I don’t have any NAS, just 1 farmer and then the plots distributed over several servers (each with a harvester) connected via LAN. It’s worked well for several months with rewards matching or slightly exceeding expected rewards. The only thing that changed over the last few days was that I added some additional drives to my JBODs, but I don’t see how that could cause issues. I’m sure there are people farming way more plots than I am successfully.
Do you store your plots on your farming system or do you just farm and nothing else? Because you probably have it backwards. You want all the plots on the farmer for quick access to the plots and you want to be plotting on the servers. Don’t go farming via one system and trying to access the plots over the network. Too much added latency IMO.
Ah, that part you left out. You have a NAS. Are you farming/harvesting those plots with the Full Node that is having the problem?
Also, are all your plots on one NAS or spread across multiple? Are they in one folder or several? If several, how many plots per folder?
I have this situation:
- server with Full Node and about 1900 textures
- NAS with RAID0 paired disks and cache acceleration, about 4000 frames
- server to plot with 12 full units and shared with the full node
- 3 workstations for plotting alone and sending plots to NAS
All connected in dual 10GB
On the server I have about 150 frames per folder, on the NAS about 300
So you have at least two remote repositories (the NAS with 4000 plots and a server with 12 full units [I assume you mean 12 full drives])
When you say textures, frames and units, it is like you are talking in code. What we need to know is how many plots you have an where they are.
If you have multiple remote repositories with that many plots being farmed by one node, that is a problem and will cause the issue you are having. See what worked for me in the post below.
Unfortunately I use the translator and some words may not be well understood.
You therefore recommend using multiple harvesters even on the same machine, each with a not too high amount of folders.
How can this be managed without creating conflicts? What configurations need to be adopted?
Thanks for your explanations, very generous of you
What I found is a harvester for each remote system. And all of them can be run on the same computer if you just have them running in a VM environment. I think the issue is that when the harvester needs to jump from one remote connection to another, it slows down. So if the harvester only needs to monitor one system (one remote connection), it is fine. I don’t even think the number of plots matters. Just don’t put them all in one folder. I have 1160 plots on one NAS and it is harvested fine. But I have 8 different folders with 145 plots per folder.
I’ve been hesitant to daisy-chain a bunch of JBODs to my farmer due to warnings I’ve seen about lookup times and other things that can go wrong, but might be worth giving it a try since right now nothing is working.
I try to do as suggested and update
I moved my main farmer to another machine and am going to start daisy-chaining jbods, but so far, the new farmer is looking much better. No idea what happened to the old farmer but looks like it’s toast. Even the remote harvesters are now mostly keeping up with challenges.
It’s a pain, but if you’re running into similar issues it might be worth trying another machine as the primary farmer.
Today after a full day of work I created 1 harvester for each server that checks its local disks, and with difficulty and satisfaction also a linux harvester installed on NAS that checks its own disks.
I’m having extremely better overall response times than before.
Unfortunately the problem was really the NAS … now I cross my fingers and see if the situation remains stable …
It is really not advised to have a bunch of plotters and 1 farmer and have that 1 farmer farm off of the drives in the plotter. It is not even advised to have the single farmer and multiple plotters where you plot and store to a temp drive then move the plots to a local disc array or RAID on the plotters then farm to the array on the plotters from the single farmer.
It is best advised to have your farmer server set up as a NAS and all of your storage on the farmer and store your plots directly on the farmer.
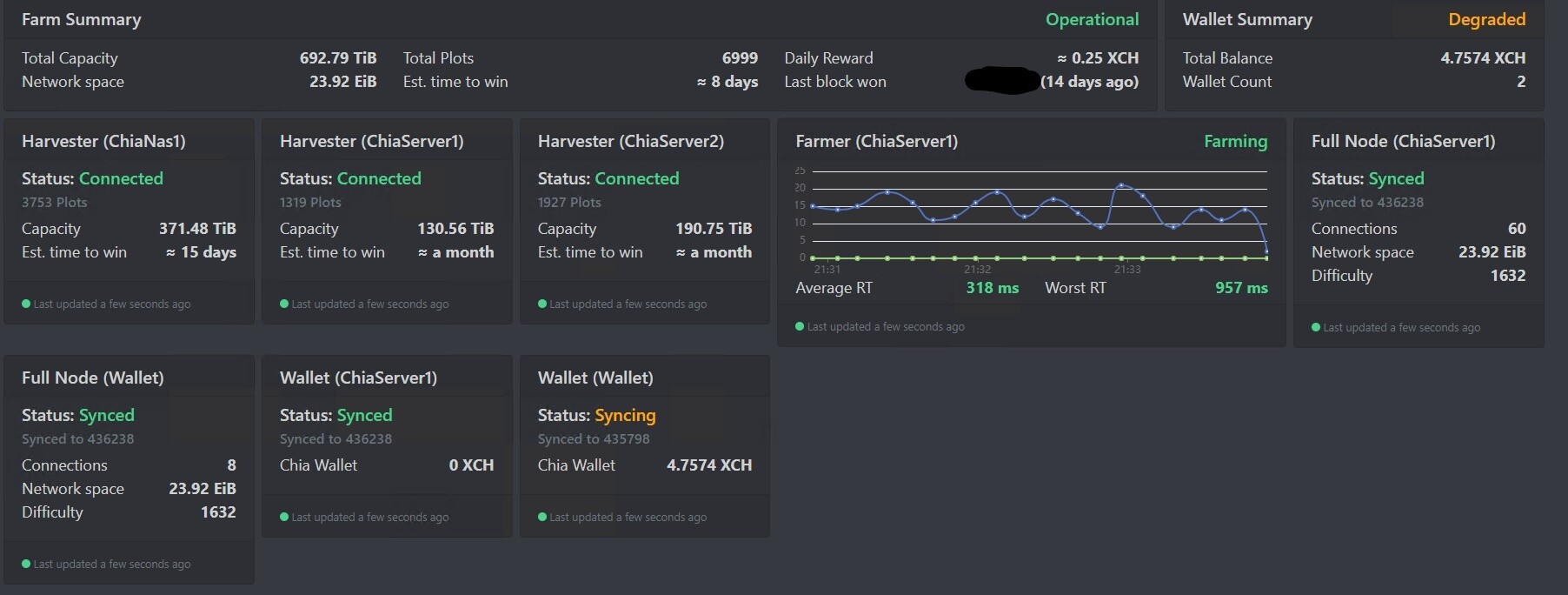
I hope the balance shown is not everything you have earned with that many plots. If so, you have definitely been messing up (missing a lot of challenges). You would be earning .22 XCH per day on Hpool. And the Hpool client has no problem whatsoever farming all plots from one client. I farm 3 different NAS devices from one Hpool client.
The overall gain so far is 10 xch, but I haven’t won any challenges for 17 days.
Can you confirm that the configuration I have adopted is effective? each harvester grows their own wefts locally and connects to the full node?
At this moment everything seems to be going well, the 2 reapers are connected and the response times for each harvester are very good … Should I sit quietly and wait for the winning blocks?
What’s your estimated time to farm a block?
always been 7 days from the start
So you’re creating more new plots to match network growth?
Edit.
Have a look at running chia dog maybe.
But if it was working, and you didn’t mess with it.
yes i currently have 1150tb available and i’m almost completing the filling.
But now I haven’t won many days … I don’t understand …