Try 32 / 4 threads / 128 buckets / 4500 ram. I suggest it gives you some more speed
1 Like
Don’t you have difficulties with RAM with this “speed” hack? It seems to use even 50% more per plot than official chiapos
I would like to try it but after pool plotting comes out. Are we gonna need a new version of this when pool plotting comes out?
It uses same the memory. I checked this.
Are you sure?
I have 2 exactly the same plotters, with exactly the same hardware, os, swar config etc. The plotter with “optimized” chiapos was failing multiple plots due to RAM overload, while the plotter with “official” pos is working fine. I’ve changed # of threads from 8 to 4 on optimized chiapos to see wheter this is an issue, but even now it is clearly visible that plots use way more RAM:
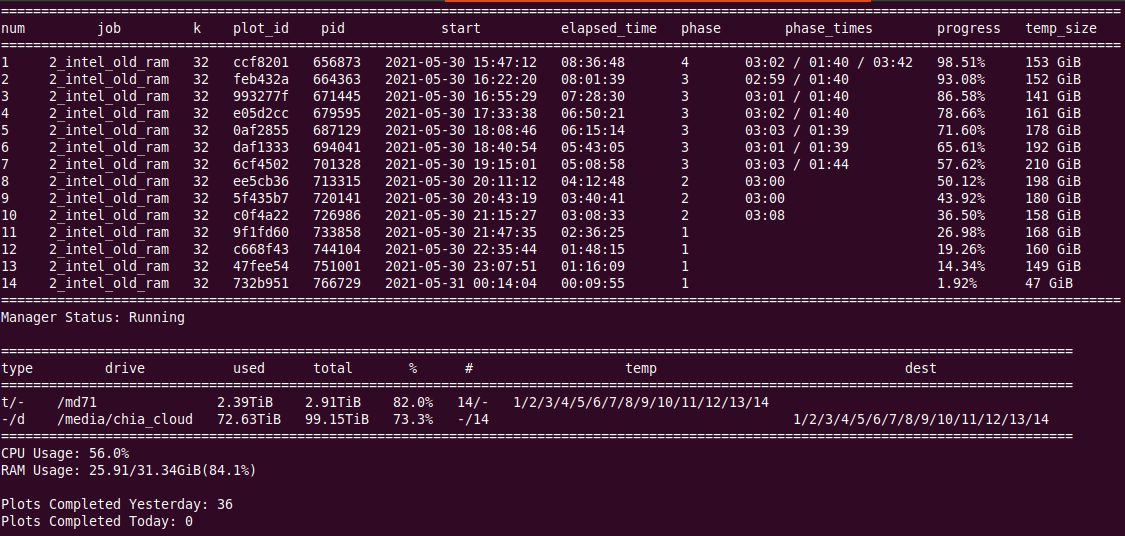
“Official” chiapos, 8 threads, 14 plots in parallel, 89% RAM
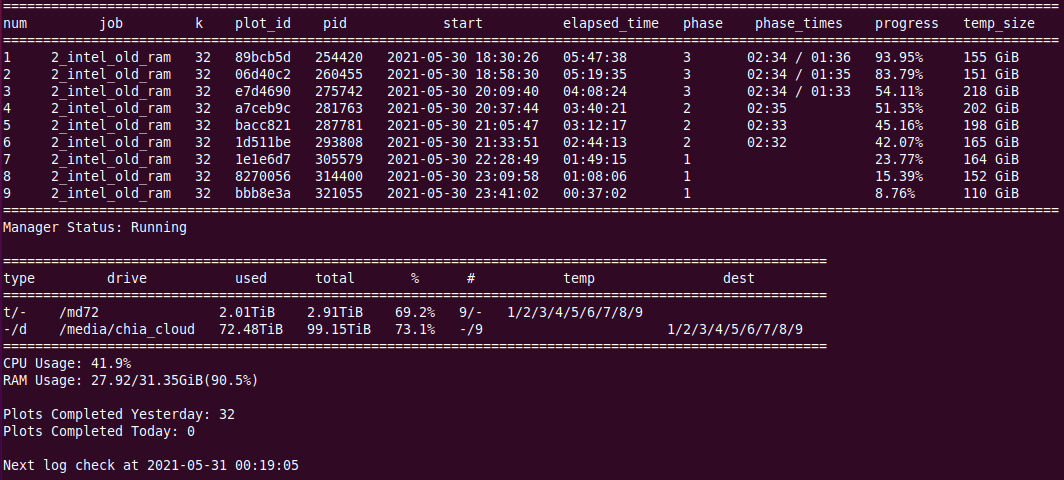
“Optimized” chiapos, 4 threads, 9 plots in parallel, 91% RAM
I verified in “top” that there are no other processes running. Any ideas what can be the issue?
I found 4 threads uses less memory than 2 (in average). Will check for 8 threads.
And I digged his sourcecode. He really added asyc I/O in third phase.
TBH I believe that your tests (which are really impressive, I adore the scientific approach!) confirm my assumptions…
Here you are showing that without optimized chia 1 plot takes maximum 3200 MB: Plotting process measurements - #4 by gladanimal
Here we see results for optimized chia which tops RAM at 4892 MB:
I understand that it is different hardware, but the impact shouldn’t be so huge. Also, in the first mentioned test you used 1 thread, and in the second two, and as we know even from your previous post, higher number of threads should rather decrease need for RAM.
And these tests are almost exactly in line with my “guestimate” observations that optimized chiapos uses in the worst moment 50% more RAM
Hello, I followed your chain. Your install instructions using the .whl file in the venv worked well. With this file I am seeing a 15% improvement in plotting. But reddit user Deep-Channel also combined his optimizations into the chiapos branch. With the improvements added together, 25% speed increase across the board.
However, the .whl file Deep-Channel developed works with plotting scripts like Plotman, but I don’t think the Chiapos combined file works without changing the plotting software.
Is this what you think too?
What does the 32 stand for? I am currently using 8 threads. I have the xcess ram. I wonder if 12 threads would do better
I’ve been trying this improved plotter too. Until now I had 5 parallel plots running on old hardware with 5 old HDDs. The system has 16GB RAM and was usually OK, every other day one of the plots failed due to being out of memory - all in all fine and still faster than 4 parallel plots. With the optimized chia plotter the system wasn’t even able to do 4 parallel plots and the one plot that actually finished took an hour longer than the official chiapos 1.0.2, so systems with limited memory and HDDs for plotting may just be out of luck with this one. I talked to other people with more memory headroom and NVMe plotting drives who had comparable speed improvements like mentioned here and on Reddit, so it does seem to work.
1 Like
No-no-no! It takes maximum 3200MB because default buffer size (3389MB) was used in this test.
And here I set buffer size to 28000MB to see how much of it can be utilized.
This is not optimized chiapos affection.
It could be many reasons you see this difference of memory consumption, not only chiapos impact.
As you can see, memory usage is not leaner dependency.
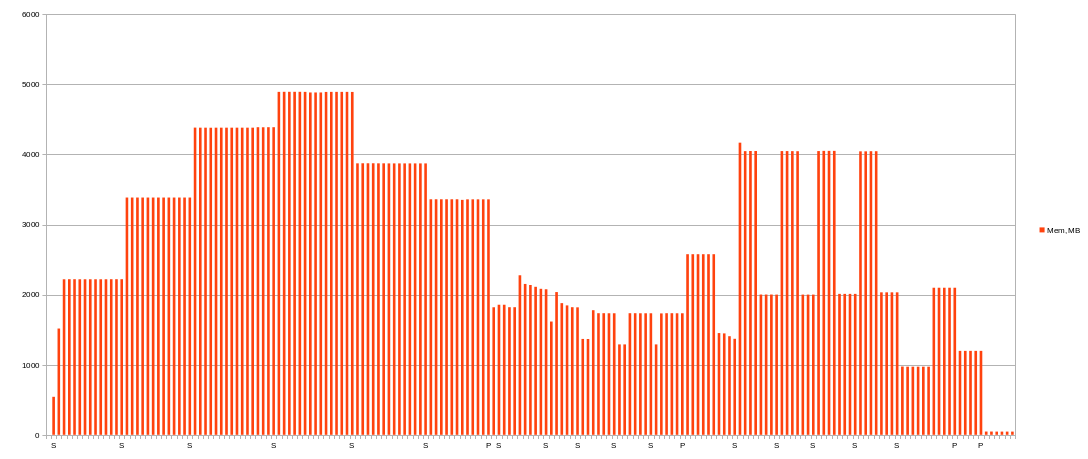
“used memory” can vary depending on process step (more than 50% lower of maximum). If you fire several plots in parallel, you will have some “random” memory usage. In case of 5 parallels (assume 5GB limil per one) you will get total about 25GB used in worst case and average about 15GB for most of time. And it depends on start time of each seeding.
So your optimized queue becomes unoptimized when you applied optimized chiapos because of seeding time becomes shorter and whole picture changed.
Now some calculations:
- “Official” chiapos, 8 threads, 14 plots in parallel, 89% RAM, 29.91GB used - this is average 1895MiB per 1 plot
- “Optimized” chiapos, 4 threads, 9 plots in parallel, 91% RAM, 27.92GB used - this is average 3176MiB per 1 plot
I can’t say there is “more ram” here. But I can say tune you queue optimization when you change something
P.S. Thank you for idea to accurately test this case.
2 Likes
K size of 32
Try to set -b 2800. It will prevent outing of memory and allow you to seed 5 plots in parallel. It would be a little bit slower, but allows you to run 5 plots without exceptions. 
So I was happy with my 1 plot speed (maybe to excited) and I started 6 plots r4 b4000 with a stagger of 30 min ( I’ve always done 60 min ) and all when to hell LOL. The first plot took 8.47!
Back to the drawing board
1 Like
I would really like to use this but still struggling to get it working. Can someone provide me a how to for dummies (I sure feel like one at this point). I would like to set it up using Swar. So I installed based on cojarbi instructions.
Dependencies
Git > sudo apt install git -y
cmake > https://www.fosslinux.com/38392/how-to-install-cmake-on-ubuntu.htm
Build essential > sudo apt-get install -y build-essential
Pip > pip install -U pip setuptools
Pybind11 > pip install pybind11
Once all the above is done follow to compile this combined version
Process
git clone GitHub - pechy/chiapos: Chia Proof of Space library, fork for optimized plotting. If you want to support the development, donations are welcome: xch1lnnarj8tzx56fwe4gnds8365kj896a9tq08yt8pwsgqxczpqdkvs8n8dua
NOTE: The URL provided is a 404.
Then
Build and Compile
mkdir -p build && cd build
cmake ../
cmake --build . -- -j 6
This is what I see in the build directory:
chiapos.cpython-38-x86_64-linux-gnu.so
cmake_install.cmake
libfse.a
ProofOfSpace
CMakeCache.txt
CTestTestfile.cmake
libuint128.a
RunTests
CMakeFiles
_deps
Makefile
Then modified Swar config for executable:
chia_location: /opt/chiapos/build/ProofOfSpace
It just starts a defunct process. One thing I would like to clarify is whether or not Swar can pass the public keys to this process or if you have to import ca, etc. and somehow use chia-blockchain.
I am missing the link between chia-blockchain and using ProofOfSpace.
Can I just use ProofOfSpace with Swar to plot?
I am obviously missing something fundamental here. Please help.
using Ubuntu not windows anything
Can confirm they use up to 5gb ram with both tweaks(pechy/Chiapos)and average over 3gb up from 2gb ish.
Haven’t tried setting lower than 4000 to see if it’s possible to limit it a little but at that point might as well run stock. Time to get more ram!
iam heavily ram starved so have to see what’s faster after cutting down on parallel plots(from 100 to 75ish) the improvements look huge though.
what difference between main branch and combined? combined build only elf for change chia binary?
My experience is that it makes the workload easier to optimize. You don’t need to get the number of parallel jobs exactly right to utilize 100% of the CPU… But if you were already, you don’t gain anything and it uses more ram. I still run it on some of my plotters. I can do 5:30 plots on enterprise HDDs on a 3600 with it hehe.
1 Like
Don’t edit the Swar config, this needs to point to the Chia executable. You had it correct up until that point.
You were close to installing the optimized chiapos! You built the python library for the optimized version, but then you didn’t tell the plotter that it should switch from the original.
Swar’s plot manager doesn’t actually create plots, it just directs the Chia plotter to start doing its thing. And to do so, Swar’s needs to know how to find it. Additionally, the chiapos library isn’t the “plotter” exactly, though it is a main component, so pointing Swar’s to it doesn’t work (as you found).
Here’s the last few steps:
After building the optimized chiapos, go into the chia-blockchain directory, activate the venv, and open Setup.py with a text editor. Change the part that says “chiapos==1.0.3” (or whatever) to just “chiapos”, no equal sign or anything after. Save and close.
Now, back in the chia-blockchain directory (with venv enabled!), and run this command in a terminal:
python Setup.py install
It will modify the Chia executable to use the optimized chiapos instead of the one it came with (because you changed the instructions for how it installs itself by editing Setup.py).
You should see in the stdout where it references “adding chiapos 1.0.2dev to easyinstall” or something, but there’s a lot of output here so the quickest way to really check is to start a plot and look at the plot log. Near the top you’ll see the line:
Using optimized chiapos - d153b19
…right before this one:
Starting phase 1/4:...
Yours may have a different code, I don’t know what it means, but if it says “using optimized chiapos” then it worked.
If you don’t see “Using optimized chiapos” then double check everything else that ever happened before this moment in time.
To revert to the official chapos (or “uninstall” the optimized one) either delete the chia-blockchain dir and re-clone, or follow the official blockchain “update” instructions.
Happy multithreading!
Oh, and the github repo you linked doesn’t 404 anymore.
2 Likes