded): B:128 4GB, B:64 7GB, B:32 13GB. You can use rounded GBs rather than specific because the process won’t use more than it requires, and it’s easier to type (lazy) over and over when doing plot profiles. However, these amts keep QS down to the absolute minimum. I don’t know why it still does a QS occasionally even w/enough memory.
But, regardless of buckets/memory used, plotting time results stay within same range, sadly.
Some QS are mandatory and are ALWAYS done! I believe these come in handy when doing massive parallel plotting and reducing IO load on the NVMes.
Bucket size advantage might only be visible when we saturate the IO of NVMe drives.
Does anyone know how to get this output? I think he just did it in windows but I’m having a hard time finding the right parameters to set it up.
I’m just wondering about the graph with the disk write data. Except for a few peaks, he never gets more than like 80 MB/s. But I’m seeing up to 150 MB/s quite often, with peak at start of phase 1 of 350 MB/s